Music Genre Classification

/*! elementor - v3.17.0 - 08-11-2023 */
.elementor-heading-title{padding:0;margin:0;line-height:1}.elementor-widget-heading .elementor-heading-title[class*=elementor-size-]>a{color:inherit;font-size:inherit;line-height:inherit}.elementor-widget-heading .elementor-heading-title.elementor-size-small{font-size:15px}.elementor-widget-heading .elementor-heading-title.elementor-size-medium{font-size:19px}.elementor-widget-heading .elementor-heading-title.elementor-size-large{font-size:29px}.elementor-widget-heading .elementor-heading-title.elementor-size-xl{font-size:39px}.elementor-widget-heading .elementor-heading-title.elementor-size-xxl{font-size:59px}تشخیص 10 ژانر موسیقی به کمک شبکه RNN
امروزه با پیشرفت هوش مصنوعی و شبکه های عصبی بشر قادر به ساختن ابزار و برنامه های زیادی شده که میتوانند کارهای پویایی که تا به الان توانایی انجام آنها منحصر به هوش ما انسان ها بوده، بر عهده گیرند. از جمله این کارها میتوان به تشخیص یک شی با دیدن عکس آن و یا تشخیص بیماری گیاهان با تماشای تصویر برگ و یا ساقه آنها اشاره کرد. که این امور در حوزه پردازش تصویر و استفاده از تصاویر در شبکه های عصبی هسنتد.
موضوع این پروژه تشخیص 10 نوع موسیقی (Pop, Rock, .... ) توسط یک شبکه عصبی مباشد که در حوزه پردازش صوت توسط شبکه عصبی قرار میگیرد.
آشنایی با صوت :
امواج صوتی در حقیقت امواجی فیزیکی هسنتد که در هوا حرکت میکنند. درست همانطور که شما در کنارهی ساحل میتوانید امواج آب را که به لبه ساحل نزدیک میشوند ببینید، موج های صوتی به همانگونه با حرکت بین ذرات هوا به گوش ما میرسند.
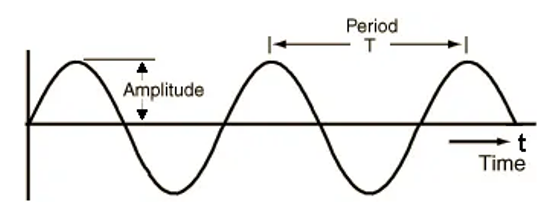
گوش ما با شناسایی اندازه این امواج ( دامنه ) و فاصله آنها با یکدیگر ( طول موج ) این توانایی را به ما میدهد تا آواهای مختلفی از اطرافمان بشنویم.
در عکس زیر یک موج در واحد زمان رسم شده، که Amplitude نشان دهنده دامنه، و Period نشان دهنده طول موج میباشد.
/*! elementor - v3.17.0 - 08-11-2023 */
.elementor-widget-image{text-align:center}.elementor-widget-image a{display:inline-block}.elementor-widget-image a img[src$=".svg"]{width:48px}.elementor-widget-image img{vertical-align:middle;display:inline-block}
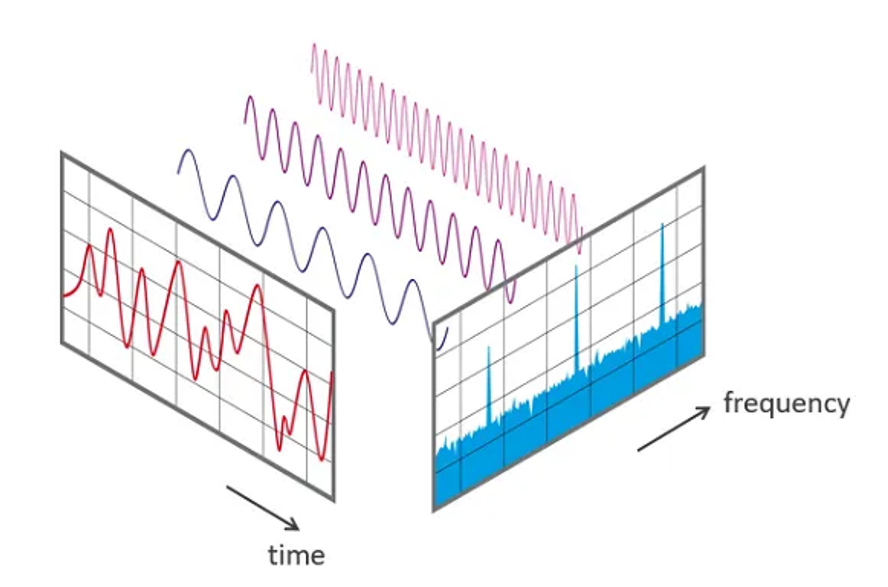
 به تصویر زیر توجه کنید. نمودار سمت چپ که حاوی موجی قرمز رنگ میباشد همان موج پیچیدهایست که از آن سخن میگوییم. ممکن است حرف سادهای مثل "س" موجی به این شکل داشته باشد، که ترکیبی از چند موج پایهایست.
با استفاده از مفهوم سری فوریه امواج تشکیل دهنده این موج را پیدا میکنیم. که در تصویر به شکل 3 موج موازی نمایش داده شدهاند. با توجه به امواج به دست آمده و دامنه و فرکانس آنها ( برعکس طول موج ) نمودار آبی شکل را رسم میکنیم که نشان دهنده فرکانس های استفاده شده در این صوت میشود.
به تصویر زیر توجه کنید. نمودار سمت چپ که حاوی موجی قرمز رنگ میباشد همان موج پیچیدهایست که از آن سخن میگوییم. ممکن است حرف سادهای مثل "س" موجی به این شکل داشته باشد، که ترکیبی از چند موج پایهایست.
با استفاده از مفهوم سری فوریه امواج تشکیل دهنده این موج را پیدا میکنیم. که در تصویر به شکل 3 موج موازی نمایش داده شدهاند. با توجه به امواج به دست آمده و دامنه و فرکانس آنها ( برعکس طول موج ) نمودار آبی شکل را رسم میکنیم که نشان دهنده فرکانس های استفاده شده در این صوت میشود.
 اما نمودار فرکانس ها هم نمیتواند به تنهایی عامل مفیدی برای استفاده درشبکهی ما باشد. چرا که از زمان مستقل است، و فقط به ما نشان میدهد که از هر موج پایهای چه دامنه یا مقداری در صوت ما وجود داشته. خوب چه میتوان کرد؟ ما ترکیبی از این دو نمودار را میخواهیم که از طرفی حاوی فرکانس های (موج های پایهای) موجود باشد، از طرف دیگر زمان شنیده شدن آنها را نیز نمایش دهد. این نمودار اسپکتوگرام نام دارد. در تصویر زیر، اسپکتوگرام یک فایل صوتی ساده ترسیم شده. محور عمودی این نمودار نشان دهنده فرکانس های مختلف، و محور افقی زمان را نمایش میدهد.
اما نمودار فرکانس ها هم نمیتواند به تنهایی عامل مفیدی برای استفاده درشبکهی ما باشد. چرا که از زمان مستقل است، و فقط به ما نشان میدهد که از هر موج پایهای چه دامنه یا مقداری در صوت ما وجود داشته. خوب چه میتوان کرد؟ ما ترکیبی از این دو نمودار را میخواهیم که از طرفی حاوی فرکانس های (موج های پایهای) موجود باشد، از طرف دیگر زمان شنیده شدن آنها را نیز نمایش دهد. این نمودار اسپکتوگرام نام دارد. در تصویر زیر، اسپکتوگرام یک فایل صوتی ساده ترسیم شده. محور عمودی این نمودار نشان دهنده فرکانس های مختلف، و محور افقی زمان را نمایش میدهد.
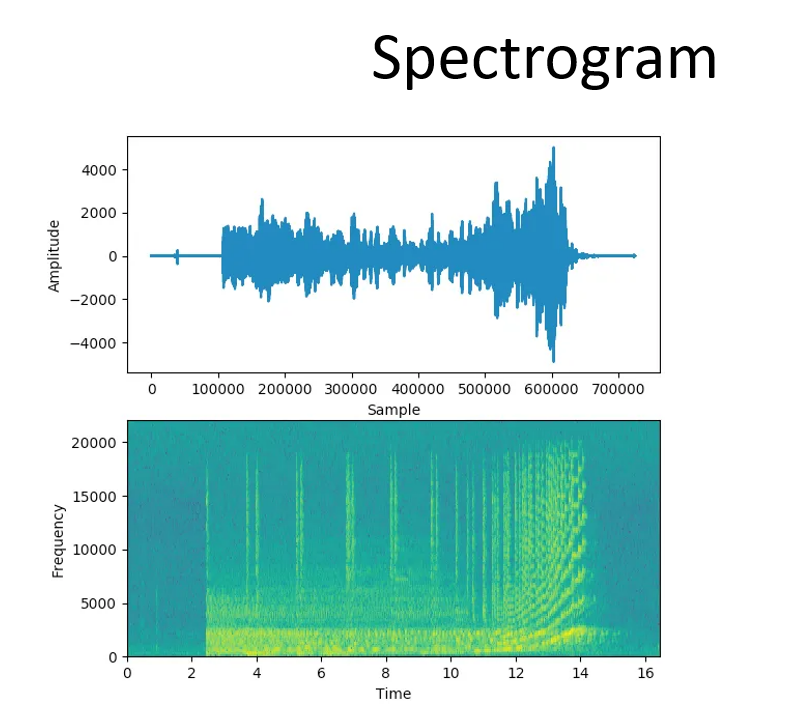 برای رسم اسپکتوگرام یک صوت، ابتدا آنرا به بازه های کوچکی نقسیم میکنیم، سپس با استفاده از مفهوم سری فوریه فرکانس های تشکیل دهنده این قطعات کوچک تر را بدست میاوریم. برای مثال صوت اصلی را هر 256 لحظه یک قطعه کوچک در نظر می گیریم و می گوییم، موج صوت ضبط شده در 256 لحظهی اول حاوی فرکانس های 20، 500، 15000 میباشد که هرچقدر دامنه این فرکانس ها بیشتر باشد، خانهی مربوط به آن روی نمودار حاوی عدد بزرگ تری است و در تصویر اسپکتوگرام نقطهی پر رنگ تری را دیده میشود.
برای رسم اسپکتوگرام یک صوت، ابتدا آنرا به بازه های کوچکی نقسیم میکنیم، سپس با استفاده از مفهوم سری فوریه فرکانس های تشکیل دهنده این قطعات کوچک تر را بدست میاوریم. برای مثال صوت اصلی را هر 256 لحظه یک قطعه کوچک در نظر می گیریم و می گوییم، موج صوت ضبط شده در 256 لحظهی اول حاوی فرکانس های 20، 500، 15000 میباشد که هرچقدر دامنه این فرکانس ها بیشتر باشد، خانهی مربوط به آن روی نمودار حاوی عدد بزرگ تری است و در تصویر اسپکتوگرام نقطهی پر رنگ تری را دیده میشود.
جمع آوری داده و پیش پردازش :
داده های لازم جهت تعلیم شبکه از سایت kaggle.com دانلود، و برای تعلیم شبکه آماده سازی شد. میتوانید با سرچ کردن GTZAN Dataset - Music Genre Classification این دیتاست را در سایت kaggle پیدا کرده و به آن دسترسی داشته باشید. این دیتاست حاوی 10 دسته بندی موسیقی شامل ( Pop, Rock, Classic , ... ) میباشد که از هر دسته بندی 100 موسیقی 30 ثانیهای در فولدر ها موجود میابشد. از آنجایی که برای تشخیص این کلاس ها به شبکهای نسبتا عمیق نیاز داشتیم، و این شبکه عمیق برای تعلیم نیاز به دادههای بیشتری داشت، هر یک از این موسیقی ها را به 3 موسیقی 10 ثانیهای تبدیل کردیم. که این گونه از هر کلاس 300 موسیقی برای تعلیم شبکه بدست آوردیم. در مرحلهی نخست داده ها با استفاده از فریم ورک tensorflow به دو دسته train و valid به نسبت یک به 9 تقسیم میکنیم. داده های خوانده شده، در حال حاضر حاوی شیپ ( تعداد کانال، طول صوت، سایز بچ ) میباشد که با فرا خواندن تابع squeeze_by_avg مقادیر موجود در کانال های مختلف جمع شده و میانگیری میشود . تا بتوانیم شیپ را به ( طول صوت، سایز بچ ) تغییر دهیم. دلیل این عمل این است که برای استفاده از تابع رسم اسپکتوگرام فریم ورک tensorflow نباید در شیپ تعداد کانال ها موجود باشد و تنها آرایهای یک بعدی از ورودی تحویل میگیرد.
داده های خوانده شده، در حال حاضر حاوی شیپ ( تعداد کانال، طول صوت، سایز بچ ) میباشد که با فرا خواندن تابع squeeze_by_avg مقادیر موجود در کانال های مختلف جمع شده و میانگیری میشود . تا بتوانیم شیپ را به ( طول صوت، سایز بچ ) تغییر دهیم. دلیل این عمل این است که برای استفاده از تابع رسم اسپکتوگرام فریم ورک tensorflow نباید در شیپ تعداد کانال ها موجود باشد و تنها آرایهای یک بعدی از ورودی تحویل میگیرد.
 همانطور که گفته شد، قرار است از روی صوت های ورودی اسپکتوگرام آنها را رسم کرده و از آن به عنوان ورودی استفاده کنیم. بنابراین تابعی نوشته شده که با استفاده از تابع آمادهی tf.signal.stft ابتدا اسپکتوگرام صوت مدنظر را تولید کرده و سپس با قدر مطلق گیری مقادیر منقی را از حذف میکنیم، و از آنجایی که این اسپکتو گرام قرار است به لایه های کانولوشنی تحویل داده شود، به انتهای آن یک بعد اضافه میکنیم تا شیب به ( تعداد فیلتر، تعداد بازه های فرکانسی، زمان، سایز بچ) تبدیل شود.
در این مرحله با صدا زدن تابع map توابع طراحی شده را روی دیتاست ها اعمال میکنیم. توابع cache و prefetch تنها جهت افزایش سرعت ورودی دادن به مدل استفاده شدهاند و ضرورتی برای استفاده از آنها نیست.
همانطور که گفته شد، قرار است از روی صوت های ورودی اسپکتوگرام آنها را رسم کرده و از آن به عنوان ورودی استفاده کنیم. بنابراین تابعی نوشته شده که با استفاده از تابع آمادهی tf.signal.stft ابتدا اسپکتوگرام صوت مدنظر را تولید کرده و سپس با قدر مطلق گیری مقادیر منقی را از حذف میکنیم، و از آنجایی که این اسپکتو گرام قرار است به لایه های کانولوشنی تحویل داده شود، به انتهای آن یک بعد اضافه میکنیم تا شیب به ( تعداد فیلتر، تعداد بازه های فرکانسی، زمان، سایز بچ) تبدیل شود.
در این مرحله با صدا زدن تابع map توابع طراحی شده را روی دیتاست ها اعمال میکنیم. توابع cache و prefetch تنها جهت افزایش سرعت ورودی دادن به مدل استفاده شدهاند و ضرورتی برای استفاده از آنها نیست.



طراحی شبکه عصبی :
همانطور که پیش تر اشاره شده بود، برای انجام این عملیات نیاز به شبکهای نسبتا عمیق داریم. این شبکه در اولین لایه خود دارای لایه resize میباشید. این لایه جهت پویا شدن شبکه عصبی قرار داده شده. با وحود این لایه میتوانیم ورودی هایی با طول های مختلف به شبکه بدهیم. زیرا که در همان ابتدا همه آنها را به ابعادی یکسان در میاورد. لایه های Normalization و BatchNormalization جهت بهبود کیفیت داده های ورودی گذاشته شده. سپس 3 لایه کانولوشن و به دنبال آن 3 لایه MaxPooling جهت استخراج ویژگی های اسپکتوگرام با تعداد فیلتر های 256، 256 و 128 قرار داده شدهاند. پس از استخراج ویژگی ها با توجه به تعداد لایه های MaxPooling و ابعاد اولیه عکس و تعداد فیلتر های لایه آخر نتیجهی حاصله را ریشیپ کرده تا بتوانیم ویژگی های آنرا به صورت ستونی به لایه RNN تحویل دهیم. با این عمل شیپ خروجی از (128، 16، 128، سایز بچ ) به (16*128، 128، سایز بچ) تغییر میکند. در واقع الان 128 بازه زمانی داریم که هر کدام دارای 2048 ویژگی استخراج شده میباشند و میتوان از آنها به خوبی در لایه RNN استفاده کرد. در این شبکه 2 لایه RNN->GRU استفاده شده که بر اساس تجربه صورت گرفته این عمل باعث افزایش قدرت یادگیری شبکه شده است. پس از لایه های RNN چند لایه Dense قرار داده شده تا پیچیدگی شبکه را افزایش دهد. و در انتها یک لایه 10 نورونه جهت تشخیص 10 کلاس موجود قرار دارد.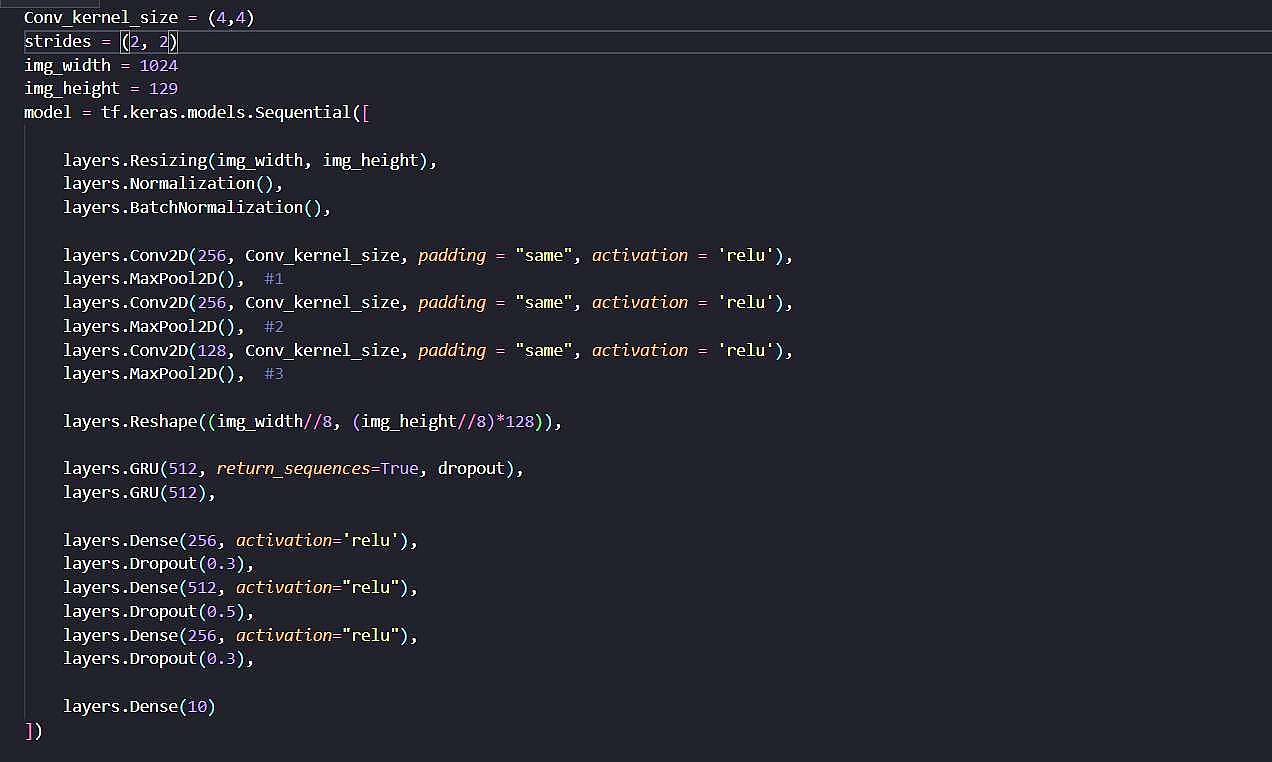
تعلیم شبکه عصبی :
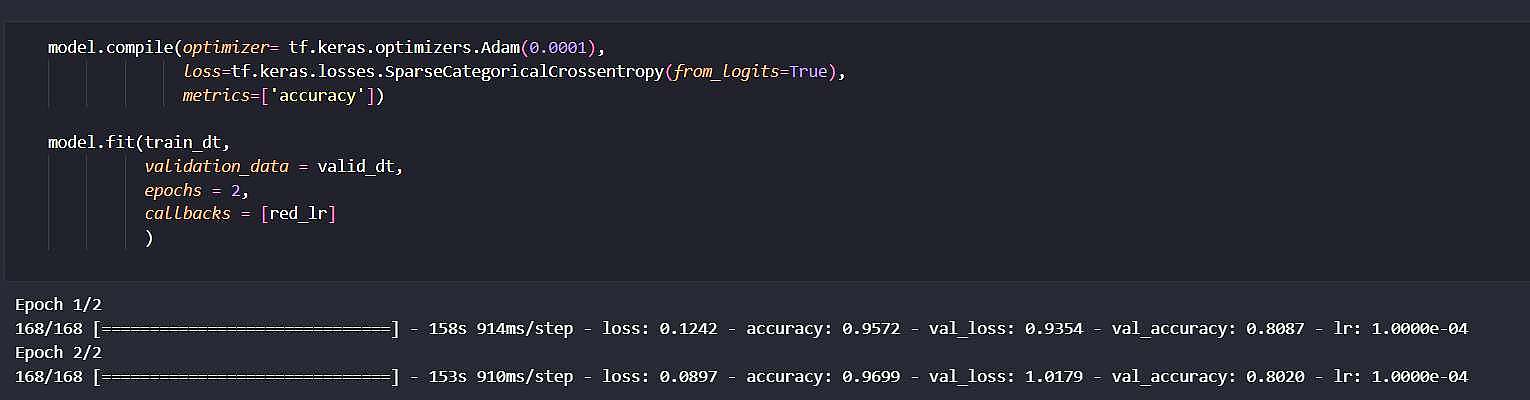
در مرحله نخست، این مدل را با lr = 0.001 تعلیم طی 15 ایپاک تعلیم دادیم که در انتها به دقت 80 درصد دست یافتیم.
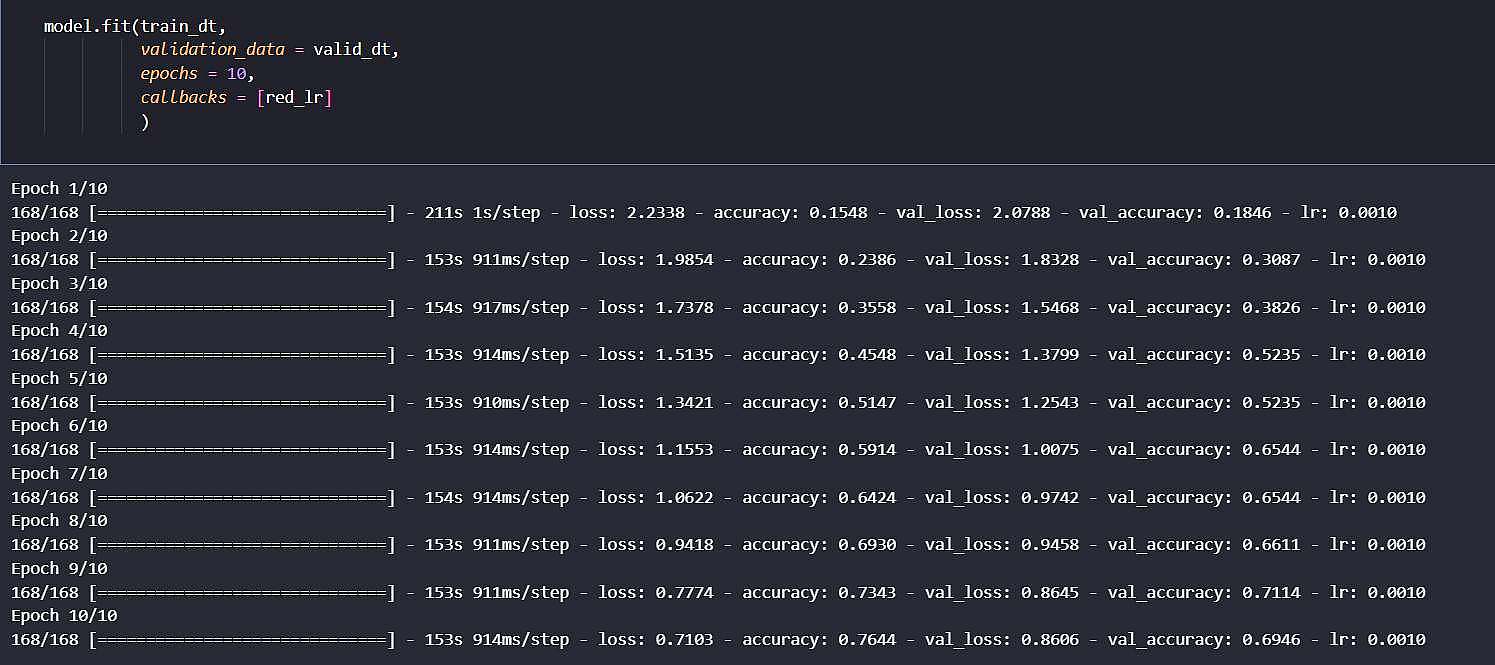
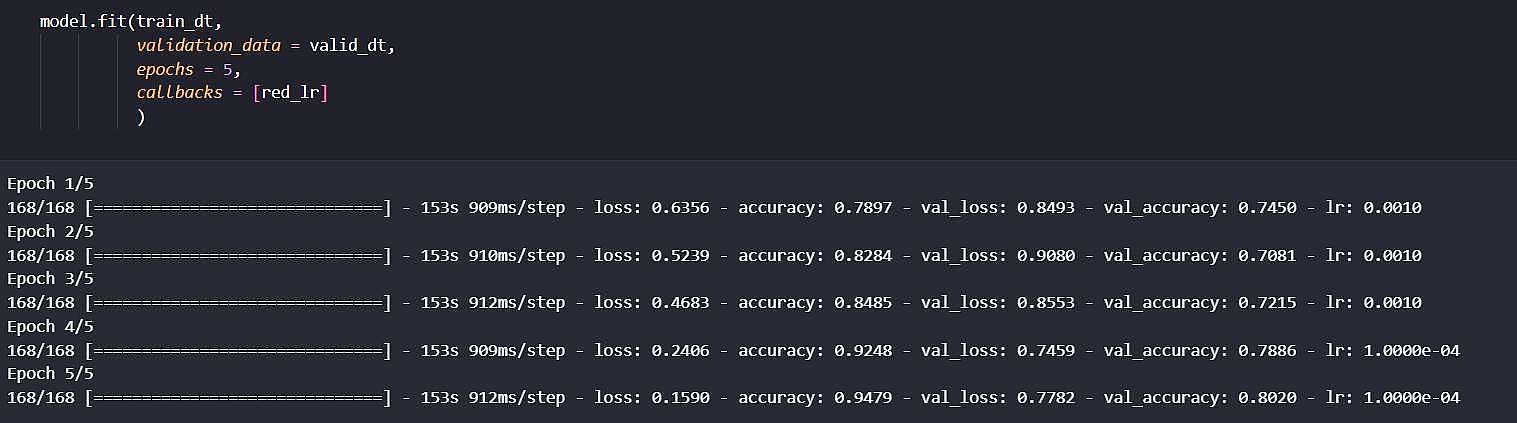 جهت برسی رشد بیشتر دقت، این مدل با lr = 0.0001 نیز 2 ایپاک بیشتر تعلیم داده شد. که با مشاهده روند دقت نزولی از تعلیم بیشتر صرف نظر شد.
جهت برسی رشد بیشتر دقت، این مدل با lr = 0.0001 نیز 2 ایپاک بیشتر تعلیم داده شد. که با مشاهده روند دقت نزولی از تعلیم بیشتر صرف نظر شد.
ارزیابی نهایی عملکرد شبکه :
در این بخش با مشاهدهی confusion_matrix دقت عملکرد پیش بینی های مدل را مشاهده میکنید. بیشترین خطا بین کلاس های Rock و Country میباشد، که طبق مشاهدات 7 بار موسیقی با ژانر Rock را موسیقی با ژانر Country تشخیص داده است. از آنجایی که مدل تنها ریتم موسیقی هارا دنبال میکند و معانی کلمال توجهی نمیکند این امری طبیعیست، چرا که که یکی از مشخصه های موسیقی Country بیان یک قصه در طول موزیک میباشد.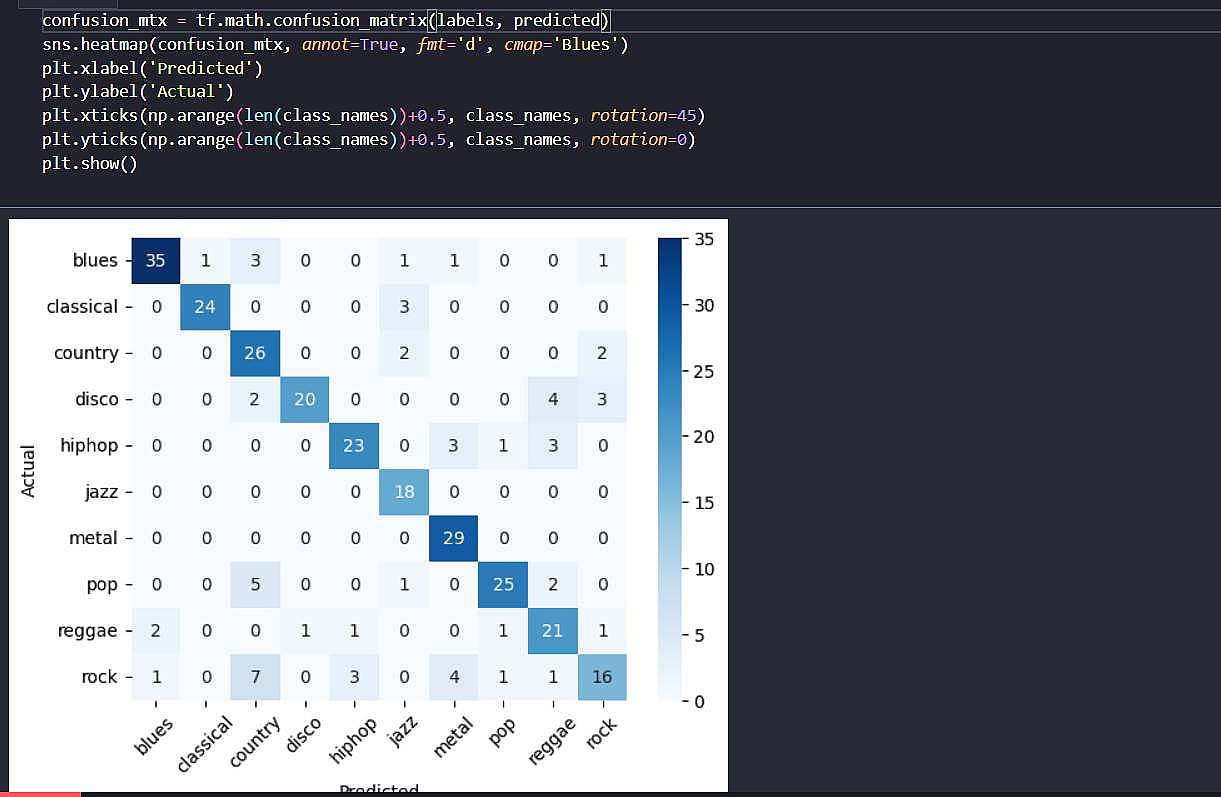
تست شبکه روی چند موسیقی :
برای تست این مدل فرایند ویژهای صورت گرفته. توجه داشته باشید مدل ما با موسیقی هایی با طول 10 ثانیه تعلیم داده شده است. این مسئله درست است که با تمهیدات انجام شده مثل لایه Resize در ابتدای مدل، سعی کردیم ورودی مدل را پویا کنیم، ولی این به این معنی نیست که این مدل به تواند داده های بسیار بلند را به همان خوبی دادههای کوچک تشخیص دهد. بنابراین توابع ویژهای جهت پیش پردازش موسیقی های بلند طراحی شد تا این مشکل را حل کند. اولین تابع، تابع spectogram است که اینبار یه شکلی پیاده سازی شده که پس رسم اسپکتوگرام آنرا مجددا به بازههای 2000 تایی تقسیم کرده و برمیگرداند. در حقیقت قصد داریم برای هر موسیقی چندین پیشبینی انجام دهیم و بر اساس تجمیع این پیشبینی ها به 2 روش مختلف کلاس بندی موسیقی را انجام دهیم.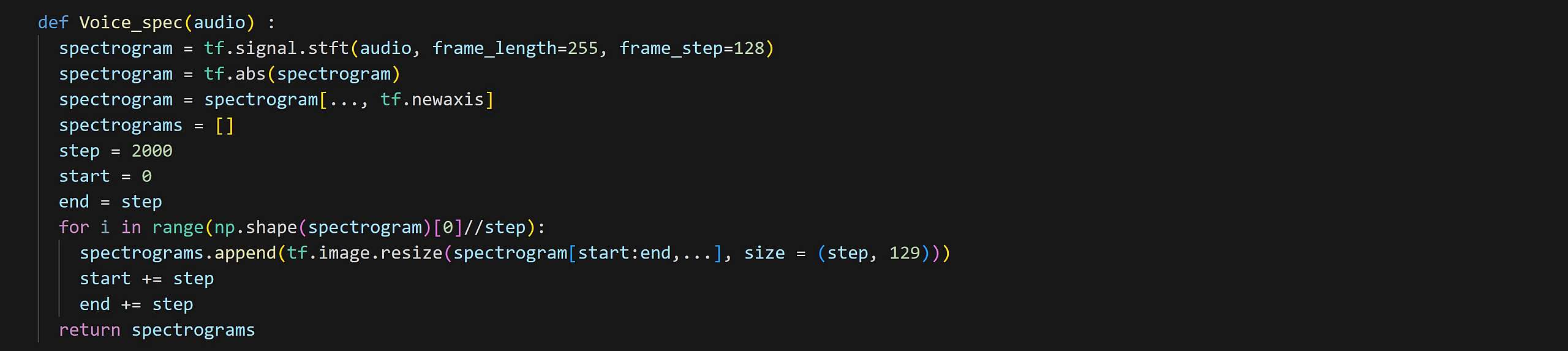 اولین تابع پیشبینی، نتایج حاصله از پیش بینی اسپکتوگرام های بدست امده را میانگین میگیرد و برندهی نهایی را بر اساس روش حریصانه بین logits ها اعلام میکند.
اولین تابع پیشبینی، نتایج حاصله از پیش بینی اسپکتوگرام های بدست امده را میانگین میگیرد و برندهی نهایی را بر اساس روش حریصانه بین logits ها اعلام میکند.
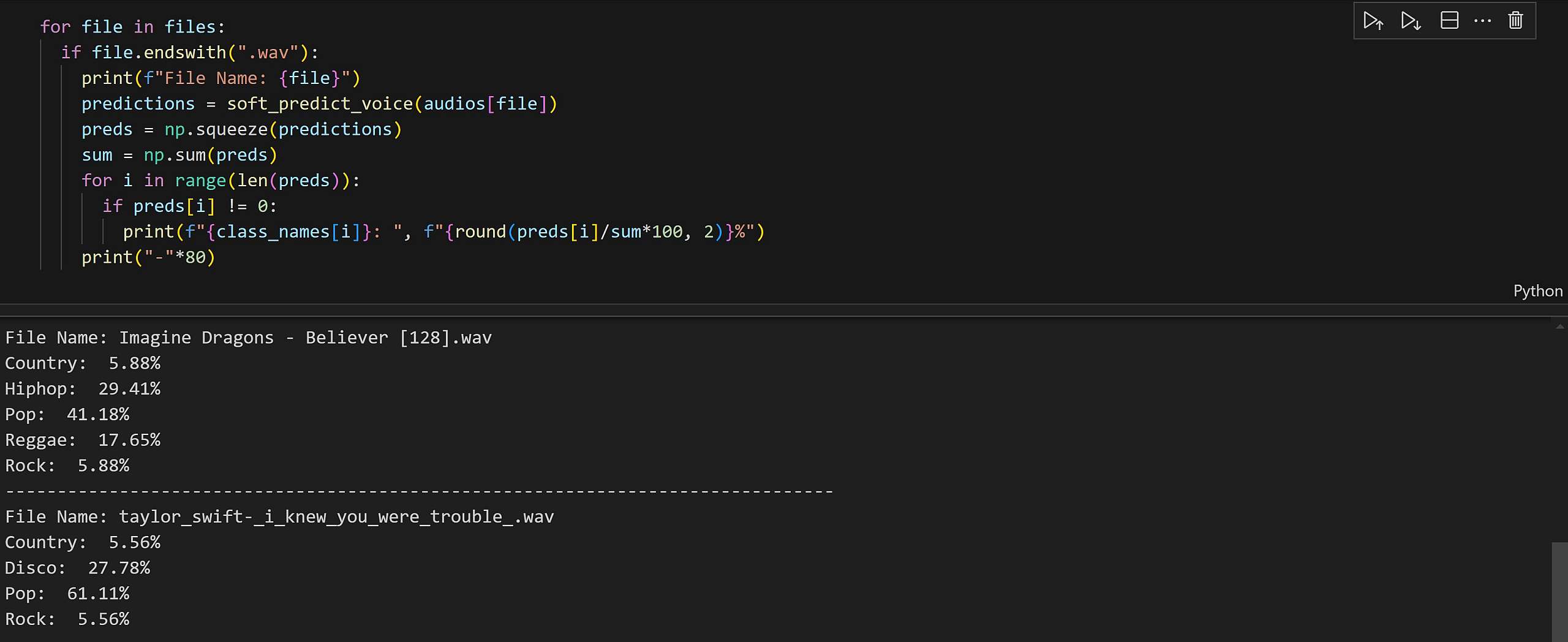
 دومین تابع پیشبینی، که soft_predict نام دارد، هر موسیقی را دارای چند ژانر در نظر میگیرد و برای هر موسیقی ژانر های بدست آمده و درصد آنها را از طریق تعداد نتایج حاصل از پیشبینی نشان میدهد.
دومین تابع پیشبینی، که soft_predict نام دارد، هر موسیقی را دارای چند ژانر در نظر میگیرد و برای هر موسیقی ژانر های بدست آمده و درصد آنها را از طریق تعداد نتایج حاصل از پیشبینی نشان میدهد.

Predict
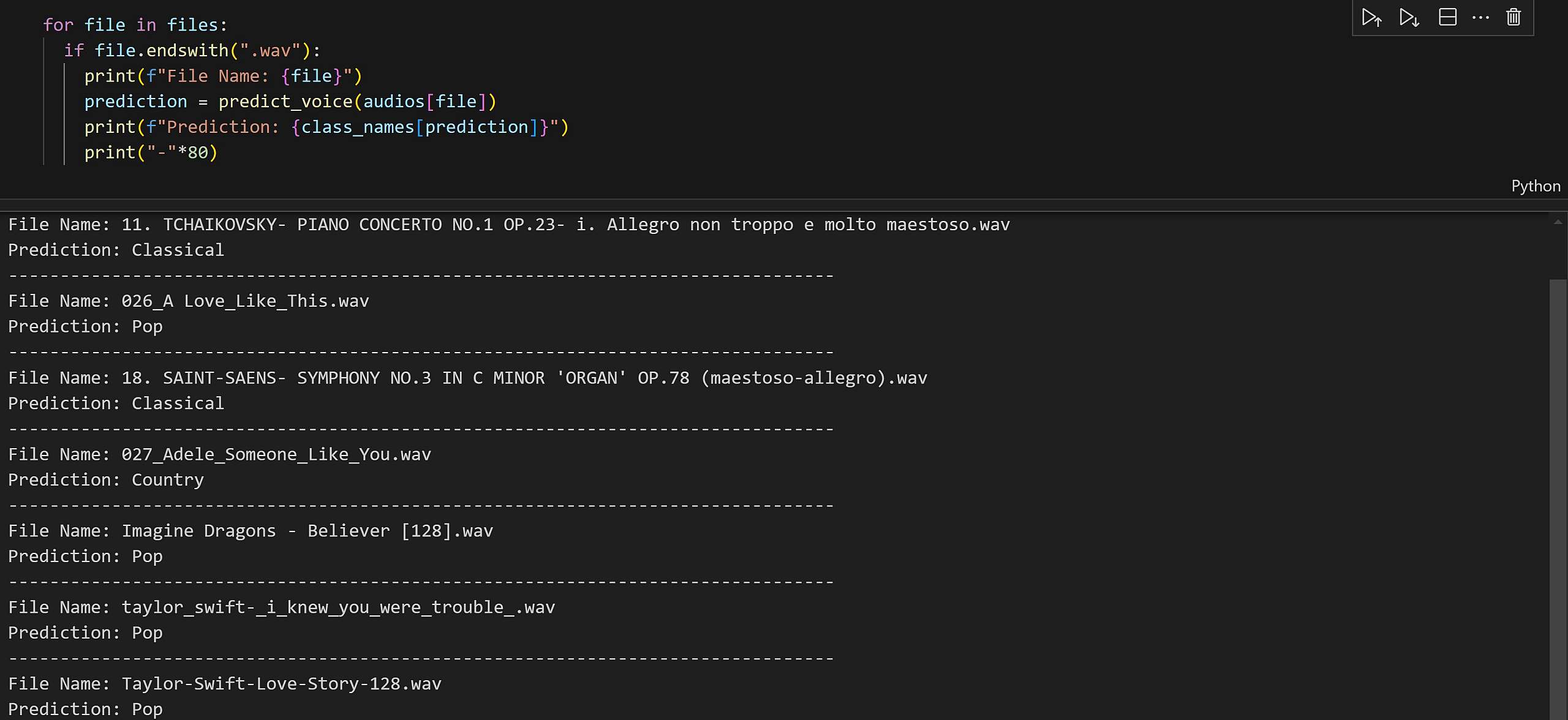
Soft_Predict