Graph attention network (GAT) for node classification
Graph Attention Networks:
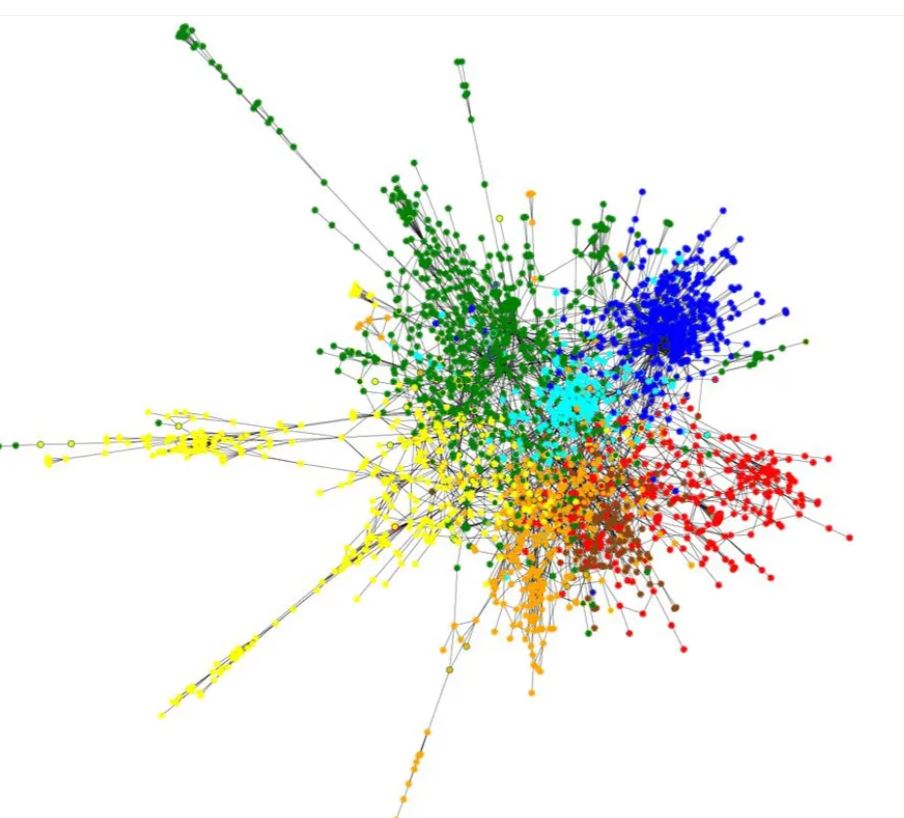
graph neural network یک کلاس از شبکههای عصبی است که برای پردازش دادههای گراف مانند گرافهای رسانههای اجتماعی و گرافهای مربوط به پروتئینها و مولکولهای مختلف استفاده میشود.
Graph attention network یک معماری نوین از شبکه عصبی است که با استفاده از لایههای خودتوجه با ماسک، بر روی دادههای ساختاری گراف عمل میکند و مشکلات کانولوشن گراف یا تقریب آن را حل میکند. در این شبکه، لایهها به صورت پشتهای قرار میگیرند به طوری که گرهها میتوانند بر روی ویژگیهای همسایگان خود توجه کنند .
برای دستهبندی گره، معمولاً از شبکههای عصبی گرافی استفاده میشود. این شبکهها قادر به یادگیری و تعمیم الگوهای موجود در ویژگیهای گرهها و رابطههای بینشان هستند. برای این کار، معمولاً از لایههای پرسپترون، لایههای خودتوجه، و لایههای توجه چند سر استفاده میشود.
با استفاده از شبکههای عصبی گرافی در دستهبندی گره، میتوانیم الگوریتمهای قوی و انعطافپذیری برای تحلیل و پیشبینی ویژگیها و خصوصیات گرهها در گرافها به دست آوریم.
شبکه توجه گراف (GAT) نوعی معماری شبکه عصبی است که به طور خاص برای وظایف طبقه بندی گره ها در داده های ساختار یافته گراف طراحی شده است. این معماری در سال 2018 توسط Veličković و همکارانش معرفی شد به عنوان یک روش برای مدلسازی موثر روابط بین گره ها در یک گراف و درک اهمیت گره های مختلف برای طبقه بندی.
در شبکه های عصبی گراف سنتی، اطلاعات از گره های همسایه به طور معمول با میانگین ساده یا مجموع وزن دار ویژگی های آنها تجمیع می شود. با این حال، GAT مکانیزم های توجه را به کار می گیرد تا به طور پویا وزن های مختلفی به همسایگان مختلف اختصاص دهد، که به شبکه اجازه می دهد در فرآیند تجمیع بیشتر بر روی گره های مرتبط تمرکز کند.
در ادامه توضیح مفصلی از معماری GAT و اجزای کلیدی آن آورده شده است:
۱. نمایش ورودی:
- هر گره در گراف با یک بردار ویژگی که ویژگی ها یا خصوصیات آن را نشان می دهد، مرتبط است.
- در GAT، این بردارهای ویژگی به طور معمول به عنوان یک ماتریس X به شکل (N، F) نمایش داده می شوند، که در آن N تعداد گره ها و F تعداد ویژگی های ورودی برای هر گره است.
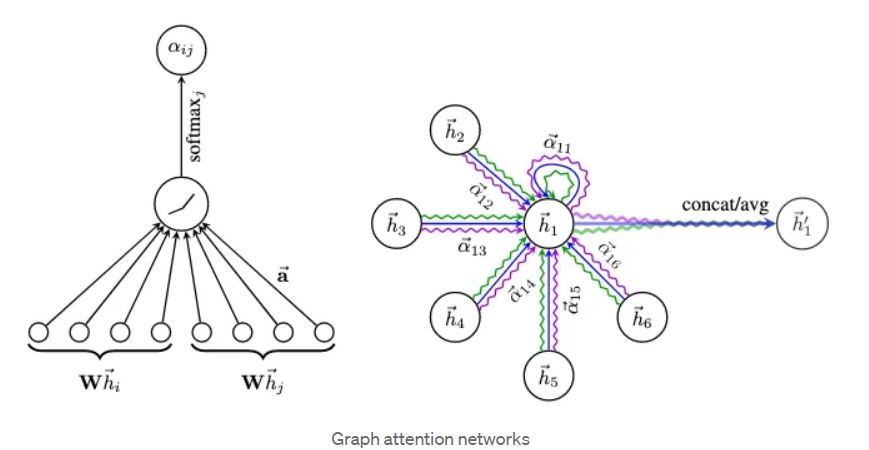
۲. مکانیزم توجه:
- GAT از مکانیزم های توجه برای محاسبه ضرایب توجه استفاده می کند که اهمیت گره های مختلف را ثبت می کنند.
- ضرایب توجه با مقایسه نمایش ویژگی یک گره مرکزی با گره های همسایه آن محاسبه می شوند.
- GAT از یک مکانیزم توجه خودمانند استفاده می کند، جایی که نمایش ویژگی یک گره با نمایش ویژگی های همسایگان خود مقایسه می شود.
۳. ضرایب توجه:
- ضرایب توجه اهمیت یا ارتباط هر گره همسایه را برای گره مرکزی مشخص می کنند.
- برای محاسبه ضرایب توجه، GAT از یک فرشبکه توجه گراف (GAT) نوعی معماری شبکه عصبی است که به طور خاص برای وظایف طبقهبندی گرهها در دادههای ساختاری گراف طراحی شده است. این معماری در سال 2018 توسط ولیچکوویچ و همکارانش به عنوان یک روش برای مدلسازی موثر روابط بین گرهها در یک گراف و درک اهمیت گرههای مختلف برای طبقهبندی معرفی شد.
۴.جمع آوری :
- پس از محاسبه ضرایب توجه، GAT اطلاعات از همسایگان را با استفاده از این ضرایب جمعآوری میکند، که منجر به نمایش بهبود یافته برای هر گره میشود.
۵.خروجی:
- در نهایت، نمایشهای جمعآوری شده از گرهها برای طبقهبندی گرهها استفاده میشود، معمولاً از طریق یک لایه softmax که برچسب کلاس را به هر گره اختصاص میدهد.
Import packages:
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import numpy as np
import pandas as pd
import os
import warnings
warnings.filterwarnings("ignore")
pd.set_option("display.max_columns", 6)
pd.set_option("display.max_rows", 6)
np.random.seed(2)
Obtain the dataset:
آمادهسازی مجموعه داده Cora به همان روش آمادهسازی مجموعه داده دستهبندی گره با شبکههای عصبی گرافیکی
(Graph Neural Networks) انجام میشود. به طور خلاصه، مجموعه داده
Cora شامل دو فایل است: فایل
cora.cites و فایل
cora.content است.
در این کد، ابتدا از تابع
`get_file` در ماژول
`keras.utils` استفاده شده است تا فایل مجموعه داده Cora را از آدرس مشخص شده در `
origin` دریافت کند و آن را در مسیر
`zip_file` ذخیره کند. سپس با استفاده از تابع
`os.path.join`، مسیر پوشه
`cora` را در مسیر پوشه حاوی فایل فشرده مجموعه داده تشکیل میدهد.
سپس، دو فایل CSV موجود در مجموعه داده را به کمک تابع
`pd.read_csv` در ماژول `
pandas` بارگیری میکند. فایل `
cora.cites` که شامل ارتباطات جهتدار بین مقالات است، با استفاده از آرگومانهای
`sep="\t"` و `names=["target", "source"]` خوانده میشود. همچنین، فایل `
cora.content` که شامل ویژگیها و برچسبهای مقالات است، با استفاده از آرگومانهای
`sep="\t"` و
`names=["paper_id"] + [f"term_{idx}" for idx in range(1433)] + ["subject"]` خوانده میشود.
سپس، مقادیر منحصر به فرد موجود در ستون
`subject` (برچسبها) مرتب میشوند و در
`class_values` ذخیره میشوند. همچنین، یک دیکشنری به نام `class_idx` تشکیل داده میشود که هر برچسب را به یک شناسه مرتبط میدهد. همچنین، یک دیکشنری دیگر به نام `paper_idx` تشکیل داده میشود که هر شناسه مقاله را به یک شناسه عددی مرتبط میدهد.
در ادامه، با استفاده از توابع
`apply`، ستون `
paper_id` در جدول `
papers` به شناسه مرتبط در دیکشنری
`paper_idx` تبدیل میشود. همچنین، ستونهای
`source` و `
target` در جدول
`citations` به شناسههای مرتبط در دیکشنری
`paper_idx` تبدیل میشوند. همچنین، ستون `
subject` در جدول `
papers` به شناسه مرتبط در دیکشنری
`class_idx` تبدیل میشود.
در نهایت، جداول `
citations` و `papers` چاپ میشوند تا محتوای آنها را مشاهده کنید.
zip_file = keras.utils.get_file(
fname="cora.tgz",
origin="https://linqs-data.soe.ucsc.edu/public/lbc/cora.tgz",
extract=True,
)
data_dir = os.path.join(os.path.dirname(zip_file), "cora")
citations = pd.read_csv(
os.path.join(data_dir, "cora.cites"),
sep="\t",
header=None,
names=["target", "source"],
)
papers = pd.read_csv(
os.path.join(data_dir, "cora.content"),
sep="\t",
header=None,
names=["paper_id"] + [f"term_{idx}" for idx in range(1433)] + ["subject"],
)
class_values = sorted(papers["subject"].unique())
class_idx = {name: id for id, name in enumerate(class_values)}
paper_idx = {name: idx for idx, name in enumerate(sorted(papers["paper_id"].unique()))}
papers["paper_id"] = papers["paper_id"].apply(lambda name: paper_idx[name])
citations["source"] = citations["source"].apply(lambda name: paper_idx[name])
citations["target"] = citations["target"].apply(lambda name: paper_idx[name])
papers["subject"] = papers["subject"].apply(lambda value: class_idx[value])
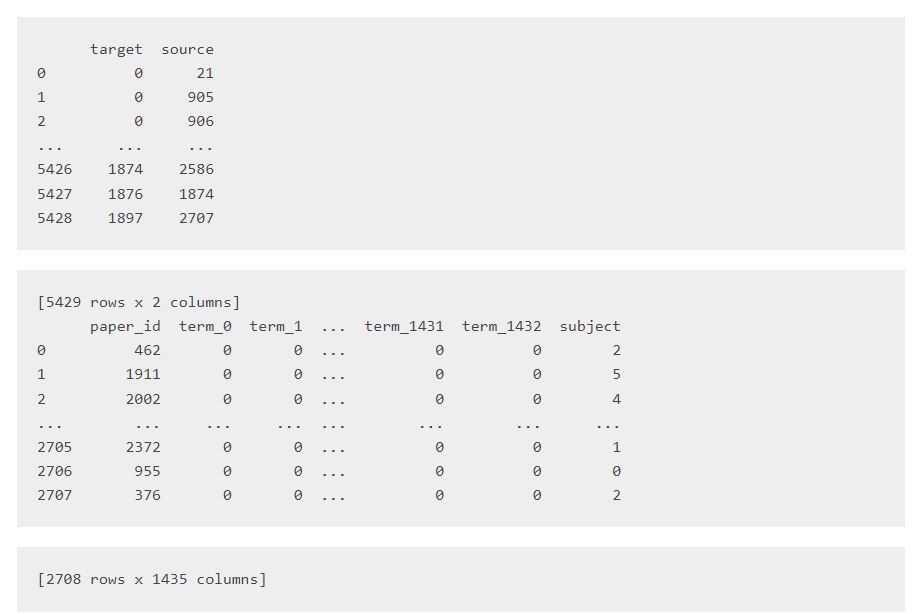
print(citations)
print(papers)
Split the dataset:
در این کد، ابتدا با استفاده از تابع
np.random.permutation از ماژول
numpy، اندیسهای تصادفی برای دسترسی به ردیفهای جدول
papers تولید میشود. این اندیسها ترتیب تصادفی را در رنج اعداد صفر تا تعداد ردیفهای جدول
papers دارند.
سپس، با استفاده از این اندیسها، مجموعه داده به دو بخش تقسیم میشود. بخش اول که به آن
train_data نامیده شده است، شامل نیمی از ردیفهای جدول
papers است که اندیس آنها از ابتدای لیست تصادفی تولید شده است. بخش دوم که به آن
test_data نامیده شده است، شامل نیمی دیگر از ردیفهای جدول
papers است که اندیس آنها از نصف تا انتهای لیست تصادفی تولید شده است.
با این تقسیم، مجموعه داده به دو بخش آموزش و آزمون تقسیم شده است. این تقسیم معمولاً با نسبت 50/50 صورت میگیرد، اما میتوان نسبت دیگری را نیز انتخاب کرد.
# Obtain random indices
random_indices = np.random.permutation(range(papers.shape[0]))
# 50/50 split
train_data = papers.iloc[random_indices[: len(random_indices) // 2]]
test_data = papers.iloc[random_indices[len(random_indices) // 2 :]]
Prepare the graph data:
در این کد، ابتدا اندیسهای papers که در زمان آموزش مدل برای جمعآوری وضعیت نودها از گراف استفاده میشود، از جدول
train_data و
test_data استخراج میشود. این اندیسها در ستون "paper_id" وجود دارند و با استفاده از تابع
to_numpy() به آرایه نامپای تبدیل میشوند. این آرایهها به ترتیب در متغیرهای
train_indices و
test_indices ذخیره میشوند.
سپس، برچسبهای واقعی متناظر با هر paper(براساس شناسه داده) از جدول
train_data و
test_data استخراج میشوند. این برچسبها در ستون "subject" قرار دارند و با استفاده از تابع
to_numpy() به آرایه نامپای تبدیل میشوند. این آرایهها به ترتیب در متغیرهای
train_labels و
test_labels ذخیره میشوند.
سپس، گراف تعریف میشود. یالهای گراف در متغیر
edges قرار داده میشوند که با استفاده از تابع
tf.convert_to_tensor از جدول
citations استخراج میشوند. این جدول دارای دو ستون "target" و "source" است که نشاندهنده اندیسهای داده هایی هستند که یال بین آنها وجود دارد.
ویژگیهای نودها در متغیر
node_states قرار داده میشوند. این متغیر با استفاده از تابع
tf.convert_to_tensor از جدول
papers استخراج میشود. جدول
papers شامل ویژگیهایpapers است که در ستونهای بعد از ستون "paper_id" و قبل از ستون نشاندهنده برچسب "subject" قرار دارند.
# Obtain paper indices which will be used to gather node states
# from the graph later on when training the model
train_indices = train_data["paper_id"].to_numpy()
test_indices = test_data["paper_id"].to_numpy()
# Obtain ground truth labels corresponding to each paper_id
train_labels = train_data["subject"].to_numpy()
test_labels = test_data["subject"].to_numpy()
# Define graph, namely an edge tensor and a node feature tensor
edges = tf.convert_to_tensor(citations[["target", "source"]])
node_states = tf.convert_to_tensor(papers.sort_values("paper_id").iloc[:, 1:-1])
# Print shapes of the graph
print("Edges shape:\t\t", edges.shape)
print("Node features shape:", node_states.shape)
خروجی:
در انتها، با استفاده از تابع
print، ابعاد ماتریسهای
edges و
node_states چاپ میشوند. این ابعاد به ترتیب در خروجی نشان داده شدهاند. ابعاد
edges برابر با (5429, 2) است که نشاندهنده تعداد یالها و ستونهایی که از هر یال استخراج شدهاند است. ابعاد
node_states برابر با (2708, 1433) است که نشاندهنده تعداد نودها و تعداد ویژگیهای هر نود است.

Build the model:
GAT یک گراف را (یعنی یک تانسور یال و یک تانسور ویژگی نود) به عنوان ورودی دریافت میکند و وضعیت نودها را به روزرسانی میکند. وضعیت نودها برای هر نود هدف، اطلاعات تجمعی محلی از N پرشها (که تعداد لایههای GAT تعیین میکند) است. در مقابل، به طور مهم، GAT برخلاف شبکه همبندی گراف (GCN) از مکانیسمهای توجه برای تجمیع اطلاعات از نودهای همسایه (یا نودهای مبدا) استفاده میکند. به عبارت دیگر، به جای متوسط / جمع وضعیت نودهای مبدا (مقالههای مبدا) به نود هدف (مقالههای هدف)، GAT ابتدا امتیازهای توجه نرمال شده را به هر وضعیت نود مبدا اعمال کرده و سپس جمع میکند.
مدل GAT لایههای توجه گراف چند سر را پیادهسازی میکند. لایه MultiHeadGraphAttention به سادگی یک اتصال (یا میانگین) از چند لایه توجه گراف (GraphAttention) با وزنهای جداگانه قابل یادگیری W است. لایه GraphAttention عملکرد زیر را دارد:
(Multi-head) graph attention layer:
ابتدا وضعیت نود ورودی h^{l} که توسط W^{l} خطی تبدیل میشود، به z^{l} منتقل میشود.
برای هر نود هدف:
امتیازهای توجه دو به دو
a^{l}^{T}(z^{l}{i}||z^{l}{j}) برای همه j محاسبه میشود که به
e_{ij} منجر میشود (برای همه j). علامت || نشاندهنده اتصال است، {i} به نود هدف اشاره دارد و {j} به نود همسایه/مبدا یک پرش داده میشود.
مقادیر e{ij} از طریق
softmax نرمال شده و از این رو مجموع امتیازهای توجه یالهای ورودی به نود هدف
(sum{k}{e_{norm}{ik}}) برابر با 1 خواهد بود.
امتیازهای توجه
e{norm}{ij} را به z{j} اعمال کرده و به وضعیت جدید نود هدف h^{l+1}_{i} اضافه میکند، برای همه j.
class GraphAttention(layers.Layer):
def __init__(
self,
units,
kernel_initializer="glorot_uniform",
kernel_regularizer=None,
**kwargs,
):
super().__init__(**kwargs)
self.units = units
self.kernel_initializer = keras.initializers.get(kernel_initializer)
self.kernel_regularizer = keras.regularizers.get(kernel_regularizer)
def build(self, input_shape):
self.kernel = self.add_weight(
shape=(input_shape[0][-1], self.units),
trainable=True,
initializer=self.kernel_initializer,
regularizer=self.kernel_regularizer,
name="kernel",
)
self.kernel_attention = self.add_weight(
shape=(self.units * 2, 1),
trainable=True,
initializer=self.kernel_initializer,
regularizer=self.kernel_regularizer,
name="kernel_attention",
)
self.built = True
def call(self, inputs):
node_states, edges = inputs
# Linearly transform node states
node_states_transformed = tf.matmul(node_states, self.kernel)
# (1) Compute pair-wise attention scores
node_states_expanded = tf.gather(node_states_transformed, edges)
node_states_expanded = tf.reshape(
node_states_expanded, (tf.shape(edges)[0], -1)
)
attention_scores = tf.nn.leaky_relu(
tf.matmul(node_states_expanded, self.kernel_attention)
)
attention_scores = tf.squeeze(attention_scores, -1)
# (2) Normalize attention scores
attention_scores = tf.math.exp(tf.clip_by_value(attention_scores, -2, 2))
attention_scores_sum = tf.math.unsorted_segment_sum(
data=attention_scores,
segment_ids=edges[:, 0],
num_segments=tf.reduce_max(edges[:, 0]) + 1,
)
attention_scores_sum = tf.repeat(
attention_scores_sum, tf.math.bincount(tf.cast(edges[:, 0], "int32"))
)
attention_scores_norm = attention_scores / attention_scores_sum
# (3) Gather node states of neighbors, apply attention scores and aggregate
node_states_neighbors = tf.gather(node_states_transformed, edges[:, 1])
out = tf.math.unsorted_segment_sum(
data=node_states_neighbors * attention_scores_norm[:, tf.newaxis],
segment_ids=edges[:, 0],
num_segments=tf.shape(node_states)[0],
)
return out
class MultiHeadGraphAttention(layers.Layer):
def __init__(self, units, num_heads=8, merge_type="concat", **kwargs):
super().__init__(**kwargs)
self.num_heads = num_heads
self.merge_type = merge_type
self.attention_layers = [GraphAttention(units) for _ in range(num_heads)]
def call(self, inputs):
atom_features, pair_indices = inputs
# Obtain outputs from each attention head
outputs = [
attention_layer([atom_features, pair_indices])
for attention_layer in self.attention_layers
]
# Concatenate or average the node states from each head
if self.merge_type == "concat":
outputs = tf.concat(outputs, axis=-1)
else:
outputs = tf.reduce_mean(tf.stack(outputs, axis=-1), axis=-1)
# Activate and return node states
return tf.nn.relu(outputs)
منطق آموزش را با استفاده از متدهای سفارشی train_step، test_step و predict_step
توجه کنید که مدل GAT در تمام فازها (آموزش، اعتبارسنجی و آزمون) بر روی کل گراف (یعنی وضعیت نودها و یالها) عمل میکند. بنابراین، وضعیت نودها و یالها به سازنده keras.Model ارسال شده و به عنوان ویژگیها استفاده میشوند. تفاوت بین فازها در اندیسها (و برچسبها) است که خروجیهای خاصی را جمعآوری میکند (tf.gather(outputs, indices)).
این کلاس
GraphAttentionNetwork یک زیرکلاس از
keras.Model است که برای پیادهسازی شبکه GAT استفاده میشود. دارای متدهای
train_step،
test_step و
predict_step میباشد که برای آموزش، ارزیابی و پیشبینی استفاده میشوند.
در متد
__init__، وضعیت نودها و یالها به عنوان ورودیهای سازنده گرفته میشوند و به عنوان ویژگیها ذخیره میشوند. همچنین یک لایه Dense برای پیشپردازش ورودیها، لایههای توجه چند سری و یک لایه Dense خروجی تعریف میشوند.
در متد
call، ورودیهایی که شامل وضعیت نودها و یالها هستند، به عنوان ورودی به مدل داده میشوند و عملیات شبکه اعمال میشود. ابتدا ورودیها از طریق لایه Dense پیشپردازش میشوند، سپس لایههای توجه چند سری روی ورودیها اعمال میشوند و خروجیهای نهایی توسط لایه Dense خروجی تبدیل میشوند.
در متد
train_step، ابتدا اندیسها و برچسبها از دادهی ورودی استخراج میشوند. سپس با استفاده از
tf.GradientTape، عملیات پیشرو انجام میشود و مقدار خطا محاسبه میشود. سپس گرادیان خطا نسبت به وزنهای قابل آموزش محاسبه میشود و با استفاده از بهینهساز، گرادیانها به وزنهای قابل آموزش اعمال میشوند. در نهایت، مقادیر متریکهای آموزشی بهروزرسانی میشوند و نتیجه بهصورت یک دیکشنری با نام متریکها برگشت داده میشود.
در متد
predict_step، ابتدا اندیسها از دادهی ورودی استخراج میشوند. سپس عملیات پیشرو بر روی دادههای ورودی انجام میشود و احتمالات بهدست آمده از طریق تابع softmax برگشت داده میشود.
در متد
test_step، ابتدا اندیسها و برچسبها از دادهی ورودی استخراج میشوند. سپس عملیات پیشرو بر روی دادههای ورودی انجام میشود و خطا محاسبه میشود.
class GraphAttentionNetwork(keras.Model):
def __init__(
self,
node_states,
edges,
hidden_units,
num_heads,
num_layers,
output_dim,
**kwargs,
):
super().__init__(**kwargs)
self.node_states = node_states
self.edges = edges
self.preprocess = layers.Dense(hidden_units * num_heads, activation="relu")
self.attention_layers = [
MultiHeadGraphAttention(hidden_units, num_heads) for _ in range(num_layers)
]
self.output_layer = layers.Dense(output_dim)
def call(self, inputs):
node_states, edges = inputs
x = self.preprocess(node_states)
for attention_layer in self.attention_layers:
x = attention_layer([x, edges]) + x
outputs = self.output_layer(x)
return outputs
def train_step(self, data):
indices, labels = data
with tf.GradientTape() as tape:
# Forward pass
outputs = self([self.node_states, self.edges])
# Compute loss
loss = self.compiled_loss(labels, tf.gather(outputs, indices))
# Compute gradients
grads = tape.gradient(loss, self.trainable_weights)
# Apply gradients (update weights)
optimizer.apply_gradients(zip(grads, self.trainable_weights))
# Update metric(s)
self.compiled_metrics.update_state(labels, tf.gather(outputs, indices))
return {m.name: m.result() for m in self.metrics}
def predict_step(self, data):
indices = data
# Forward pass
outputs = self([self.node_states, self.edges])
# Compute probabilities
return tf.nn.softmax(tf.gather(outputs, indices))
def test_step(self, data):
indices, labels = data
# Forward pass
outputs = self([self.node_states, self.edges])
# Compute loss
loss = self.compiled_loss(labels, tf.gather(outputs, indices))
# Update metric(s)
self.compiled_metrics.update_state(labels, tf.gather(outputs, indices))
return {m.name: m.result() for m in self.metrics}
Train and evaluate:
در این بخش از کد، پارامترهای مورد نیاز برای آموزش مدل تعریف شدهاند. سپس یک تابع هزینه، یک بهینهساز و یک معیار دقت تعریف شدهاند. همچنین از یک callback با نام EarlyStopping برای متوقف کردن زودهنگام آموزش استفاده میشود.
سپس مدل GAT با استفاده از کلاس
GraphAttentionNetwork ساخته میشود. سپس مدل کامپایل میشود با استفاده از تابع هزینه، بهینهساز و معیار دقت.
سپس مدل با استفاده از متد
fit آموزش داده میشود. دادههای آموزشی به همراه برچسبهایشان به عنوان ورودی به متد
fit داده میشوند. همچنین نسبت اختصاص دادههای اعتبارسنجی تعیین میشود، اندازه دسته، تعداد دورهای آموزش، callback های لازم و حالت verbose برای نمایش خروجی در حین آموزش نیز مشخص میشوند.
پس از آموزش، دقت مدل روی دادههای تست محاسبه شده و نتیجه چاپ میشود.
# Define hyper-parameters
HIDDEN_UNITS = 100
NUM_HEADS = 8
NUM_LAYERS = 3
OUTPUT_DIM = len(class_values)
NUM_EPOCHS = 100
BATCH_SIZE = 256
VALIDATION_SPLIT = 0.1
LEARNING_RATE = 3e-1
MOMENTUM = 0.9
loss_fn = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
optimizer = keras.optimizers.SGD(LEARNING_RATE, momentum=MOMENTUM)
accuracy_fn = keras.metrics.SparseCategoricalAccuracy(name="acc")
early_stopping = keras.callbacks.EarlyStopping(
monitor="val_acc", min_delta=1e-5, patience=5, restore_best_weights=True
)
# Build model
gat_model = GraphAttentionNetwork(
node_states, edges, HIDDEN_UNITS, NUM_HEADS, NUM_LAYERS, OUTPUT_DIM
)
# Compile model
gat_model.compile(loss=loss_fn, optimizer=optimizer, metrics=[accuracy_fn])
gat_model.fit(
x=train_indices,
y=train_labels,
validation_split=VALIDATION_SPLIT,
batch_size=BATCH_SIZE,
epochs=NUM_EPOCHS,
callbacks=[early_stopping],
verbose=2,
)
_, test_accuracy = gat_model.evaluate(x=test_indices, y=test_labels, verbose=0)
print("--" * 38 + f"\nTest Accuracy {test_accuracy*100:.1f}%")

Predict (probabilities):
در این قسمت از کد، مدل قبلی بر روی دادههای تست استفاده میشود تا احتمالات پیشبینی برای هر نمونه در دادههای تست محاسبه شود.
ابتدا با استفاده از متد
predict مدل، احتمالات پیشبینی برای دادههای تست محاسبه میشوند و در متغیر
test_probs ذخیره میشوند.
سپس یک دیکشنری به نام
mapping تعریف میشود که مقدار واقعی برچسبها را به نام کلاسها نگاشت میدهد.
سپس با استفاده از حلقه
for و تابع
zip، برای هر نمونه در دادههای تست، احتمالات پیشبینی و برچسب واقعی آن را به صورت زوجی در نظر میگیریم.
در هر مرحله از حلقه، نمونه و شماره آن (به عنوان مثال ۱، ۲ و غیره) چاپ میشود، سپس برای هر احتمال پیشبینی و نام کلاس، احتمال پیشبینی و درصد آن چاپ میشود.
در نهایت، بین هر نمونه یک خط تیره چاپ میشود تا خروجی برای هر نمونه متمایز شود.
test_probs = gat_model.predict(x=test_indices)
mapping = {v: k for (k, v) in class_idx.items()}
for i, (probs, label) in enumerate(zip(test_probs[:10], test_labels[:10])):
print(f"Example {i+1}: {mapping[label]}")
for j, c in zip(probs, class_idx.keys()):
print(f"\tProbability of {c: <24} = {j*100:7.3f}%")
print("---" * 20)

سوالات:
سوال ۱: چه نوع دادههایی برای ورودی شبکه توجه گراف (GAT) استفاده میشود؟
الف) دادههای عددی
ب) دادههای متنی
ج) دادههای ساختار گرافی
د) دادههای تصویری
سوال ۲: چه مکانیزمی برای محاسبه ضرایب توجه در GAT استفاده میشود؟
الف) مکانیزم توجه خطی
ب) مکانیزم توجه خودمانند
ج) مکانیزم توجه با استفاده از تابع فعالسازی ReLU
د) مکانیزم توجه با استفاده از تابع فعالسازی Sigmoid
سوال ۳: GAT برای چه وظیفهای طراحی شده است؟
الف) طبقهبندی گرهها در دادههای ساختار گرافی
ب) تشخیص الگو در دادههای تصویری
ج) پردازش دادههای متنی
د) پیشبینی رویدادها در دادههای زمانی
سوال ۴: چه نوع لایهای برای طبقهبندی گرهها معمولاً در شبکههای عصبی گرافی استفاده میشود؟
الف) لایه پرسپترون
ب) لایه توجه چند سر
ج) لایه خودتوجه
د) همه موارد بالا
سوال ۵: GAT چگونه اطلاعات از همسایگان را جمعآوری میکند؟
الف) با استفاده از میانگین ساده و وزندار ویژگیهای همسایگان
ب) با استفاده از مکانیزم توجه برای اختصاص دادن وزندهی به همسایگان
ج) با استفاده از لایه softmax برای طبقهبندی گرهها
د) همه موارد
