Text classification, recognition of positive and negative Persian comments

عنوان پروژه: پردازش متون فارسی، تشخیص کامنت های مثبت و منفی مقدمه و اهداف: در این پروژه، هدف، بررسی و تحلیل نظرات کاربران فارسیزبان در فیلم، سریال، انیمه و انیمیشن با استفاده از روشهای یادگیری عمیق است. این پروژه شامل دو مدل اصلی میشود: یک مدل با استفاده از شبکههای عصبی بازگشتی (RNN) (با استفاده از یک لایه LSTM) و یک مدل با استفاده از شبکههای عصبی کانولوشنی (CNN) (از طریق کانولوشن یک بعدی) که در نهایت این دو مدل با هم مقایسه شده اند. توضیح کلی از فرایند پروژه: دیتاست شامل دو پوشه Negative و Positive است که کامنت ها در آنها در فایل های txt جدا از هم به صورت label.index ذخیره شده است. پس از بارگذاری دیتاست، ابتدا فایل های خالی درون آن حذف، سپس نظرات در review و لیبل ها در labels ذخیره می شوند (فایل های موجود در پوشه Negative با لیبل 0 و فایل های موجود در پوشه Positive با لیبل 1). سپس فایل های تکراری را حذف میکنیم و فایل های باقی مانده را براساس طول کامنت ها sort می کنیم. داده ها را به دو دسته آزمون و آزمایش تقسیم بندی کرده و بعد از پیش پردازش داده ها و تشکلیل train_ds و val_ds، مدل ها را تشکیل داده و کامپایل و fit می کنیم. در این پروژه تعداد داده های جمع آوری شده 2500 داده بوده که تعداد کمی محسوب می شود پس داده ها جوری پیش پردازش شده اند که هنگام فیت شدن مدل overfit کاهش پیدا کند و به درصد دقت نسبی بالای 80 درصد برسد.
train_ds = tf.data.Dataset.from_tensor_slices((X_train, y_train)) train_ds = train_ds.map(vectorization, num_parallel_calls=AUTOTUNE) train_ds = train_ds.cache() train_ds = train_ds.shuffle(BUFFER_SIZE) train_ds = train_ds.padded_batch(BATCH_SIZE, drop_remainder=True, padding_values=(fa_tokenizer.pad_token_id, 0)) train_ds = train_ds.shuffle(STEPS_PER_EPOCH) train_ds = train_ds.prefetch(AUTOTUNE) val_ds = tf.data.Dataset.from_tensor_slices((X_test, y_test)) val_ds = val_ds.map(vectorization, num_parallel_calls=AUTOTUNE) val_ds = val_ds.cache() val_ds = val_ds.padded_batch(BATCH_SIZE, drop_remainder=True, padding_values=(fa_tokenizer.pad_token_id, 0)) val_ds = val_ds.prefetch(AUTOTUNE)ورودی های پروژه:
- مجموعه دادهها
- فایل فشرده نظرات کاربران: این فایل شامل نظرات فارسی کاربران در دو دسته مثبت و منفی است (پوشه Positive و Negative). داده ها به صورت index در فایل های متنی جدا ذخیره شده اند.
- کتابخانهها و ابزارهای مورد استفاده
- Tokenizer
- توکنایزر مدل AutoTokenizer فارسی برای تبدیل متن به توکنهای عددی، مدل bolbolzaban/gpt2-persian
- تنظیمات مدل و پارامترها
- تنظیمات عمومی:
- پارامترهای مدلها:
- دادههای ورودی جدید برای پیشبینی
- توابع و کدهای مورد استفاده
- Embedding Layer
- Bidirectional LSTM Layer
- Dense Layer (Fully Connected)
- Dropout Layer
- Dropout Layer
- Output Layer (Dense Layer)
model = tf.keras.Sequential([ tf.keras.layers.Embedding( input_dim=len(fa_tokenizer.get_vocab()), output_dim=128, mask_zero=True), tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64)), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dropout(0.3), tf.keras.layers.Dense(2) ])Loss Function (masked_loss_function)
- y_true : برچسبهای واقعی که به عنوان ورودی به مدل داده میشوند.
- pred : پیشبینیهای مدل برای برچسبها.
- loss_object : تابع خطای اصلی که در اینجا SparseCategoricalCrossentropy است.
- pad_token_id : توکن پدینگ مورد استفاده برای توکنهای پدینگ در دادهها.
- mask: یک ماسک برای نادیده گرفتن توکنهای پدینگ ایجاد میشود.
- masked_loss: خطای محاسبه شده با در نظر گرفتن ماسک.
loss_object = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True) acc_object = tf.keras.metrics.Accuracy() def masked_loss_function(y_true, pred): loss = loss_object(y_true, pred) mask = tf.cast(tf.not_equal(y_true, fa_tokenizer.pad_token_id), dtype=loss.dtype) masked_loss = tf.reduce_sum(loss * mask) / tf.reduce_sum(mask) return masked_lossAccuracy Metric (MaskedAccuracy)
- برای اندازهگیری دقت مدل با استفاده از ماسک (نادیده گرفتن توکنهای پدینگ)، کلاس MaskedAccuracy تعریف شده است.
- update_state: در این متد، پیشبینیهای مدل به صورت label ids تبدیل میشوند و یک ماسک برای نادیده گرفتن توکنهای پدینگ اعمال میشود. سپس دقت به وسیلهی متریک دقت (Accuracy) که در constructor کلاس تعریف شده است، به روزرسانی میشود.
- result: این متد نتیجهی دقت محاسبه شده را برمیگرداند.
- reset_state: با استفاده از این متد، وضعیت متریک دقت ریست میشود.
class MaskedAccuracy(tf.keras.metrics.Metric): def __init__(self, name='masked_accuracy', **kwargs): super(MaskedAccuracy, self).__init__(name=name, **kwargs) self.acc_object = tf.keras.metrics.Accuracy() def update_state(self, y_true, y_pred, sample_weight=None): # Convert predictions to label ids y_pred = tf.argmax(y_pred, axis=-1) # Create a mask to ignore padding tokens mask = tf.logical_not(tf.equal(y_true, fa_tokenizer.pad_token_id)) # Cast the mask to int32 and squeeze to ensure correct shape mask = tf.cast(mask, tf.int32) mask = tf.squeeze(mask, axis=-1) # Apply the mask to y_true and y_pred y_true = tf.boolean_mask(y_true, mask) y_pred = tf.boolean_mask(y_pred, mask) # Update the accuracy metric self.acc_object.update_state(y_true, y_pred) def result(self): return self.acc_object.result() def reset_state(self): self.acc_object.reset_states() # Instantiate the custom metric masked_accuracy_metric = MaskedAccuracy() # Compile the model with the custom masked accuracy metric model.compile( loss=masked_loss_function, optimizer=tf.keras.optimizers.Adam(1e-2), metrics=[masked_accuracy_metric] )بررسی مدل CNN (Conv1D)
- Embedding Layer
- Conv1D Layer
- GlobalMaxPooling1D Laye
- Dense Layer (Fully Connected)
- Dropout Layer
- Output Layer (Dense Layer)
model_2 = tf.keras.Sequential([ tf.keras.layers.Embedding( input_dim=len(fa_tokenizer.get_vocab()), output_dim=128, mask_zero=True), tf.keras.layers.Conv1D(128, 5, activation='relu'), tf.keras.layers.GlobalMaxPooling1D(), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dropout(0.3), tf.keras.layers.Dense(2) ])تنظیمات اولیهی آموزش مدل ها:
- استفاده از متد fit برا آموزش
epochs = 30 early_stopping_patience = 10 reduce_lr_patience = 3 early_stopping = keras.callbacks.EarlyStopping( monitor="val_loss", patience=early_stopping_patience, restore_best_weights=True ) reduce_lr = keras.callbacks.ReduceLROnPlateau(monitor='val_loss', factor=0.6, patience=reduce_lr_patience) history = model.fit( train_ds, validation_data=val_ds, epochs=epochs, callbacks=[early_stopping, reduce_lr], )(در مدل CNN، نام مدل به model_2 و نام history به history_2 تغییر پیدا می کند) خروجی های پروژه:
- خروجیهای پیشپردازش دادهها
- خروجیهای مدل ها
- خروجی مدل CNN (Conv1D):
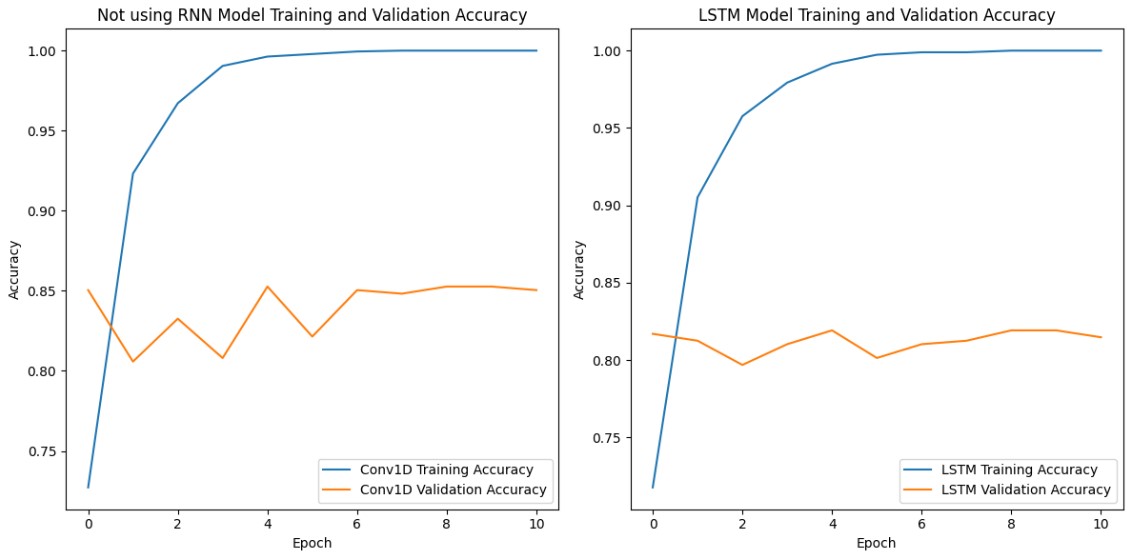 همانطور که مشاهده می شود، دقت در مدل CNN 4 درصد نسبت به RNN بهتر است که نشان از عملکرد بهتر ان روی داده های کمتر این پروژه دارد؛ به دلیل کم بودن داده ها، overfit شدن بدیهی است، اما تلاش شده تا با استفاده از preprocessing و مدل مناسب، مقدار آن کاهش یابد و دقت نسبی قابل قبولی که بتواند بالای 80 درصد باشد، حاصل شود
Confusion Matrix برای هر مدل:
همانطور که مشاهده می شود، دقت در مدل CNN 4 درصد نسبت به RNN بهتر است که نشان از عملکرد بهتر ان روی داده های کمتر این پروژه دارد؛ به دلیل کم بودن داده ها، overfit شدن بدیهی است، اما تلاش شده تا با استفاده از preprocessing و مدل مناسب، مقدار آن کاهش یابد و دقت نسبی قابل قبولی که بتواند بالای 80 درصد باشد، حاصل شود
Confusion Matrix برای هر مدل:
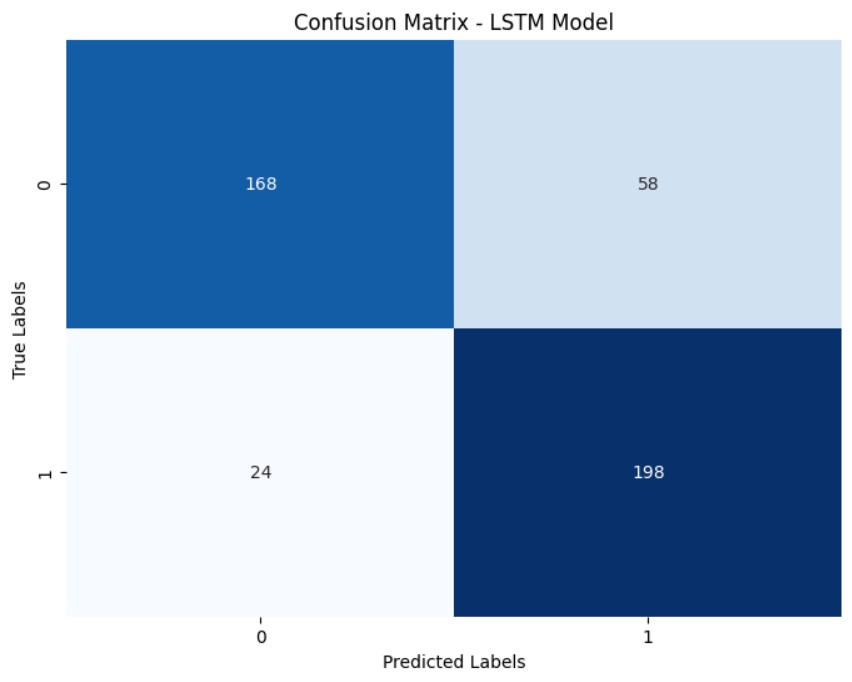
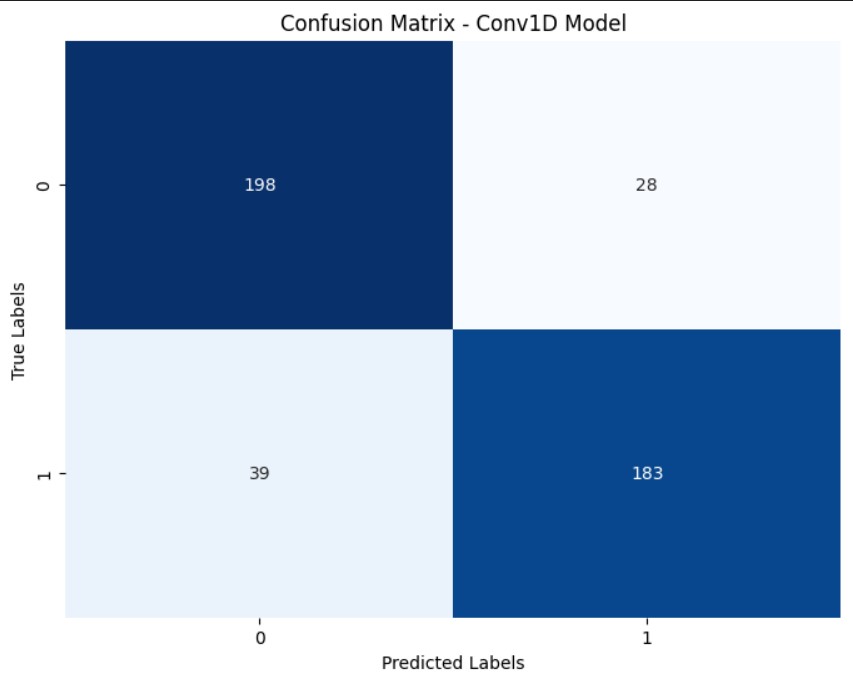 همانطور که مشاهده می شود به طور کلی در این پروژه که داده های کم داریم، مدل CNN وضعیت را بهتر می کند. (درست است که کلاس 1 را مدل LSTM بهتر تشخیص داده اما نسبت به کلاس دیگر فاصله چندانی با مدل CNN ندارد و در مدل CNN وضعیت کلاس هم به طور چشمگیری بهتر می شود). در این پروژه دقت مدل RNN به 81 درصد رسیده اما در مدل CNN دقت تا 4 درصد افزایش یافته و به 85 درصد رسیده است. پس می توان نتیجه گرفت که با توجه به تنظیمات انجام شده در اینجا و تعداد داده های خیلی کم، با مدل CNN می توان به نتیجه نسبتا بهتری رسید. البته انتظار می رود با افزایش تعداد داده ها به طور چشمگیر، دقت در مدل LSTM با توجه به حافظه ترتیبی کوتاه مدت آن، بهتر شود، اما در اینجا با توجه به نتیجه گرفته شده در سطح تعداد داده های کم، CNN (Conv1D) انتخاب بهتری است.
همانطور که مشاهده می شود به طور کلی در این پروژه که داده های کم داریم، مدل CNN وضعیت را بهتر می کند. (درست است که کلاس 1 را مدل LSTM بهتر تشخیص داده اما نسبت به کلاس دیگر فاصله چندانی با مدل CNN ندارد و در مدل CNN وضعیت کلاس هم به طور چشمگیری بهتر می شود). در این پروژه دقت مدل RNN به 81 درصد رسیده اما در مدل CNN دقت تا 4 درصد افزایش یافته و به 85 درصد رسیده است. پس می توان نتیجه گرفت که با توجه به تنظیمات انجام شده در اینجا و تعداد داده های خیلی کم، با مدل CNN می توان به نتیجه نسبتا بهتری رسید. البته انتظار می رود با افزایش تعداد داده ها به طور چشمگیر، دقت در مدل LSTM با توجه به حافظه ترتیبی کوتاه مدت آن، بهتر شود، اما در اینجا با توجه به نتیجه گرفته شده در سطح تعداد داده های کم، CNN (Conv1D) انتخاب بهتری است.