(Big Transfer )BiT

/*! elementor - v3.17.0 - 08-11-2023 */
.elementor-widget-image{text-align:center}.elementor-widget-image a{display:inline-block}.elementor-widget-image a img[src$=".svg"]{width:48px}.elementor-widget-image img{vertical-align:middle;display:inline-block}  /*! elementor - v3.17.0 - 08-11-2023 */
.elementor-heading-title{padding:0;margin:0;line-height:1}.elementor-widget-heading .elementor-heading-title[class*=elementor-size-]>a{color:inherit;font-size:inherit;line-height:inherit}.elementor-widget-heading .elementor-heading-title.elementor-size-small{font-size:15px}.elementor-widget-heading .elementor-heading-title.elementor-size-medium{font-size:19px}.elementor-widget-heading .elementor-heading-title.elementor-size-large{font-size:29px}.elementor-widget-heading .elementor-heading-title.elementor-size-xl{font-size:39px}.elementor-widget-heading .elementor-heading-title.elementor-size-xxl{font-size:59px}
/*! elementor - v3.17.0 - 08-11-2023 */
.elementor-heading-title{padding:0;margin:0;line-height:1}.elementor-widget-heading .elementor-heading-title[class*=elementor-size-]>a{color:inherit;font-size:inherit;line-height:inherit}.elementor-widget-heading .elementor-heading-title.elementor-size-small{font-size:15px}.elementor-widget-heading .elementor-heading-title.elementor-size-medium{font-size:19px}.elementor-widget-heading .elementor-heading-title.elementor-size-large{font-size:29px}.elementor-widget-heading .elementor-heading-title.elementor-size-xl{font-size:39px}.elementor-widget-heading .elementor-heading-title.elementor-size-xxl{font-size:59px}
(Big Transfer )BiT
تاریخچه BiT
روش Big Transfer (BiT) در سال 2020 توسط گروه پژوهشی گوگل ارائه شد. این روش بر اساس مدل ترنسفورمر بنا شده است که در سال 2017 توسط Attention Is All You Need مطرح شد. مدل ترنسفورمر در اصل برای مسائل پردازش زبان طراحی شده بود اما موفقیت آن در مسایل سختتر تصویری مانند دستهبندی تصویر عمیق و تشخیص تصویر باعث شد که به طور گسترده در این حوزه استفاده شود.
BiT به عنوان یک توسعه از مدل ترنسفورمر به منظور تسهیل یادگیری نمایش بصری توسعه یافته است. مهمترین نوآوری BiT این است که از یادگیری مشترک روی چندین مجموعه داده استفاده میکند. این مجموعههای داده میتوانند شامل دادههای تصویری متنوع و گوناگون باشند، مانند ImageNet، JFT، و COCO و غیره. این جمعیت متنوع از دادههای آموزشی باعث شده تا نمایشی عمومی و کلی از دنیای بصری در BiT شکل بگیرد
مدل BiT به منظور یادگیری نمایش بصری از دادههای برچسبگذاری شده استفاده میکند. اما در طول آموزش، مدل همراه با دادههای برچسبگذاری نشده نیز آموزش میبیند. این روش، به مدل کمک میکند که درک بهتری از اطلاعات بصری کسب کند. هرچه تعداد دادههای آموزشی بیشتر شود، مدل BiT نیز بهتر خواهد شد.
با استفاده از تکنیک هدایت تشخیصی (discriminative fine-tuning)، BiT توانایی انتقال یادگیری را از دادههای آموزشی منبع به دادههای آموزشی هدف فراهم میکند. به این معنی که بعد از آموزش بر روی مجموعههای آموزشی منبع، مدل بر روی دادههای آموزشی هدف دقت بیشتری دارد و به نتیجه بهتری میرسد
تاکنون، مقالات تکمیلی و ایجاد نگاشتهای بیشتر از این روش منتشر شده است و به استفاده از BiT در حوزههای مختلف مانند تشخیص تصویر، حلقه بسته برآورده کردن و یادگیری تقویتی پرداخته شده است
مدل یادگیری BiT
Big Transfer یک مدل یادگیری نمایش (Representation Learning) عمومی برای تصاویر است که توسط تیم Google Brain ارائه شده است. این مدل به دنبال ایجاد یک نمایش عمیق و کلی برای تصاویر بوده و در واقعیت به عنوان یک مدل پیشآموزش دیده شده (pre-trained) برای وظایف بینایی ماشین مورد استفاده قرار گرفته است.
معمولاً مدلهای پیشآموزش دیده شده برای وظایف خاصی مثل تشخیص اشیاء، دستهبندی تصاویر و یا ترجمه متون آموزش داده میشوند. اما Big Transfer با تمرکز بر تصاویر و وظایف بینایی، سعی در ایجاد نمایش عمومی برای تصاویر دارد. این نمایش عمومی به معنای آن است که مدل برای تصاویر از دامنههای گستردهتری آموزش دیده شده و قابلیت انتقال یادگیری به وظایف مختلف بینایی را دارد.
Big Transfer بر اساس معماری Vision Transformer (ViT) ساخته شده است که از ترنسفر لرنینگ (Transfer Learning) برای یادگیری اولیه تصاویر استفاده میکند. این معماری توسط ترکیب بلوکهای ترنسفر (Transformer blocks) به ایجاد نمایشهای ژنرال برای تصاویر میپردازد.
استفاده از مدلهای پیشآموزش دیده شده مانند Big Transfer میتواند در وظایف مختلفی مانند تصویربرداری پزشکی، تشخیص شیء در تصاویر ماهوارهای، یا سایر وظایف مربوط به پردازش تصویر مورد استفاده قرار گیرد.
کاربرد های BiT
در حوزه تشخیص تصویر و بینایی ماشین میتواند در مثالهای زیر استفاده شود:
۱. تشخیص و طبقهبندی اشیاء: BiT میتواند به کمک روشهای نمایش بصری عمیق، شیوههای تصویربرداری و پیشپردازش مدلهای تشخیص اشیاء را بهبود بخشد. به عنوان مثال، مدل BiT میتواند اشیاء را تشخیص دهد و آنها را در دستهبندیهای مختلف قرار دهد مانند خودروها، حیوانات، میوهها و غیره.
۲. تشخیص چهره: BiT قادر است تا چهرهها را تشخیص داده و ویژگیهای آنها را استخراج کند. این ویژگیها میتوانند در کاربردهایی مانند تشخیص چهره در تصاویر یا تحلیل هویت استفاده شوند.
۳. تشخیص وضعیت و فعالیت: BiT قابل استفاده است برای تشخیص وضعیت و فعالیت افراد و اشیاء در تصاویر. این اطلاعات میتوانند در شناسایی اشخاص خطرناک، مراقبت از افراد سالمند یا کودکان و غیره مفید باشند.
۴. تشخیص تصاویر پزشکی: BiT میتواند در تشخیص بیماریها و آسیبها در تصاویر پزشکی مانند تصاویر MRI، CT، پرتودرمانی و غیره مورد استفاده قرار گیرد. این روش میتواند به شناسایی مشکلات سلامتی بیماران و همچنین بهبود دقت تشخیص کمک کند.
۵. خودرانسازی: BiT میتواند در سیستمهای خودران مانند خودروهای خودران، رباتهای خودران و دیگر سیستمهای مشابه استفاده شود. این روش میتواند به مدلهای خودران کمک کرده و بهبود دقت آنها را ایجاد کند.
یک مقاله در رابطه با (BiT: Exploring Large-Scale Pre-training for Computer Vision)
پیش آموزش
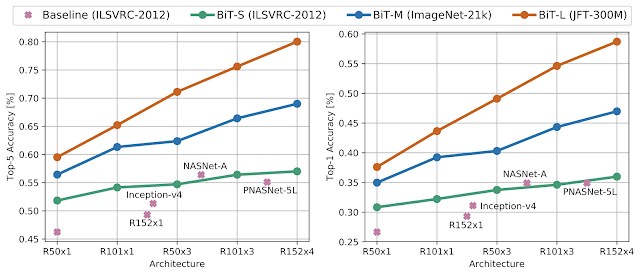
برای بررسی اثر مقیاس داده، طرحی را برای پیش آموزش ویژگیهای عمومی با استفاده از مجموعه دادههای تصویری با مقیاسی بالاتر از استاندارد در نظر میگیریم. با این مجموعه دادهها، رویکردهای متداولی مثل نرمال سازی فعالسازیها و وزنها، پهنای و عمق مدل و برنامههای آموزش را بررسی میکنیم. نتایج نشان میدهند که برای استفاده موثر از داده بیشتر، باید ظرفیت مدل را همزمان با آن افزایش داد. همچنین، مشاهده میشود که مدت آموزش نقش کلیدی در عملکرد دارد، بنابراین باید برنامه آموزش را با استفاده از داده جدید تطبیق دهیم.
یک مشاهده مهم دیگر این است که تعویض نرمالسازی دسته بندی (BN) با نرمالسازی گروهی (GN) برای پیشآموزش در مقیاس بزرگ مفید است. GN بدون وابستگی به دمای فعلی واریانس در هر بسته را محاسبه میکند. این تغییرات میتوانند کمک کننده باشند تا بهبودهای قابل توجهی را در عملکرد به دست آورد.
انتقال یادگیری
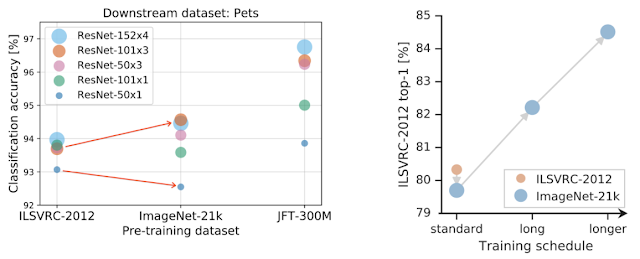
با استفاده از روشهایی که در حوزه زبان توسط BERT استفاده میشود، مدل BiT پیشآموزش یافته را بر روی دادههای مربوط به تسکهای مختلف انتقال میدهیم. این استراتژی ساده با توجه به دانش به دست آمده از جهان تصویر، عملکرد بسیار خوبی ارائه میدهد. در اینجا همچنین روش BiT-HyperRule را پیشنهاد میدهیم که معیارهای بالا برای انتخاب هایپرپارامترها را استفاده میکند. این روش بر روی بیش از ۲۰ تسک متنوع اعمال شده است.
علاوه بر این، نشان میدهیم که با استفاده از جدیدترین تکنیکهای BiT، میتوان عملکرد مدل را بهبود بخشید. به عنوان مثال، استفاده از اندازه و ظرفیت مدل بزرگتر همراه با پیشآموزش بر روی JFT باعث میشود که عملکرد مدل در تصویرهای کم برچسب شده بهبود چشمگیری داشته باشد.

نتیجهگیری
با پیشآموزش روی مقادیر بزرگ از دادههای عمومی، استراتژی انتقال ساده میتواند نتایج قابل توجهی را در دست آورد. از طرف دیگر، با استفاده از دادههای محدود و حتی تصویر تک برچسب، روش BiT توانسته است عملکرد قابل توجهی را در مقایسه با روشهای قبلی به دست آورد. مدل BiT-M، R152x4 را که بر روی ImageNet-21k پیشآموزش داده شده است به همراه کدهای TF2، Jax و PyTorch منتشر میکنیم. همچنین، به آموزههای Hands-on برای استفاده از مدلهای BiT در TensorFlow2 ارجاع میدهیم. امیدواریم که این روش جایگزین مفیدی برای مدلهای ImageNet-پیشآموزش دیدهی معمولی باشد