Detect AI Generated And Real Images

مقدمه:
با پیشرفت فناوری و گسترش ابزارهای هوش مصنوعی، تولید و ویرایش عکسها با استفاده از این ابزارها به سرعت در حال رشد است. این پیشرفتها، امکان ایجاد تصاویر با کیفیت بالا و واقعیتر از همیشه را فراهم کردهاند. اما در عین حال، تمایز بین عکسهای ساخته شده توسط هوش مصنوعی و عکسهای گرفته شده توسط انسان به یک چالش پیچیده تبدیل شده است. تشخیص صحیح این تصاویر، به ویژه در حوزههایی مانند رسانهها، تبلیغات و حتی پژوهشهای علمی، اهمیت زیادی دارد. در این گزارش، به بررسی روشها و تکنیکهای مختلف برای طبقهبندی عکسها بر اساس منبع تولید آنها میپردازیم و چالشهایی که در این زمینه وجود دارد را مرور خواهیم کرد. این بررسی میتواند به روشنتر شدن آیندهی این فناوری و نحوهی برخورد با آن کمک کند. در ابتدای راه لازم است دربارهی شبکه عصبی Efficentnet صحبت شود، چون ما برای حل این مسئله از این شبکه استفاده کردهایم پس بررسی میکنیم چرا این مدل شبکه برای این نوع مسئله مناسب است سپس یک دیتاست بزرگ را با این شبکه train میکنیم.
در ابتدای راه لازم است دربارهی شبکه عصبی Efficentnet صحبت شود، چون ما برای حل این مسئله از این شبکه استفاده کردهایم پس بررسی میکنیم چرا این مدل شبکه برای این نوع مسئله مناسب است سپس یک دیتاست بزرگ را با این شبکه train میکنیم.
شبکه EfficentNet:
در طراحی معماریهای شبکههای عصبی کانولوشنی، سه روش اصلی برای افزایش دقت و بهبود عملکرد وجود دارد: افزایش عمق شبکه، افزایش ارتفاع شبکه، و افزایش رزولوشن ورودی. هر یک از این ویژگیها به تنهایی میتواند به بهبود عملکرد شبکه کمک کند، اما تأثیر واقعی زمانی به اوج خود میرسد که این ویژگیها به صورت هماهنگ با یکدیگر به کار گرفته شوند. بدیهی است که این سه ویژگی با یکدیگر ارتباط مستقیمی دارند؛ به عنوان مثال، با افزایش رزولوشن ورودی، شبکه قادر است ویژگیهای بیشتری را بررسی کند که این امر به نوبه خود امکان افزایش عمق شبکه را فراهم میآورد. معماری EfficientNet را میتوان به عنوان روشی برای جستجو و یافتن کارآمدترین شبکه عصبی با توجه به میزان توان محاسباتی در دسترس در نظر گرفت. این معماری با بهینهسازی همزمان عمق، ارتفاع، و رزولوشن، به دستاوردهای چشمگیری در بهبود عملکرد شبکههای عصبی دست یافته است. در شکل زیر می توانیم شمای کلی ازین شبکه مشاهده کنید: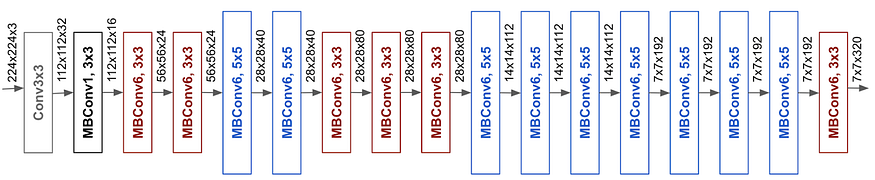 با توجه به این که دستگاههای مختلف از توان پردازشی متفاوتی برخوردارند، لازم است روشی داشته باشیم که با استفاده از آن بتوان شبکه را بر اساس دستگاه موجود و توان پردازشی آن تنظیم کرد. همچنین، اگر زمان آموزش شبکه را نیز مد نظر قرار دهیم، با کاهش مقیاس شبکه (scale down)، زمان آموزش کاهش مییابد و بالعکس، با افزایش مقیاس شبکه (scale up)، زمان آموزش طولانیتر خواهد شد.
برای مثال، اگر هدف این باشد که شبکه ما سریعتر آموزش ببیند و کاهش دقت در نتایج مسئلهی چندان مهمی نباشد، میتوان از این روش استفاده کرد. EfficientNet در واقع راهی برای یافتن بهینهترین مقیاس برای تنظیم شبکه بر اساس شرایط موجود است.
بنابراین، EfficientNet یک رویکرد موثر برای بهینهسازی و تنظیم مقیاس شبکههای عصبی با توجه به شرایط سختافزاری و زمانی است که میتواند به بهبود عملکرد شبکهها در موقعیتهای مختلف کمک کند.
در ادامه، به معرفی متد معروف به نام Compound Scaling Method میپردازیم. این روش به عنوان یک مسئله بهینهسازی مطرح میشود که میتوان آن را به صورت فرمول زیر بیان کرد. در این فرمول، مقادیر آلفا (α)، بتا (β) و گاما (γ) به عنوان مقادیر ثابت در نظر گرفته میشوند که با استفاده از یک جستجوی شبکهای (grid search) میتوان آنها را به دست آورد.
فرمول Compound Scaling به این صورت عمل میکند که اگر هزینه محاسباتی را با یک ضریب ثابت افزایش دهیم، مقدار phi (φ) را نیز تغییر میدهیم. این متد به ما امکان میدهد که با تنظیم مقادیر α، β و γ، شبکه را بهینهسازی کنیم و بهترین عملکرد ممکن را با توجه به محدودیتهای محاسباتی موجود به دست آوریم.
این رویکرد با افزایش همزمان عمق، عرض و رزولوشن شبکه، تعادلی بین این سه ویژگی برقرار میکند تا شبکههای عصبی بهینهتری ایجاد شود. Compound Scaling Method در واقع به دنبال این است که با توجه به منابع محاسباتی موجود، بهینهترین مقیاس برای شبکههای عصبی را پیدا کند و عملکرد آنها را به حداکثر برساند.
با توجه به این که دستگاههای مختلف از توان پردازشی متفاوتی برخوردارند، لازم است روشی داشته باشیم که با استفاده از آن بتوان شبکه را بر اساس دستگاه موجود و توان پردازشی آن تنظیم کرد. همچنین، اگر زمان آموزش شبکه را نیز مد نظر قرار دهیم، با کاهش مقیاس شبکه (scale down)، زمان آموزش کاهش مییابد و بالعکس، با افزایش مقیاس شبکه (scale up)، زمان آموزش طولانیتر خواهد شد.
برای مثال، اگر هدف این باشد که شبکه ما سریعتر آموزش ببیند و کاهش دقت در نتایج مسئلهی چندان مهمی نباشد، میتوان از این روش استفاده کرد. EfficientNet در واقع راهی برای یافتن بهینهترین مقیاس برای تنظیم شبکه بر اساس شرایط موجود است.
بنابراین، EfficientNet یک رویکرد موثر برای بهینهسازی و تنظیم مقیاس شبکههای عصبی با توجه به شرایط سختافزاری و زمانی است که میتواند به بهبود عملکرد شبکهها در موقعیتهای مختلف کمک کند.
در ادامه، به معرفی متد معروف به نام Compound Scaling Method میپردازیم. این روش به عنوان یک مسئله بهینهسازی مطرح میشود که میتوان آن را به صورت فرمول زیر بیان کرد. در این فرمول، مقادیر آلفا (α)، بتا (β) و گاما (γ) به عنوان مقادیر ثابت در نظر گرفته میشوند که با استفاده از یک جستجوی شبکهای (grid search) میتوان آنها را به دست آورد.
فرمول Compound Scaling به این صورت عمل میکند که اگر هزینه محاسباتی را با یک ضریب ثابت افزایش دهیم، مقدار phi (φ) را نیز تغییر میدهیم. این متد به ما امکان میدهد که با تنظیم مقادیر α، β و γ، شبکه را بهینهسازی کنیم و بهترین عملکرد ممکن را با توجه به محدودیتهای محاسباتی موجود به دست آوریم.
این رویکرد با افزایش همزمان عمق، عرض و رزولوشن شبکه، تعادلی بین این سه ویژگی برقرار میکند تا شبکههای عصبی بهینهتری ایجاد شود. Compound Scaling Method در واقع به دنبال این است که با توجه به منابع محاسباتی موجود، بهینهترین مقیاس برای شبکههای عصبی را پیدا کند و عملکرد آنها را به حداکثر برساند.
ورژن baseline:
معماری که به عنوان baseline (خط مبنا) در نظر گرفته میشود از اهمیت بسیاری برخوردار است، زیرا در روش EfficientNet، معماری baseline تغییر نمیکند بلکه صرفاً مقیاسبندی میشود. برای مثال، اگر AlexNet به عنوان baseline استفاده شود، پس از اعمال تغییرات در مقیاس با استفاده از عرض، طول و رزولوشن، نتایج حاصل از همان AlexNet مقایسه میشود و با شبکه دیگری مانند ResNet مقایسه نمیشود. بنابراین، داشتن یک baseline مناسب اهمیت ویژهای دارد. EfficientNet دارای هفت نسخه مختلف است. ابتدا نسخه B0 با استفاده از روش و معماری معرفی شده به دست میآید و به عنوان baseline در نظر گرفته میشود. سپس با دو گام مقیاسبندی، نسخههای دیگر (B1 تا B7) به دست میآیند. این نسخهها با اعمال مقیاسبندیهای مختلف، عملکرد شبکه را بهینهسازی میکنند و باعث میشوند شبکههای عصبی با توان محاسباتی و منابع موجود بهترین کارایی را داشته باشند. این روش مقیاسبندی موثر، بهینهسازی همزمان سه عامل عمق، عرض و رزولوشن را امکانپذیر میسازد و باعث ایجاد شبکههایی کارآمدتر و با دقت بالاتر میشود. ما در مثالی که خواهیم زد از ورژن 2 آن استفاده میکنیم.EfficientNet-B1
نسخه B1 شبکه EfficientNet، بر پایه نسخه اولیه B0 ساخته شده است. در این نسخه، پارامترهای مقیاسبندی به گونهای تنظیم شدهاند که بهینهترین ترکیب ممکن از عمق، عرض و رزولوشن به دست آید. با اعمال این تغییرات، شبکه B1 نسبت به B0 از عمق بیشتری برخوردار است که باعث میشود ویژگیهای پیچیدهتری را استخراج کند. همچنین، عرض شبکه نیز افزایش یافته که به آن اجازه میدهد جزئیات بیشتری از دادهها را پردازش کند. علاوه بر این، رزولوشن ورودیها نیز افزایش یافته که منجر به دقت بالاتری در شناسایی و طبقهبندی تصاویر میشود. تمامی این بهینهسازیها با حفظ تعادل بین پارامترها انجام شده است تا بدون افزایش بیش از حد هزینههای محاسباتی، کارایی شبکه بهبود یابد.EfficientNet-B2
نسخه B2 شبکه EfficientNet، تکاملیافتهتر از نسخه B1 است و با هدف بهبود بیشتر دقت و کارایی شبکه توسعه یافته است. در این نسخه، پارامترهای مقیاسبندی به طور دقیقتری تنظیم شدهاند. عمق شبکه در B2 باز هم افزایش یافته که امکان شناسایی ویژگیهای حتی پیچیدهتر را فراهم میکند. عرض شبکه نیز بیشتر شده که به شبکه اجازه میدهد با ظرفیت بیشتری دادهها را پردازش کند. رزولوشن ورودیها نیز در این نسخه بیشتر شده که دقت تشخیص شبکه را به میزان قابل توجهی افزایش میدهد. این تغییرات باعث میشود که نسخه B2، نسبت به نسخههای قبلی خود، عملکرد بهتری داشته باشد و بتواند با دقت بیشتری تصاویر را طبقهبندی کند. این شبکه تا ورژن B7 تکامل پیدا کرد که به عنوان به عنوان پیشرفتهترین و بهینهترین نسخه شبکه EfficientNet شناخته میشود. در شکل زیر میتوان مقایسه کلی بین این شبکهها داشت:تشخیص عکس با استفاده از شبکه EfficientNetB2:
حال بهتر است مقداری وارد دنیای عمل شویم و از شبکه EfficentNet برای حل مسئله ابتدای مقاله کمک بگیریم.دیتاست:
در این مرحله ما از یک دیتاست تقریبا بزرگ به حجم 16 گیگابایت استفاده میکنیم عکس ها لیبلگذاری شدهاند و در پوشه real , ai قرار گرفته اند. عکس ها از کیفیت قابل قبولی برخوردار هستند. نمونه دو عکس با لیبل real, AI در تصاویر زیر قابل رویت هستند. '
 با توجه به اینکه حجم عکس ها زیاد می باشد بارگزاری تمام عکس ها درون رم غیرمنطقی به نظر می رسد پس بهتر است از جنریتورهای کراس استفاده کنیم طبق کد زیر
با توجه به اینکه حجم عکس ها زیاد می باشد بارگزاری تمام عکس ها درون رم غیرمنطقی به نظر می رسد پس بهتر است از جنریتورهای کراس استفاده کنیم طبق کد زیر
train_datagen = ImageDataGenerator( rescale=1./255, shear_range=0.2, zoom_range=0.2, horizontal_flip=True, validation_split=0.2, ) train_generator = train_datagen.flow_from_directory( DATASET_DIR, target_size=(260, 260), batch_size=8, class_mode='binary', subset='training') validation_generator = train_datagen.flow_from_directory( DATASET_DIR, target_size=(260, 260), batch_size=8, class_mode='binary', subset='validation')با توجه به اینکه اندازه و کیفیت عکس های نباید افت کند سایز ورودی را 260 * 260 در نظر گرفتیم
policy = mixed_precision.Policy('mixed_float16')
mixed_precision.set_global_policy(policy)
استفاده از این دو خط کد در کتابخانه TensorFlow برای تنظیم سیاست دقت مخلوط (mixed precision) است. این روش به شما امکان میدهد تا از دقت اعشاری نیمهکاره (float16) به جای دقت کامل اعشاری (float32) استفاده کنید، که میتواند تأثیرات مهمی بر مصرف حافظه RAM و عملکرد شبکههای عصبی دیپ لرنینگ داشته باشد:
- کاهش مصرف رم: دادهها در دقت
float16نصف حجم دادههایfloat32را اشغال میکنند. این کاهش حجم باعث میشود که مصرف حافظه RAM کاهش یابد. این امر بخصوص در مدلهای بزرگ که نیاز به مقادیر زیادی حافظه دارند، مفید است. - افزایش سرعت اجرا: بسیاری از پردازندهها، به خصوص GPUها، برای محاسبات با دقت کمتر بهینهسازی شدهاند. استفاده از
float16میتواند باعث افزایش سرعت محاسبات شود، زیرا پردازنده میتواند در یک زمان مشخص، محاسبات بیشتری را انجام دهد.
ساخت و trainکردن مدل:
# Load EfficientNetB4 without the top layer base_model = EfficientNetB2(weights='imagenet', include_top=False, input_shape=(260, 260, 3)) # Add custom layers x = base_model.output x = GlobalAveragePooling2D()(x) x = Dense(1024, activation='relu')(x) predictions = Dense(1, activation='sigmoid')(x) # Create the final model model = Model(inputs=base_model.input, outputs=predictions) # Freeze all layers in the base model for layer in base_model.layers: layer.trainable = False # Compile the model model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy']) # Train the model model.fit( train_generator, epochs=10, validation_data=validation_generator ) # Unfreeze all layers for layer in base_model.layers: layer.trainable = True # Re-compile the model with a lower learning rate model.compile(optimizer=tf.keras.optimizers.Adam(1e-5), loss='binary_crossentropy', metrics=['accuracy']) # Fine-tune the model model.fit( train_generator, epochs=10, validation_data=validation_generator )بیایید عمیقتر به جزئیات هر بخش از کدی که توضیح داده شد بپردازیم تا دلایل و مکانیزمهای زیربنایی را بهتر درک کنیم:
بارگذاری مدل پایه
EfficientNetB2
EfficientNetB2 یکی از اعضای خانواده مدلهای EfficientNet است، که برای کارآمدی بالا در تعداد پارامترها و سرعت محاسبات طراحی شدهاند. استفاده از این مدل با وزنهای آموزشدیده روی دیتاست بزرگ ImageNet به ما اجازه میدهد تا از دانش پیشینی که این مدل در تشخیص تصاویر بسیار متنوع به دست آورده، استفاده کنیم.بدون لایههای بالایی
با حذف لایههای طبقهبندی بالایی، ما این امکان را به دست میآوریم که مدل را برای وظایف مختلف و دادههایی با تعداد دستههای متفاوت از ImageNet سفارشیسازی کنیم.input_shape نشاندهنده ابعاد ورودیهای مورد نیاز مدل است که در این مورد 260x260x3 است.
افزودن لایههای سفارشی
Global Average Pooling 2D
این لایه نقش مهمی در فشردهسازی ویژگیهای استخراجشده توسط مدل پایه را بازی میکند. به جای استفاده از یک لایه Flatten که ممکن است باعث افزایش تعداد پارامترها و افزایش خطر بیشبرازش شود، Global Average Pooling میانگین ویژگیها در هر کانال را محاسبه میکند و به یک بردار ویژگی فشرده تبدیل میکند.Dense Layers
لایههای Dense برای یادگیری نمایشهای سطح بالاتر که به طبقهبندی نهایی کمک میکنند استفاده میشود. اولین لایه Dense با 1024 نورون بهعنوان یک لایه تماما متصل عمل میکند که میتواند پیچیدگیهای دادهها را مدلسازی کند. لایه آخر با تابع فعالسازی سیگموئید برای تولید خروجی دودویی در مسائل طبقهبندی دودویی استفاده میشود.تنظیم و آموزش اولیه
Freezing Layers
یخزدایی لایهها اجازه نمیدهد وزنهای مدل پایه در طول آموزش اولیه تغییر کنند. این کار از دست دادن دانش عمومی که مدل از ImageNet به دست آورده جلوگیری میکند و همچنین سرعت آموزش را بهبود میبخشد.آموزش دقیقتر (Fine-tuning)
Trainable Layers
پس از اینکه مدل اولیه با لایههای جدید آموزش دید و وزنهای آنها بهینه شد، لایههای مدل پایه دوباره قابل آموزش میشوند. این اجازه میدهد که مدل بتواند ویژگیهای خاص دادههای جدید را بیاموزد و دقت مدل را در شرایط خاص آن مجموعه داده افزایش دهد.Re-compilation with Lower Learning Rate
بازکامپایل کردن مدل با نرخ یادگیری پایینتر به این معناست که تغییرات در وزنهای مدل دقیقتر و کنترل شدهتر انجام میشود. این کمک میکند تا یادگیریهای قبلی حفظ شوند و مدل به تدریج و با ثبات بهینهسازی شود. در نتیجه، این فرایند دو مرحلهای (آموزش اولیه و تنظیم دقیق) به افزایش توانایی مدل در درک و تمایز بهتر دادهها کمک میکند و اطمینان حاصل میکند که مدل میتواند از دانش عمومی و خاص بهطور مؤثر استفاده کند. در شکل بعدی دقت نهایی در دورهای آخر نشان داده شده است: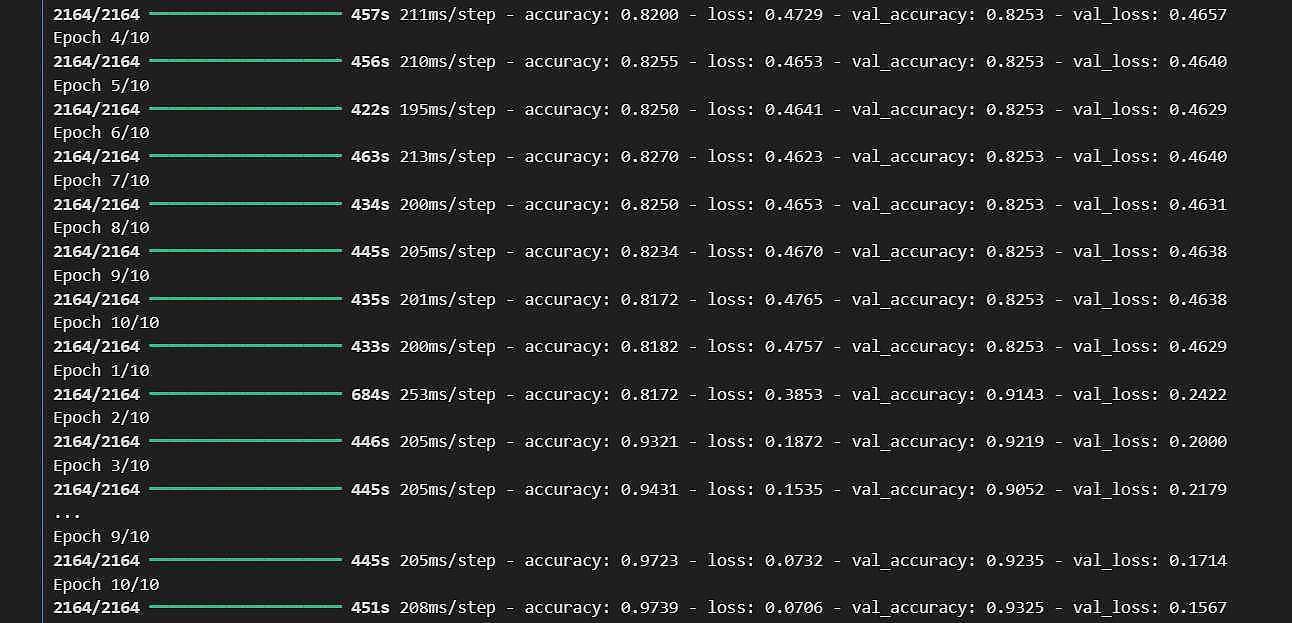 همانطور که مشاهده می شود دقت بر روی داده validation به حدود 93% رسیده است.
همانطور که مشاهده می شود دقت بر روی داده validation به حدود 93% رسیده است.
برچسب ها :
classification