تحلیل مقاله EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks 1

مقدمه
شبکههای عصبی پیچشی (ConvNets) معمولاً با بودجه منابع ثابتی توسعه مییابند و سپس در صورت دسترسی به منابع بیشتر برای دستیابی به دقت بالاتر، گسترش مییابند. بسياري از معماري هاي طراحي شده در راستاي استفاده از توان محاسباتي موجود به صورت بهينه مي باشند مانند MobileNet. حال ميخواهيم بدانيم اگر ميزان توان محاسباتي كاهش يا افزايش پيدا كند يا اگر بخواهيم يك شبكه زودتر آموزش داده شود، به چه طريق ميتوان شبكه مورد نظر را scale كنيم.
در معماري هاي طراحي شده در شبكه هاي كانولوشن، سه روش براي افزايش دقت استفاده مي شود.اين سه روش شامل: افزايش عمق شبكه، ارتفاع شبكه و همچنين افزايش رزولوشن ورودي مي باشد. كه افزايش هر كدام از اين ويژگيها مي تواند باعث بهبود عملكرد شبكه شود. در این مقاله، بهطور سیستماتیک مقیاسگذاری مدل بررسی شده و شناسایی میشود که با متعادلسازی عمق، عرض و وضوح شبکه میتوان به عملکرد بهتری دست یافت. این مقاله، یک روش مقیاسگذاری جدید پیشنهاد میکند که بهطور یکنواخت همه ابعاد عمق/عرض/وضوح را با استفاده از یک ضریب ترکیبی ساده اما بسیار مؤثر مقیاس میدهد.
در نتیجه این مقاله، یک شبکه پایه جدید ارائه شد و با گسترش آن یک خانواده از مدلها، به نام EfficientNets، به دست آمد که دقت و کارایی بسیار بهتری نسبت به ConvNets قبلی دارند.
معرفی
بزرگسازی شبکههای عصبی پیچشی (ConvNets) به طور گستردهای برای دستیابی به دقت بهتر استفاده میشود. به عنوان مثال، (ResNet (He et al., 2016 میتواند از ResNet-18 به ResNet-200 با استفاده از لایههای بیشتر برسد؛ اخیراً، (GPipe (Huang et al., 2018 به دقت top-1 84.3% در ImageNet دست یافته است و این درصد بالا دقت با بزرگسازی یک مدل پایه به چهار برابر بزرگتر حاصل شده است.
اگرچه افزایش اندازه شبکههای عصبی پیچشی برای بهبود دقت بسیار متداول است، اما هنوز هم درک کاملی از چگونگی انجام این فرآیند و بهینهسازی آن وجود ندارد. رایجترین روش، بزرگسازی شبکههای عصبی پیچشی از طریق افزایش عمق آنها (He et al., 2016) یا عرض آنها (Zagoruyko & Komodakis, 2016) است. روش دیگر که کمتر رایج است، بزرگسازی مدلها از طریق افزایش وضوح تصویر است (Huang et al., 2018). در کارهای قبلی، معمولاً تنها یکی از سه بعد – عمق، عرض، و اندازه تصویر – بزرگسازی میشود. هرچند که امکان بزرگسازی دو یا سه بعد به صورت دلخواه وجود دارد، این نوع بزرگسازی دلخواه نیاز به تنظیمات دستی خستهکنندهای دارد و همچنان اغلب دقت و کارایی بهینهای ندارد.
در اين مقاله ايده اي در رابطه با طراحي شبكه جديد مطرح نشده است. بلكه با توجه به اينكه دستگاه هاي مختلف از توان پردازشي متفاوتي بهره مند هستند ميخواهيم شيوه اي داشته باشيم كه با توجه به دستگاه در دسترس و توانايي پردازش موجود چگونه يك شبكه را Scale كنيم. متعادلسازی همه ابعاد عرض/عمق/وضوح شبکه بسیار حیاتی است و به طرز شگفتانگیزی این تعادل میتواند به سادگی با مقیاسدهی هر یک از آنها با یک نسبت ثابت حاصل شود. در این روش بهطور یکنواخت عرض شبکه، عمق و وضوح را با مجموعهای از ضرایب ثابت Scale میكنيم.
/*! elementor - v3.17.0 - 08-11-2023 */ .elementor-widget-image{text-align:center}.elementor-widget-image a{display:inline-block}.elementor-widget-image a img[src$=".svg"]{width:48px}.elementor-widget-image img{vertical-align:middle;display:inline-block}
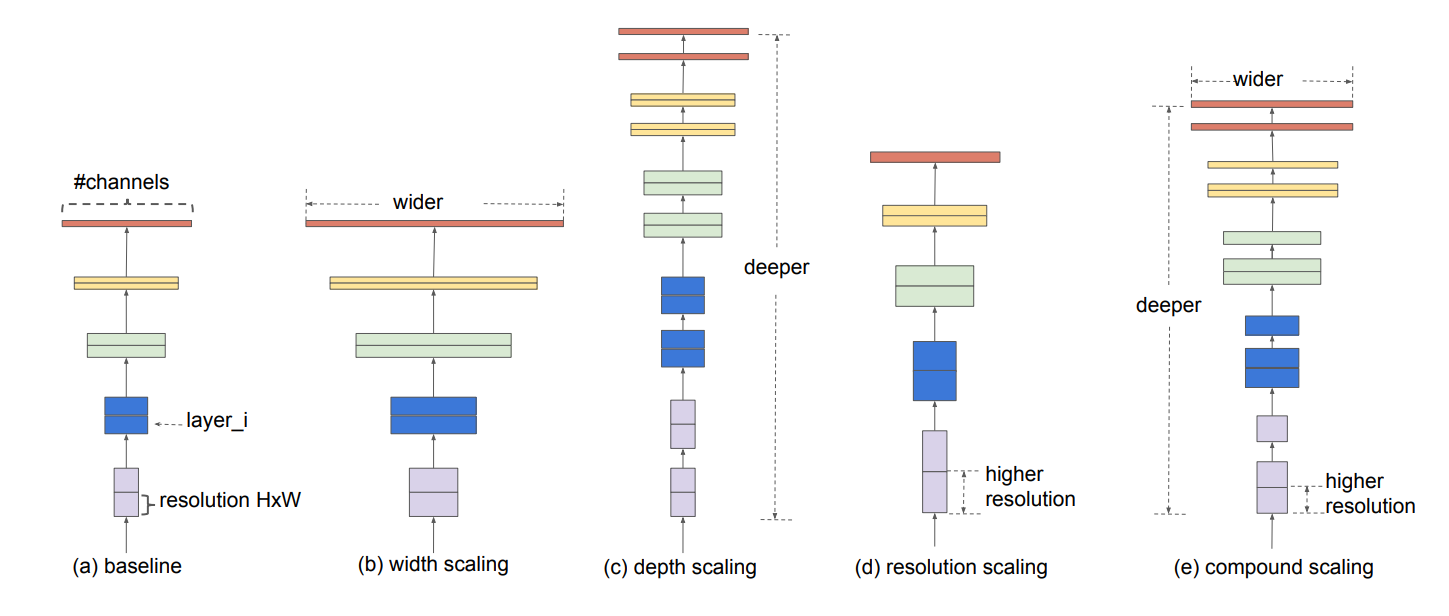
شكل1 model scaling
شکل 1 تفاوت بین روش مقیاسدهی EfficientNets و روشهای سنتی را نشان میدهد.
این مقاله، از جستجوی معماری عصبی (Zoph & Le, 2017؛ Tan et al., 2019) برای توسعه یک شبکه پایه جدید استفاده میکند و آن را مقیاس میدهد تا خانوادهای از مدلها به نام EfficientNets به دست آید.
Compound Model Scaling
فرمول بندی
یک لایه شبکه عصبی پیچشی i میتواند به عنوان یک تابع تعریف شود: Yi=Fi(Xi) ، که در آن Fi اپراتور، Yi tensor خروجی، Xi tensor ورودی است، با شکل tensor (Hi,Wi,Ci) که در آن Hi و Wiابعاد فضایی و Ci بعد کانال هستند. یک شبکه عصبی پیچشی N میتواند به صورت یک لیست از لایههای مرکب نمایش داده شود:
در عمل، لایههای شبکه عصبی پیچشی اغلب به چند مرحله تقسیم میشوند و تمام لایههای هر مرحله معماری یکسانی دارند: به عنوان مثال، (ResNet(He et al., 2016 دارای پنج مرحله است و تمام لایههای هر مرحله از همان نوع پیچشی استفاده میکنند به جز لایه اول که down-sampling را انجام میدهد. بنابراین، میتوانیم یک شبکه عصبی پیچشی را به صورت زیر تعریف کنیم:
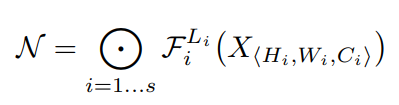
معادله 1
بر خلاف طراحیهای معمولی شبکه عصبی پیچشی که بیشتر بر یافتن بهترین معماری لایه Fi متمرکز هستند، Scale مدل تلاش میکند تا طول شبکه (Li) ،عرض (Ci) و وضوح (Hi,Wi) را بدون تغییرFi از پیش تعریف شده در شبکه پایه گسترش دهد. با ثابت نگه داشتن Fi Scale مدل، مسئله طراحی را برای محدودیتهای جدید منابع ساده میکند، اما همچنان فضای طراحی بزرگی برای کاوش در مورد Li, Ci, Hi, Wi برای هر لایه باقی میماند. برای کاهش بیشتر فضای طراحی، تمام لایهها باید به طور یکنواخت با نسبت ثابت مقیاس شوند. هدف به حداکثر رساندن دقت مدل برای هر محدودیت منابع معین است که میتواند به عنوان یک مسئله بهینهسازی فرموله شود:

معادله 2
که در آن r، d و w ضرایب مقیاسبندی عرض شبکه، عمق و وضوح هستند؛ Li, Ci, Hi, Wi, Fi پارامترهای از پیش تعریف شده در شبکه پایه هستند.به طور خلاصه، هدف این است که با استفاده از این ضرایب و پارامترهای ثابت، شبکه را بهینه شود تا برای هر محدودیت منابع داده شده، به بهترین دقت ممکن برسد . این روش Scale ترکیبی با سادهسازی فرآیند Scale شبکه، طراحی شبکههای پیچشی مؤثرتر و کارآمدتری را ممکن میسازد.
ابعاد Scaling
مشکل اصلی دوم مسئله این است که ضرایب بهینه r، d و w به یکدیگر وابسته هستند و مقادیر آنها تحت محدودیتهای مختلف منابع تغییر میکنند. به دلیل این دشواری، روشهای متداول اغلب شبکههای عصبی پیچشی (ConvNets) را تنها در یکی از این ابعاد مقیاس میدهند:
عمق (d): مقیاسدهی عمق شبکه رایجترین روشی است که توسط بسیاری از شبکههای عصبی پیچشی استفاده میشود (He et al., 2016؛ Huang et al., 2017؛ Szegedy et al., 2015؛ 2016). تصور عمومی این است که یک شبکه عصبی پیچشی عمیقتر میتواند ویژگیهای غنیتر و پیچیدهتری را شناسایی کند و در وظایف جدید به خوبی تعمیم یابد. با این حال، شبکههای عمیقتر به دلیل مشکل ناپدید شدن گرادیان، سختتر آموزش داده میشوند (Zagoruyko & Komodakis, 2016). اگرچه تکنیکهای مختلفی مانند اتصالات پرشی (skip connections) و نرمالسازی batch (Ioffe & Szegedy, 2015 مشکل آموزش را کاهش میدهند، اما افزایش دقت شبکههای بسیار عمیق کاهش مییابد؛
عرض (w): مقیاسدهی عرض شبکه معمولاً برای مدلهای با اندازه کوچک استفاده میشود. همانطور که در (Zagoruyko & Komodakis, 2016) مورد بحث قرار گرفته است، شبکههای پهنتر تمایل به شناسایی ویژگیهای جزئیتر دارند و آموزش آنها آسانتر است. با این حال، شبکههای بسیار پهن ولی کمعمق معمولاً در شناسایی ویژگیهای سطح بالاتر دچار مشکل میشوند.
وضوح (r): با تصاویر ورودی با وضوح بالاتر، شبکههای عصبی پیچشی میتوانند الگوهای جزئیتری را شناسایی کنند. شروع از وضوح 224x224 در شبکههای عصبی پیچشی اولیه، شبکههای عصبی پیچشی مدرن تر تمایل به استفاده از وضوح 299x299 یا 331x331 برای دقت بهتر دارند.GPipe به دقت بالای ImageNet با وضوح 480x480 دست یافته است. وضوحهای بالاتر، مانند 600x600، نیز به طور گسترده در شبکههای عصبی پیچشی برای تشخیص اشیا استفاده میشوند.
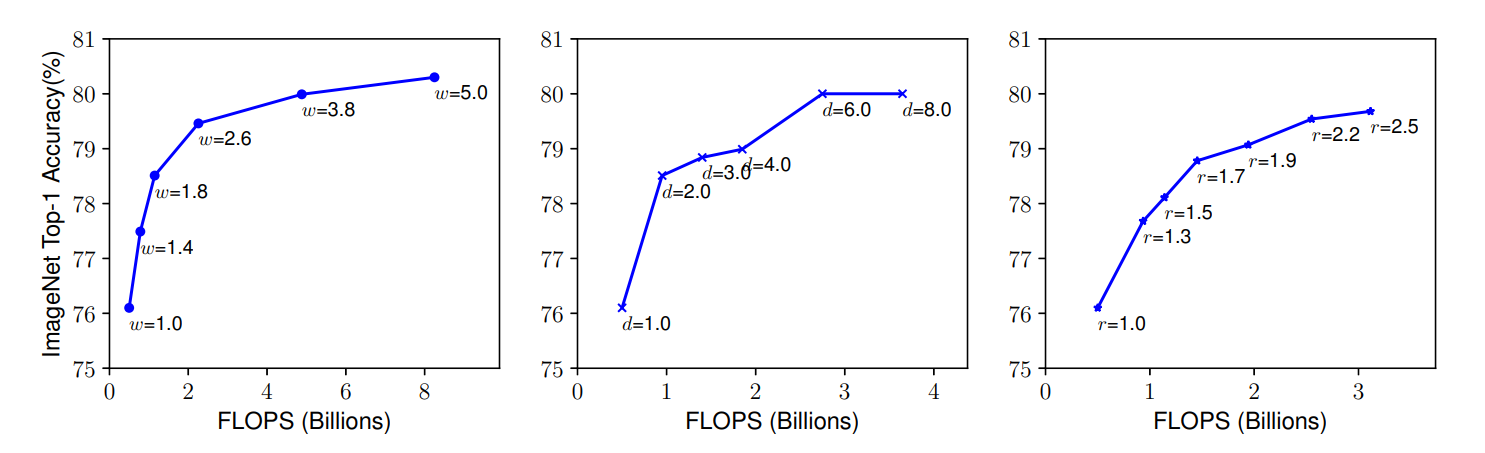
شكل 2: ميزان دقت بر اساس افزايش هر يك از ابعاد عرض، طول و رزولوشن به صورت جداگانه
Scale یک مدل پایه با ضرایب مختلف عرض شبکه (w)، عمق (d) و وضوح (r). شبکههای بزرگتر با عرض، عمق یا وضوح بیشتر انتظار میرود به دقت بالاتر برسند، اما افزایش دقت پس از رسیدن به 80% به سرعت اشباع میشود، که محدودیت مقیاسدهی در یک بعد را نشان میدهد.
اگرچه افزایش عرض، عمق یا وضوح شبکه میتواند به بهبود دقت مدل منجر شود، اما این بهبود تا حد معینی ادامه دارد و پس از آن، افزایش بیشتر در یکی از این ابعاد تاثیر چندانی در بهبود دقت نخواهد داشت. این محدودیت نشان میدهد که برای دستیابی به دقت بالاتر، نیاز به یک روش مقیاسدهی ترکیبی است که به طور همزمان تمام ابعاد شبکه را در نظر بگیرد.
Scaling ترکیبی
بهطور تجربی مشاهده کردیم که ابعاد مختلف مقیاسدهی مستقل نیستند. بهطور شهودی، برای تصاویر با وضوح بالاتر، باید عمق شبکه را افزایش دهیم تا میدانهای دریافت بزرگتر بتوانند ویژگیهای مشابهی که شامل پیکسلهای بیشتری در تصاویر بزرگتر هستند، شناسایی کنند. به همین ترتیب، باید عمق شبکه را نیز افزایش دهیم تا بتوانیم الگوهای جزئیتری را با پیکسلهای بیشتر در تصاویر با وضوح بالا شناسایی کنیم.این مشاهدات نشان میدهند که نیاز به هماهنگی و تعادل در ابعاد مختلف Scaling داریم و نباید تنها به مقیاسدهی در یک بعد محدود شویم.
رای تأیید این مشاهدات، ما Scaling عرض شبکه را تحت شرایط مختلف عمق و وضوح مقایسه کردیم، همانطور که در شکل 3 نشان داده شده است. اگر تنها عرض شبکه w را بدون تغییر عمق (d=1.0d) و وضوح (r=1.0r) مقیاس دهیم، دقت به سرعت اشباع میشود. با عمق بیشتر (d=2.0d) و وضوح بالاتر (r=2.0r) ، مقیاسدهی عرض به دقت بسیار بهتری تحت همان هزینه FLOPS دست مییابد.
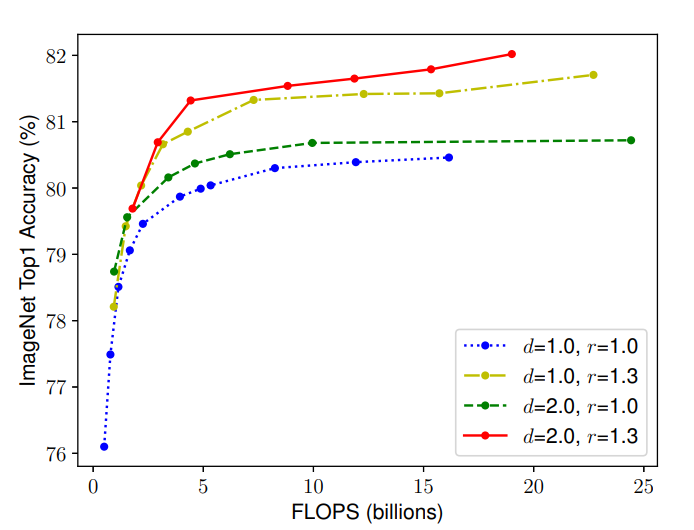
شكل 3: ميزان افزايش دقت از تركيب دو بعد عمق و رزولوشن
مشاهدهاي كه صورت گرفته است و نتيجه ي آن را ميتوان در شكل سوم مشاهده نمود، نشان ميدهد كه ميتوان با تركيب اين ابعاد با يكديگر به ميزان دقت بيشتري دست پيدا نمود.
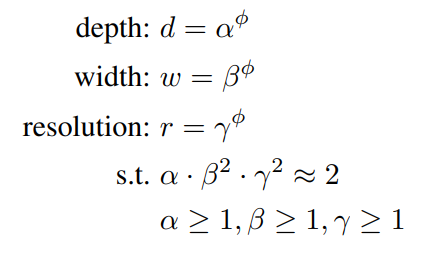 معادله 3
معادله 3

معماری EfficientNet
معماري كه به عنوان baseline در نظر گرفته مي شود نيز از اهميت بسياري برخوردار است، زيرا EfficientNet معماري baseline را تغييري نمي دهد و صرفا آن را scale ميكند. و علاوه بر آن به طور مثال اگر Alexnet به عنوان baseline استفاده شود، و بعد از تغيير scale با استفاده از عرض، طول و رزولوشن روي همان Alexnet مقايسه ميشود و ب شبكهي ديگري به طور مثال مانند REsnet مقايسه نمي شود. پس بنابراين داشتن يك baseline مناسب نيز از اهميت ويژه اي برخوردار است.
EfficientNet داراي هفت ورژن مختلف مي باشد. كه ابتدا B0 را با استفاده از روش و معماري معرفي شده به دست مي آورده و آن را به عنوان baseline در نظر گرفته و سپس با دو گام ورژن هايي ديگر (B1-B7) را به دست مي آوريم.
با الهام از (Tan et al., 2019)، شبکه baseline با استفاده از یک جستجوی معماری عصبی چند هدفه که دقت و تعداد عملیات اعشاری ممیز شناور (FLOPS) را بهینه میکند، توسعه داده شده است. به عبارت دیگر، این روش جستجوی معماری عصبی، به دنبال پیدا کردن یک ساختار شبکه عصبی است که بهینهترین ترکیب از دقت بالا و هزینه محاسباتی (که با FLOPS اندازهگیری میشود) را فراهم کند. جستجوی معماری عصبی چند هدفه به این معنی است که فرآیند جستجو به طور همزمان دو هدف را در نظر میگیرد و تلاش میکند تا به تعادل مناسبی بین این دو هدف برسد. بهطور خاص، از همان فضای جستجوی (Tan et al., 2019) و از هدف بهینهسازی
استفاده شده است، ACC(m) و FLOPS(m) به ترتیب دقت و FLOPS مدل m را نشان میدهند، T تعداد هدف FLOPS w=−0.07 ، یک Hyperparameter برای کنترل تعادل بین دقت و FLOPS است.
در نهایت این جستجوی یک شبکه کارآمد تولید میکند که آن را EfficientNet-B0 مینامیم.
از شبکه پایه EfficientNet-B0 شروع میکنیم، روش Scaling ترکیبی را به دو مرحله اعمال میکنیم:

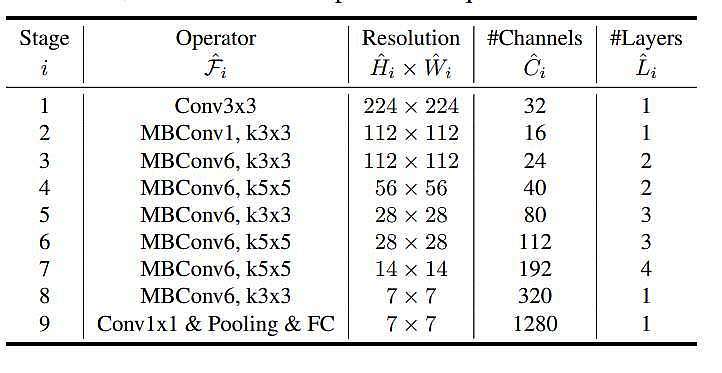
جدول 1: شبکه پایه EfficientNet-B0
در این جدول، هر مرحله i شامل تعداد مشخصی لایه Li است که با وضوح ورودی (Hi,Wi) و تعداد کانالهای خروجی Ci توصیف میشود. به عنوان مثال، در مرحله اول، شبکه دارای یک لایه با وضوح ورودی 224x224 و 32 کانال خروجی است.نتایج
همان طور كه در شكل 4 ميتوان مشاهده نمود، دقت efficientnet نسبت به بقيه مدل ها بيشتر مي باشد.
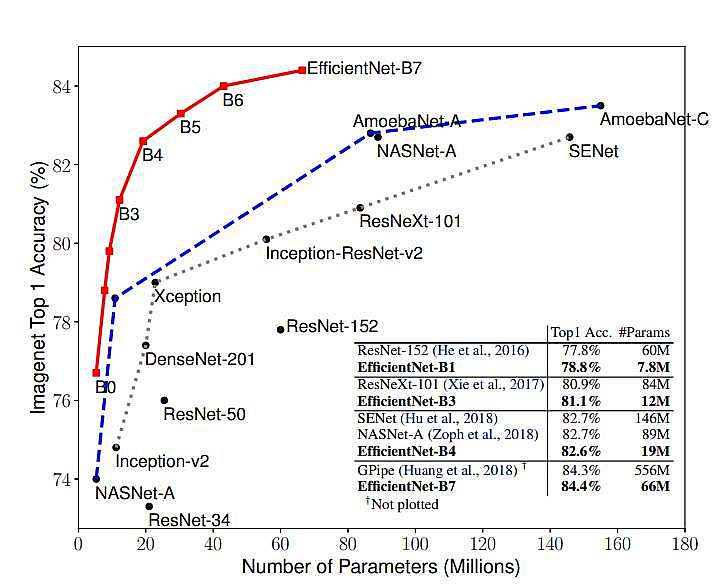
شكل 4: دقت EfficientNet
سوالي كه پيش ميآيد اين است كه آيا ممكن است نتايج به دست آمده صرفا به خاطر معماري نمي باشد، آيا EfficientNet مدل ها را بهبود بخشيده است؟
نويسندگان مقاله روش خود را بر روي چندين مدل پياده سازي كرده و نتايج مشابهي به دست آورده اند كه مي توان در جدول 2 مشاهده نمود. با توجه به اينكه پس از اعمال روش efficient net بر روي مدل هاي مختلف، دقت بهبود پيدا كرده است، بنابراين مي توان اين روش وافزايش دقت توسط آن را به تمامي مدل ها تعميم داد.
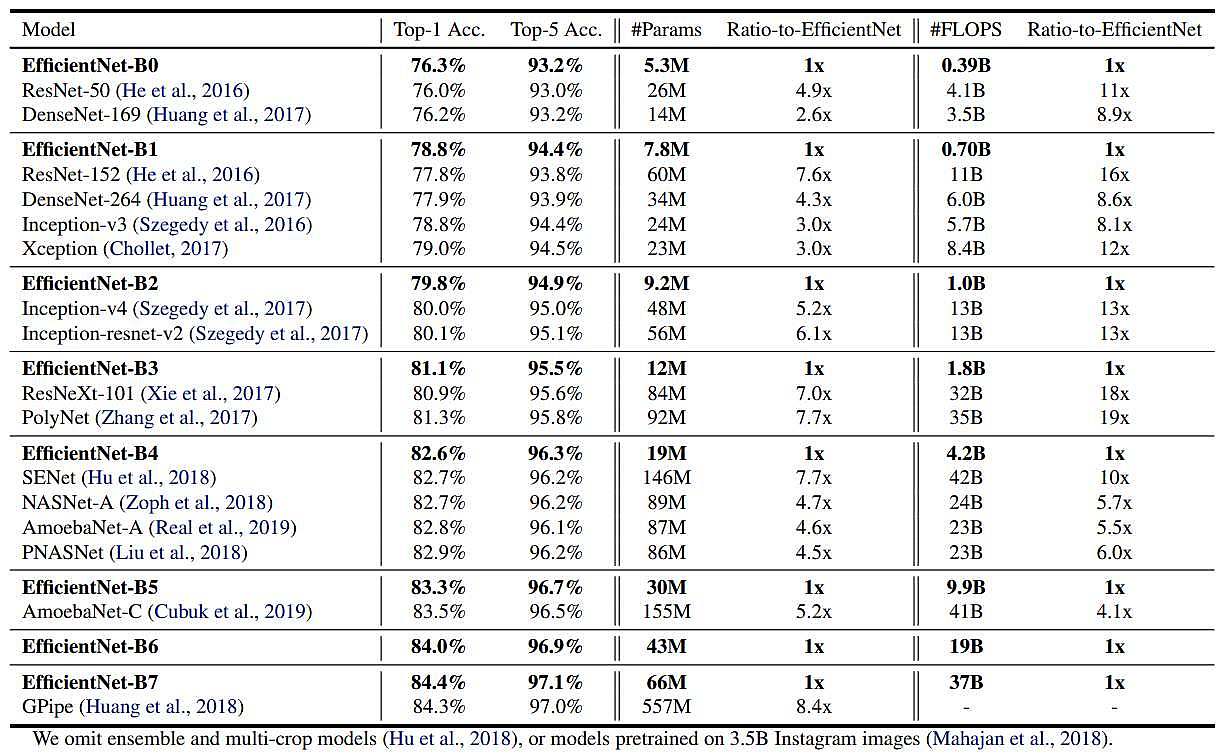
جدول 2: ورژن هاي مختلف EfficientNet
و همان طور كه درجدول 2 ميتان مشاهده نمود EfficientNet در تمام ورژنهاي خود از مدل هاي ديگر داراي دقت بيشتر، مقدار پارامتر كمتر و FLOPS كمتري مي باشد. EfficientNet B7 به دقت 84.3% كه state-of-the-art مي باشد رسيده است و8.4x كوچك تر و 6.1x سريع تر مي باشد.
به عنوان یک اثبات مفهوم، ابتدا روش Scaling خود را به MobileNets و ResNet که بهطور گسترده استفاده میشوند، اعمال میکنیم.
.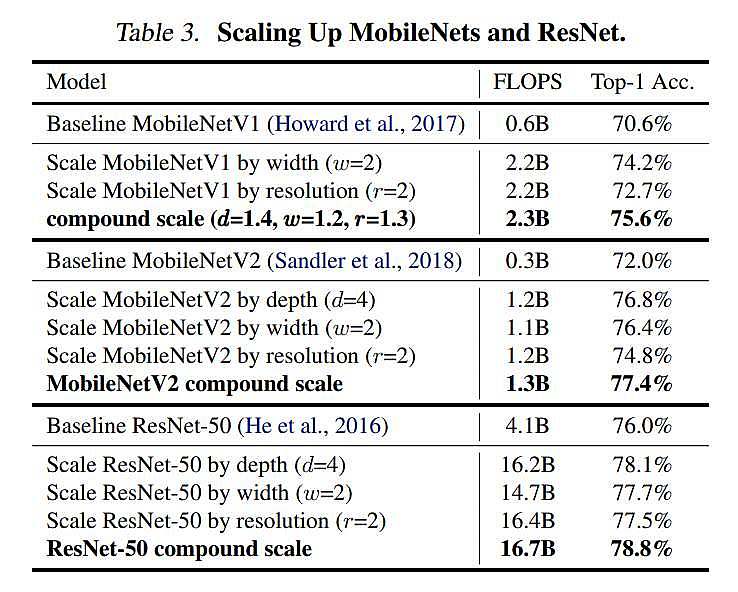 جدول 3
جدول 3
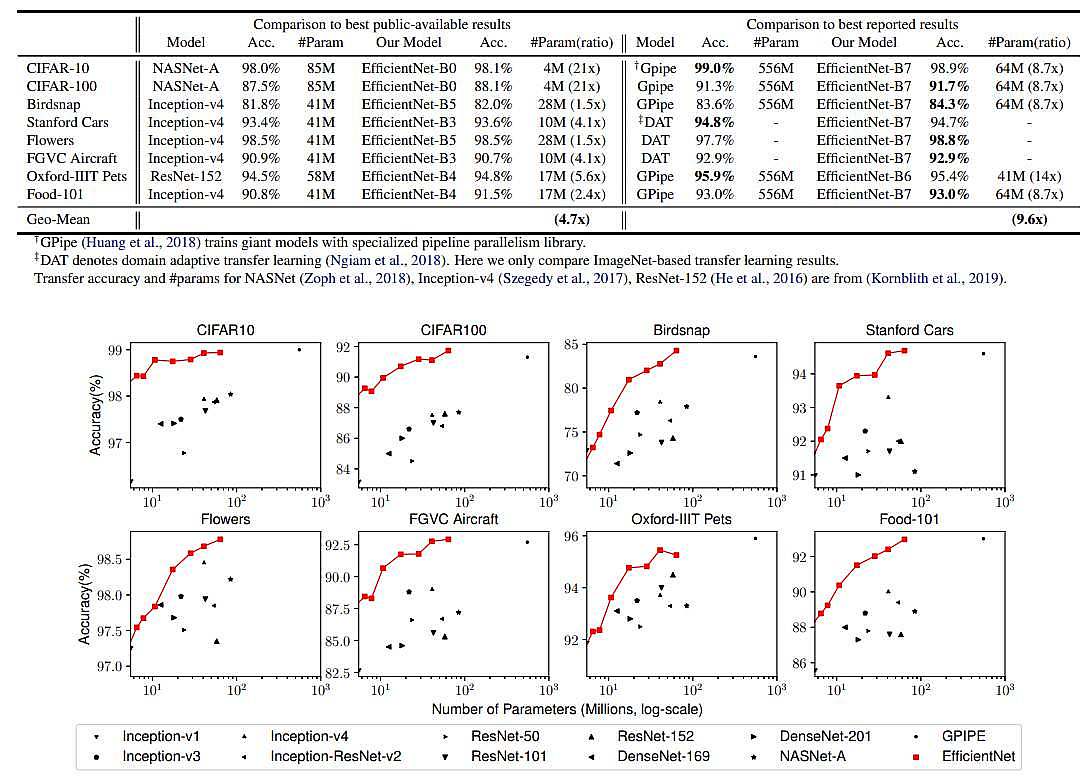
شکل 5:نتایج عملکرد EfficientNet بر روی دادههای Transfer learning
توضیح:
-
CIFAR-100: یک مجموعه دادهی تصاویر کوچک با 100 کلاس مختلف.
-
Flowers: یک مجموعه دادهی تصاویر گلها با دقت بسیار بالا.
-
Stanford Cars: یک مجموعه دادهی تصاویر اتومبیلها با جزئیات دقیق.
-
Oxford Pets: یک مجموعه دادهی تصاویر حیوانات خانگی.
-
FGVC Aircraft: یک مجموعه دادهی تصاویر هواپیماها با جزئیات دقیق.
-
Food-101: یک مجموعه دادهی تصاویر غذاها.
-
Caltech-101: یک مجموعه دادهی تصاویر از 101 کلاس مختلف اشیا.
-
Birdsnap: یک مجموعه دادهی تصاویر پرندگان.
این نتایج نشان میدهند که شبکههای EfficientNet به خوبی بر روی دادههای Transfer learning عمل میکنند و میتوانند دقت بالایی را در وظایف مختلف طبقهبندی تصاویر به دست آورند. این عملکرد بالا در دادههای مختلف نشاندهنده تعمیمپذیری و کارایی بالای این شبکهها است.
براي اينكه به صورت تصويري نيز بتوانيم نتايج را مشاهده كنيم، مي توان در شكل 6 Activaton Map را مشاهده نمود. كه همان طور كه مشخص مي باشد با اضافه نمودن هر كدام از ويژگي هاي عمق، عرض و رزولوشن نتايج تا حدودي بهبود يافته اند، و زماني كه از روش معرفي شده در اين مقاله compound scaling براي scale كردن شبكه استفاده شده است مشاهده مي شود كه نسبت به سه روش قبلي بهبود چشم گيري ايجاد شده است.
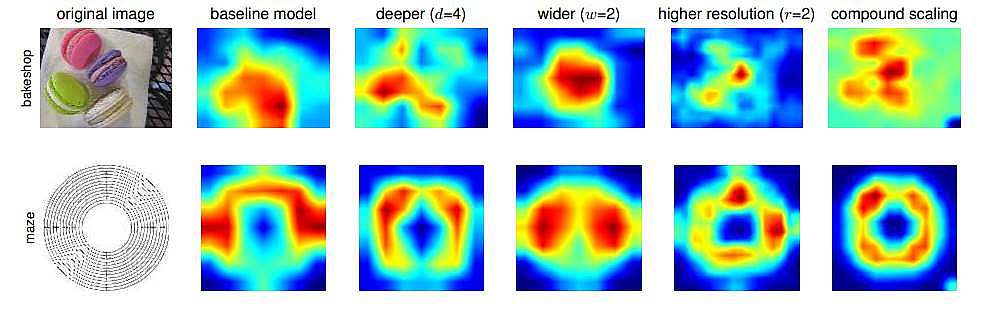
شكل 6: Activation Map EfficientNet
نتیجه گیری
در این مقاله، بهصورت سیستماتیک به بررسی Scaling شبکههای عصبی پیچشی (ConvNet) پرداخته شده است. تعادل دقیق بین پهنای شبکه، عمق و وضوح یک امر مهم است که عدم توجه به آن مانع از دستیابی به دقت و کارایی بهتر میشود. برای رفع این مشکل، نویسندگان این مقاله یک روش مقیاسبندی ترکیبی ساده و بسیار مؤثر پیشنهاد داده اند، که به ما امکان میدهد یک شبکه عصبی پایه (ConvNet) را به هر محدودیت منابع هدف به روشی اصولیتر scale کنیم، در حالی که کارایی مدل حفظ میشود.
منابع
-
مقاله EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
-
مقاله EfficientNet V1, EfficientNet V2 فرزانه حاتمینژاد