تشخیص دستنویس فارسی شهر های ایران

معرفی پروژه
این پروژه با هدف جمع اوری دست خط فارسی شهر های ایران به منظور تشخیص دستنویس اسمای شهر های ایران ایجاد شده است
هدف اصلی این پروژه ایجاد یک بستر برای توسعه ی پروژه و ایجاد ocr فارسی میباشد که در اقدامات اینده پیش بینی میشود
ابزار به کار گرفته شده در این پروژه الگوریتم های یادگیری عمیق و استفاده از فریم وورک tensor flow/keras و شبکه های cnn, rnn میباشد
جمع اوری مجموعه داده
لازم به ذکر است که جمع اوری داده بصورت دستی و توسط برنامه نویسان پروژه صورت گرفته
بدین صورت که 436 دست خط متفاوت از اشخاص گوناگون جمع اوری شده و در نهایت مجموعه داده شامل 13402 عکس از دستنویس نام شهرهای ایران میباشد
بدین صورت که حدود 16% داده از اقایان به رنج سنی 16 تا 22
و حدود 22% داده از خانم ها به رنج سنی 10تا 12
و حدود 62% داده از خانم ها به رنج سنی 16 تا 22 می باشد
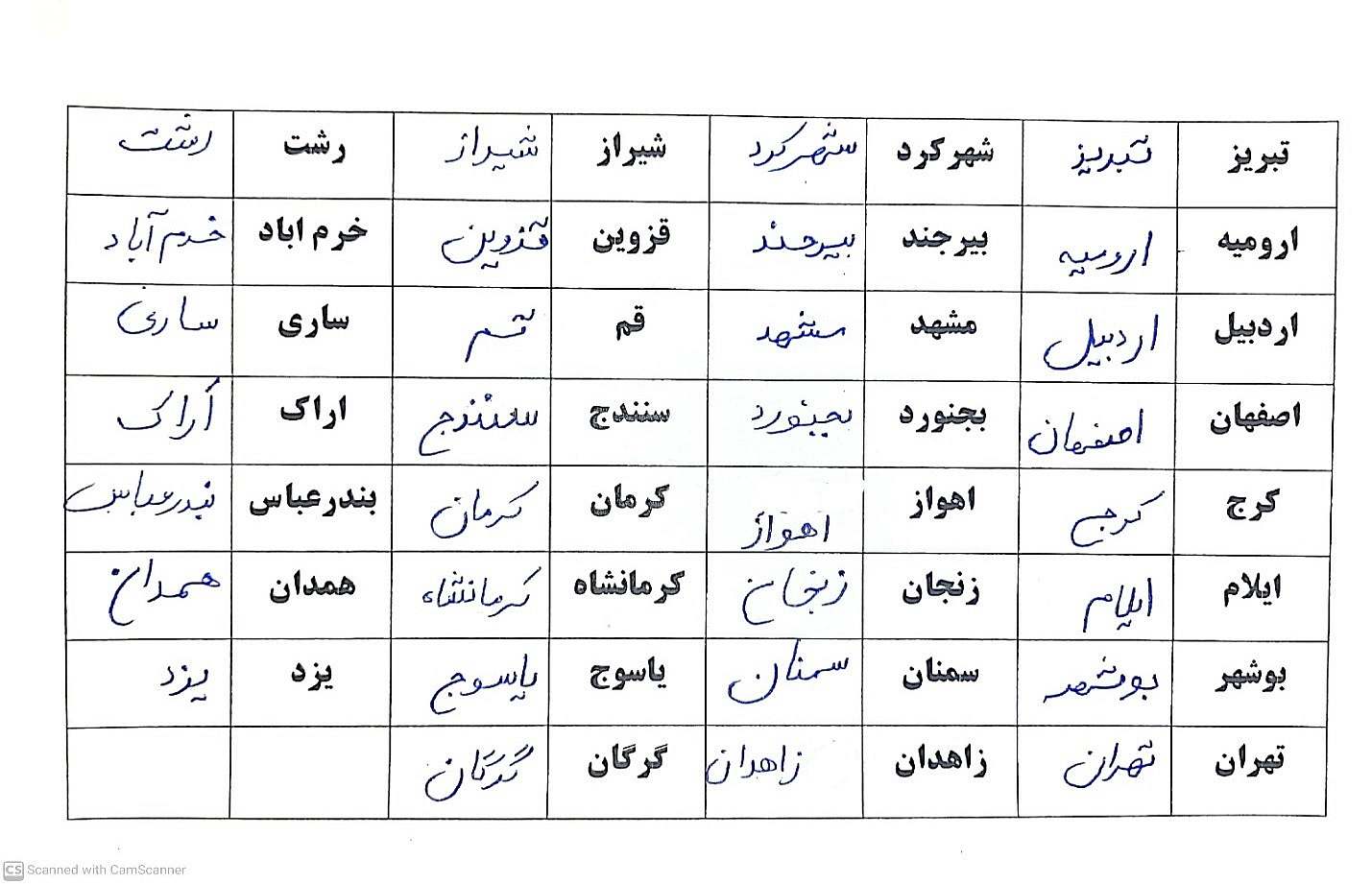
نمونه دیتا جمع اوری شده :
 مراحل پروژه
مراحل پروژه
- جمع اوری داده
- Preprocess داده های جمع اوری شده
- ساخت مدل برای تشخیص دست نویس نام شهر ها
- مقایسه و بهبود مدل
- تست گرفتن از مدل
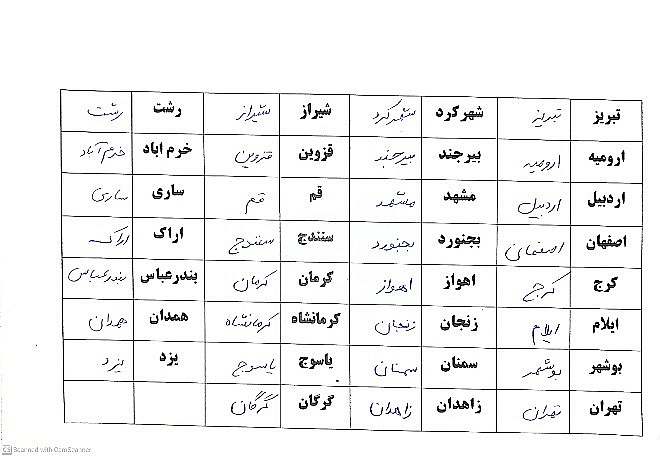 خروجی ImageProcessor :
خروجی ImageProcessor :
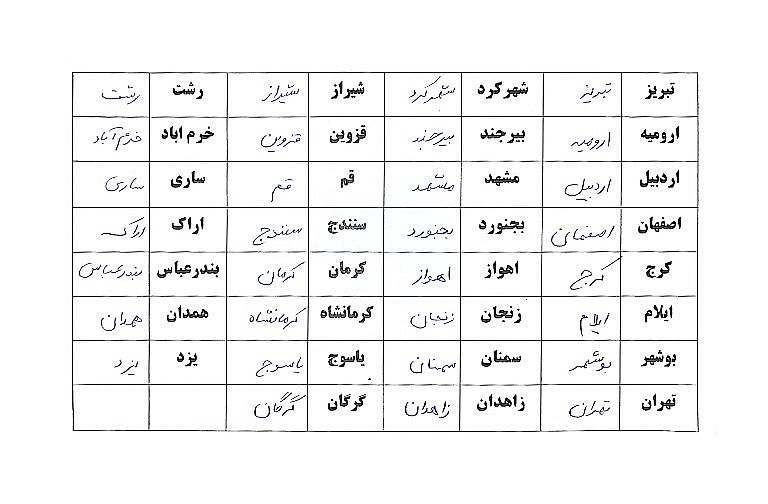
سپس 31 خانه جدول که حاوی دستنویس فارسی شهرهای ایران است را از جدول با لیبل های 0 تا 30 استخراج کرده
بدین صورت که تمام خانه های جدول با لیبل 0 بصورت یکپارچه دستنویس یک شهر مشخص و منحصر بفرد از لیبل های دیگر میباشد
نمونه خانه کراپ شده از جدول:
 در مرحله بعد با خواندن عکس های موجود در 31 فولدر برچسب گذاری شده ارایه numpy از عکس های ورودی به همراه labels از ارایه های onehot شده هر image میسازیم و سپس جهت خوانش جهت دار داداه ها که از راست به چپ و به صورت افقی خوانده و بررسی میشود ارایه تصاویر را resize(100,50) وسپسtranspose میکنیم
در مرحله بعد با خواندن عکس های موجود در 31 فولدر برچسب گذاری شده ارایه numpy از عکس های ورودی به همراه labels از ارایه های onehot شده هر image میسازیم و سپس جهت خوانش جهت دار داداه ها که از راست به چپ و به صورت افقی خوانده و بررسی میشود ارایه تصاویر را resize(100,50) وسپسtranspose میکنیم

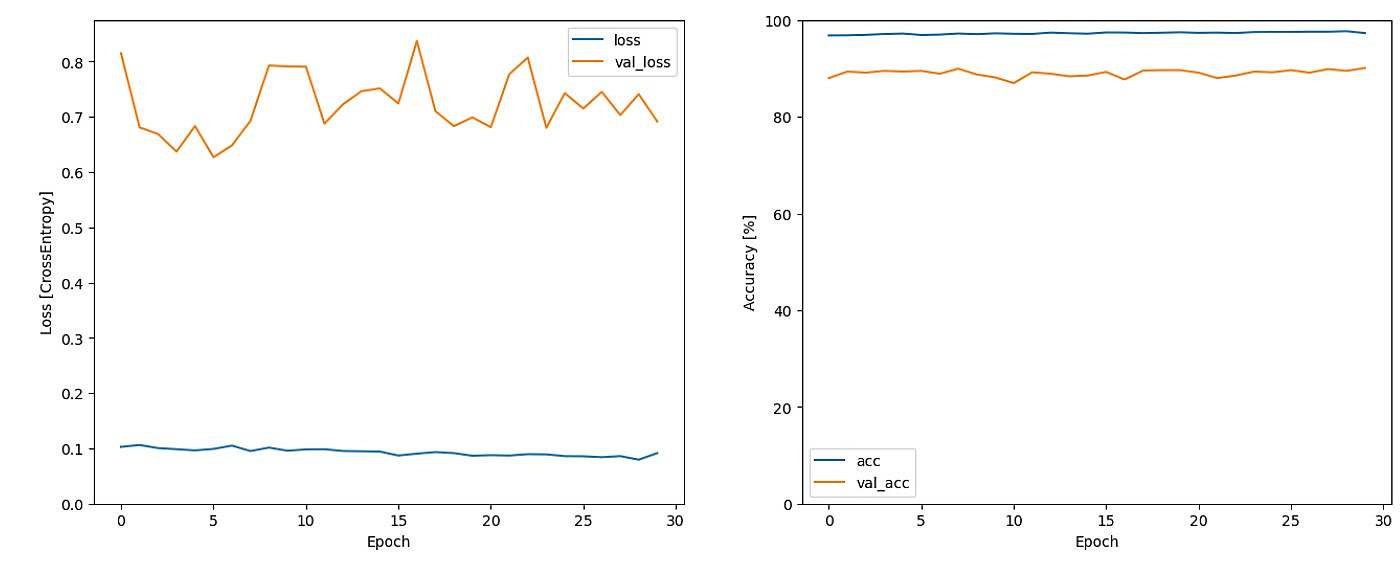 تست گرفتن از مدل
برای نمایش نتایج تست گرفته شده از مدل از بخش test جداشده در ابتدای پروژه که قبلا توسط مدل دیده نشده بهره میبریم تا نتایج نهایی در شرایطی نزدیک به واقعیت سنجیده شود
در این بخش precision,recall,f1 score وهمچنین cinfusion matrix مدل جهت قیاس به نمای گذاشته می شود
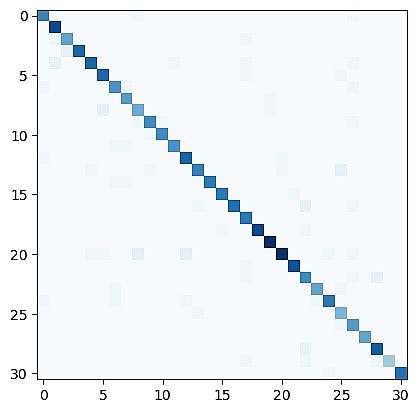
لازم به ذکر است که شماره های 0 تا 30 لیبل 31 شهر موجود در داده ها می باشند
تست گرفتن از مدل
برای نمایش نتایج تست گرفته شده از مدل از بخش test جداشده در ابتدای پروژه که قبلا توسط مدل دیده نشده بهره میبریم تا نتایج نهایی در شرایطی نزدیک به واقعیت سنجیده شود
در این بخش precision,recall,f1 score وهمچنین cinfusion matrix مدل جهت قیاس به نمای گذاشته می شود
لازم به ذکر است که شماره های 0 تا 30 لیبل 31 شهر موجود در داده ها می باشند
Accuracy: 0.90
Classification Report:
precision recall f1-score support
0 0.86 0.90 0.88 21
1 0.89 1.00 0.94 25
2 0.88 0.88 0.88 17
3 1.00 0.92 0.96 24
4 0.92 0.81 0.86 27
5 0.88 0.92 0.90 24
6 0.81 0.85 0.83 20
7 0.84 0.94 0.89 17
8 0.78 0.82 0.80 17
9 0.90 0.86 0.88 21
10 0.95 0.95 0.95 19
11 0.94 0.89 0.92 19
12 0.88 0.92 0.90 24
13 0.90 0.79 0.84 24
14 1.00 0.91 0.95 22
15 0.95 0.95 0.95 21
16 1.00 0.84 0.91 25
17 0.77 1.00 0.87 20
18 1.00 0.93 0.96 27
19 0.93 1.00 0.97 28
20 0.93 0.78 0.85 36
21 0.96 0.96 0.96 25
22 0.75 0.82 0.78 22
23 0.94 0.88 0.91 17
24 0.91 0.83 0.87 24
25 0.72 0.93 0.81 14
26 0.70 0.94 0.80 17
27 1.00 1.00 1.00 15
28 0.88 0.92 0.90 25
29 1.00 0.77 0.87 13
30 1.00 0.95 0.98 22
accuracy 0.90 672
macro avg 0.90 0.90 0.90 672
weighted avg 0.91 0.90 0.90 672
Confusion Matrix