musical instrument classification

musical instrument classification
dataset
در این پروژه قصد داریم صوت سازهای درام، گیتار، پیانو، ویولن را با استفاده از spectrogram کلاسبندی کنیم. این دیتاست شامل دو فایل csv است با نام های Metadata_Train.csv و Metadata_Test.csv است که اطلاعات صوت های train و test در آن نوشته شده است. و همچنین دو پوشه که یکی شامل فایل های wav برای train (Train_submission) و دیگری برای test (Test_submission) است. کد ما نیز از سه فایل preprocessing، model و test ساخته شده است که به نوبت توضیح می دهیم:- Preprocessing: آماده سازی داده ها برای ساخت مدل در این فایل انجام می شود.
بخش اول کد به دلیل وجود مشکلی که مربوط دیتاست بود است. نام صوت های کلاس ویولن به اشتباه نوشته شده بود که در این بخش ابتدا لیستی از اسامی دیتا های مربوط به کلاس ویولن را پیدا کردیم و آن ها را جایگزین اسامی اشتباه می کنیم. و فایل جدید را با نام New_Metadata_Train ذخیره می کنیم.
train_dir = 'Train_submission/Train_submission'
train_names=[]
for dirname, _, filenames in os.walk(train_dir):
for filename in filenames:
if filename[-4:]=='.wav':
train_names+=[filename]
Metadata_Train = pd.read_csv('Metadata_Train.csv')
for index, row in Metadata_Train.iterrows():
file_name = row['FileName']
class_label = row['Class']
if class_label=='Sound_Drum' or class_label=='Sound_Guitar' or class_label=='Sound_Piano':
if row['FileName'] in train_names:
train_names.remove(row['FileName'])
counter=0
for index, row in Metadata_Train.iterrows():
if row['Class']=='Sound_Violin':
Metadata_Train.loc[index, "FileName"]=train_names[counter]
counter+=1
Metadata_Train.head(1000)
Metadata_Train.to_csv('New_Metadata_Train.csv')
با خواندن فایل متادیتا جدید train هر فایل رو به پوشه کلاس خود انتقال می دهد.
source_dir = 'Train_submission/Train_submission'
Metadata_Train = pd.read_csv('New_Metadata_Train.csv')
create_folder_if_not_exists('New_Train')
destination_dir = 'New_Train'
for index, row in Metadata_Train.iterrows():
file_name = row['FileName']
class_label = row['Class']
source_file = os.path.join(source_dir, file_name)
destination_folder = os.path.join(destination_dir, class_label)
create_folder_if_not_exists(destination_folder)
if os.path.exists(source_file):
shutil.copy(source_file, destination_folder)
print("+",end="")
else:
print("_",end="")
این پوشه بندی را برای test نیز انجام می دهد.
بعد تمام فایل ها دیتاست را چک می کنیم که خالی نباشند.
def check_audio_files(data_dir):
for root, dirs, files in os.walk(data_dir):
for file in files:
if file.endswith('.wav'):
file_path = os.path.join(root, file)
with sf.SoundFile(file_path) as f:
if len(f) == 0:
print(".",end="")
else:
print("+",end="")
check_audio_files(destination_dir)
check_audio_files(destination_dir_test)
و در آخر تمام صوت ها را تک کاناله می کنیم.
def convert_to_mono(input_path, output_path):
y, sr = librosa.load(input_path, sr=None, mono=False)
if y.ndim > 1:
y = librosa.to_mono(y)
sf.write(output_path, y, sr)
def preprocess_audio_files(root_directory):
for root, dirs, files in os.walk(root_directory):
for file in files:
if file.endswith('.wav'):
file_path = os.path.join(root, file)
temp_path = os.path.join(root, 'temp_' + file)
convert_to_mono(file_path, temp_path)
os.remove(file_path)
os.rename(temp_path, file_path)
preprocess_audio_files(destination_dir)
preprocess_audio_files(destination_dir_test)
خواندن فایل متادیتا
لود کردن داده ها از پوشه های هر کلاس با audio_dataset_from_directory و چاپ برچسب کلاس ها
destination_dir = 'New_Train'
train_ds, val_ds = tf.keras.utils.audio_dataset_from_directory(
directory=destination_dir,
batch_size=12,
validation_split=0.2,
seed=0,
output_sequence_length=1600000,
subset='both')
تابع squeeze یک بعد آخر را حذف می کند. این تابع را برای داده های train و test صدا میزنیم.
def squeeze(audio, labels):
audio = tf.squeeze(audio, axis=-1)
return audio, labels
داده val_ds را به دو بخش validation و test تقسیم می کند.
این تابع get_spectrogram در TensorFlow برای تبدیل یک سیگنال صوتی به یک spectrogram استفاده میشود. spectrogram یک نمایش گرافیکی از توزیع زمانی-فرکانسی انرژی یک سیگنال صوتی است که برای استفاده در شبکههای عصبی کانولوشنال به عنوان ورودی استفاده میشود.
def get_spectrogram(waveform):
# Convert the waveform to a spectrogram via a STFT.
spectrogram = tf.signal.stft(
waveform, frame_length=255, frame_step=128)
# Obtain the magnitude of the STFT.
spectrogram = tf.abs(spectrogram)
# Add a `channels` dimension, so that the spectrogram can be used
# as image-like input data with convolution layers (which expect
# shape (`batch_size`, `height`, `width`, `channels`).
spectrogram = spectrogram[..., tf.newaxis]
return spectrogram
این تابع برای نمایش یک spectrogram به صورت یک نموداررنگی استفاده میشود.
def plot_spectrogram(spectrogram, ax):
if len(spectrogram.shape) > 2:
assert len(spectrogram.shape) == 3
spectrogram = np.squeeze(spectrogram, axis=-1)
# Convert the frequencies to log scale and transpose, so that the time is
# represented on the x-axis (columns).
# Add an epsilon to avoid taking a log of zero.
log_spec = np.log(spectrogram.T + np.finfo(float).eps)
height = log_spec.shape[0]
width = log_spec.shape[1]
X = np.linspace(0, np.size(spectrogram), num=width, dtype=int)
Y = range(height)
ax.pcolormesh(X, Y, log_spec)
این تابع همه صوت ها را دریافت کرده و آن ها را به spectrogram شان تبدیل می کند. این تابع را برای هر سه بخش داده صدا می کنیم.
def make_spec_ds(ds):
return ds.map(
map_func=lambda audio,label: (get_spectrogram(audio), label),
num_parallel_calls=tf.data.AUTOTUNE)
ساخت مدل کانولوشنی.
norm_layer = layers.Normalization()
norm_layer.adapt(data=train_spectrogram_ds.map(map_func=lambda spec, label: spec))
model = models.Sequential([
layers.Input(shape=input_shape),
layers.Resizing(32, 32),
norm_layer,
layers.Conv2D(32, 3, activation='relu'),
layers.Conv2D(64, 3, activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64, 3, activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64, 3, activation='relu'),
layers.MaxPooling2D(),
layers.Dropout(0.25),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dropout(0.5),
layers.Dense(num_labels),])
کامپایل و فیت کردن مدل
model.compile(
optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'],)
EPOCHS = 30
history = model.fit(
train_spectrogram_ds,
validation_data=val_spectrogram_ds,
epochs=EPOCHS,
callbacks=tf.keras.callbacks.EarlyStopping(verbose=1, patience=5),)
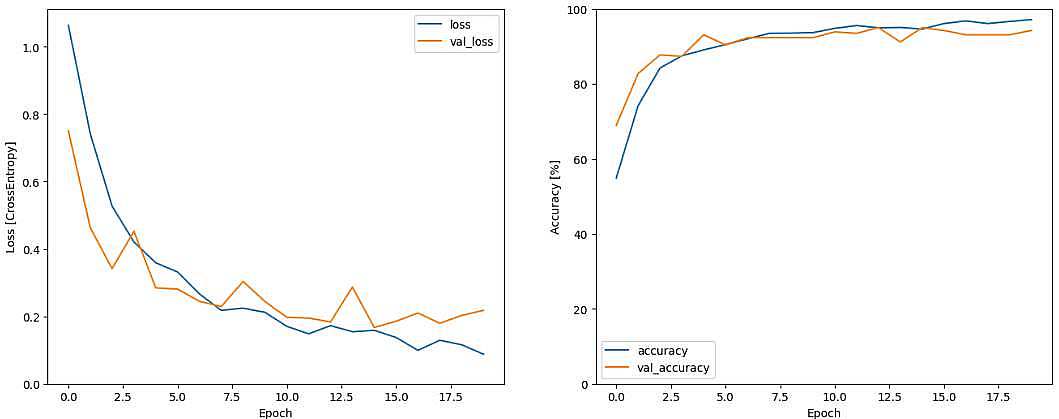
نمایش نمودار Accuracy و Loss داده ها
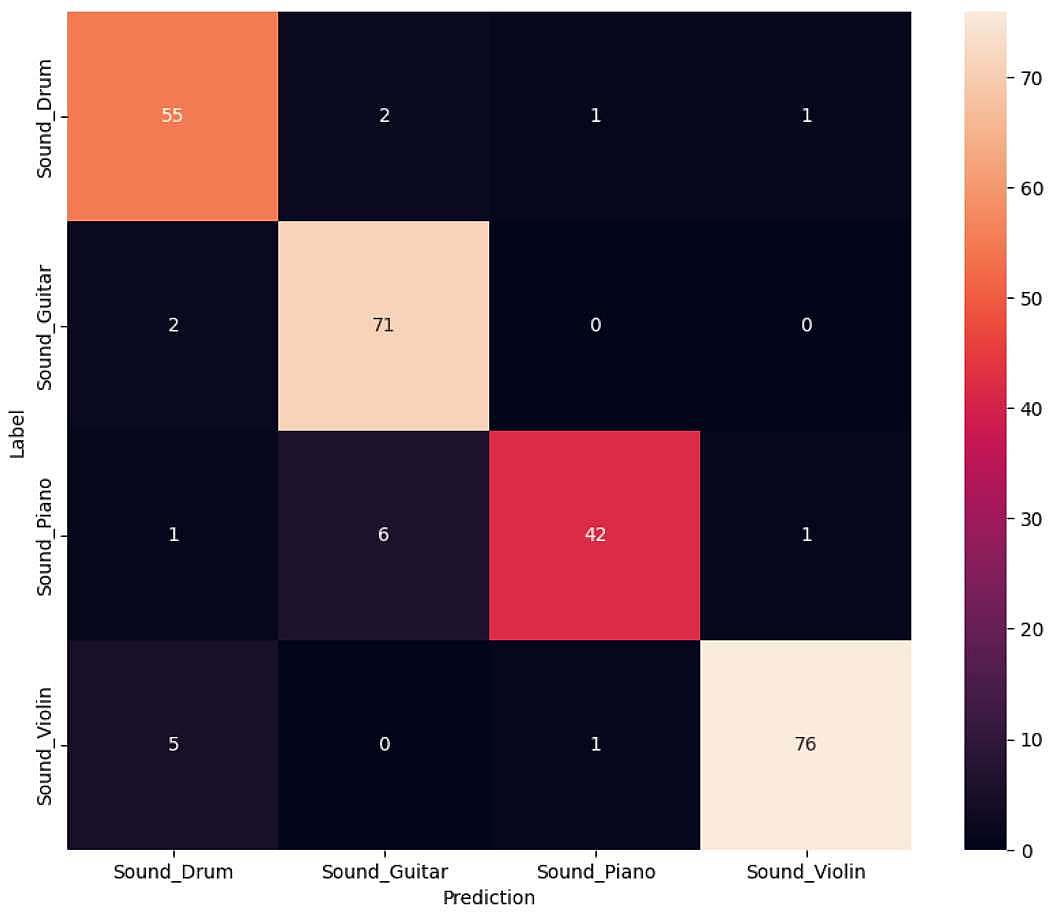
پیشبینی داده ها تست و کانکت کردن آن با لیبل های اصلی برای رسم confusion_matrix
- test امتحان کردن مدل با چند صوت