Conditional GAN (Generative Adversarial Networks)

Generative Adversarial Networks (GAN) (شبکههای تولیدی مقابلهای) به ما امکان میدهند تا از ورودیهای تصادفی، دادههای تصویری، ویدیویی یا صوتی جدید ایجاد کنیم. به طور معمول، ورودی تصادفی از یک توزیع نرمال نمونهبرداری میشود، سپس از طریق یک سری تبدیلات که آن را به چیزی قابل قبول تبدیل میکند (تصویر، ویدیو، صوت و غیره)، میگذرد.
با این حال، یک DCGAN ساده به ما امکان کنترل ظاهر (مثلاً کلاس) نمونههایی که در حال تولید هستیم را نمیدهد. به عنوان مثال، با یک GAN که اعداد دستنویس MNIST تولید میکند، یک DCGAN ساده به ما امکان انتخاب کلاس اعدادی که در حال تولید هستیم را نمیدهد. برای قادر شدن به کنترل آنچه را تولید میکنیم، نیاز داریم خروجی GAN را بر اساس ورودی معنایی (مانند کلاس تصویر) شرطبندی کنیم. این شرطبندی ورودی معنایی به ما امکان میدهد تا به طور دقیق کلاس یا ویژگیهای دیگری که مدنظرمان است را در نمونههای تولید شده کنترل کنیم. برای این منظور، باید ورودی معنایی را به همراه ورودی تصادفی به شبکههای GAN ارائه دهیم. این ورودی معمولاً یک بردار یا یک تصویر است که شامل اطلاعات مربوط به کلاس یا ویژگی مورد نظر است. به این ترتیب، شبکههای GAN قادر خواهند بود تا نمونههایی با خصوصیات دقیقی که در ورودی معنایی داده شده است را تولید کنند. این قابلیت از اهمیت بالایی برخوردار است و برای بسیاری از کاربردهای مختلف مورد استفاده قرار میگیرد، از تولید تصاویر شخصیسازی شده تا تولید دادههای آموزشی با خصوصیات مشخص. این امکانات پیشرفته در زمینه GANها باعث شده است که تولید دادههای واقعینما و کنترلپذیری بیشتری را در دست آوریم، که از آن به عنوان ابزاری قدرتمند در زمینه هنر، طراحی، تولید محتوا و سایر حوزهها بهره میبریم. در این مثال، یک Conditional GAN را خواهیم ساخت که قادر به تولید اعداد دستنویس MNIST با شرط مشخصی است. چنین مدلی میتواند کاربردهای متنوع و کارآمدی داشته باشد. برای مثال، فرض کنید شما با مجموعهدادهای از تصاویر نامتوازن سر و کار دارید و میخواهید نمونههای بیشتری برای کلاسی که تعادل مجموعهداده را بهم میزند جمعآوری کنید. جمعآوری داده ممکن است به تنهایی هزینهبر باشد. در عوض، میتوانید یک Conditional GAN آموزش دهید و از آن برای تولید تصاویر نوآورانه برای کلاسی که نیاز به تعادل دارد استفاده کنید.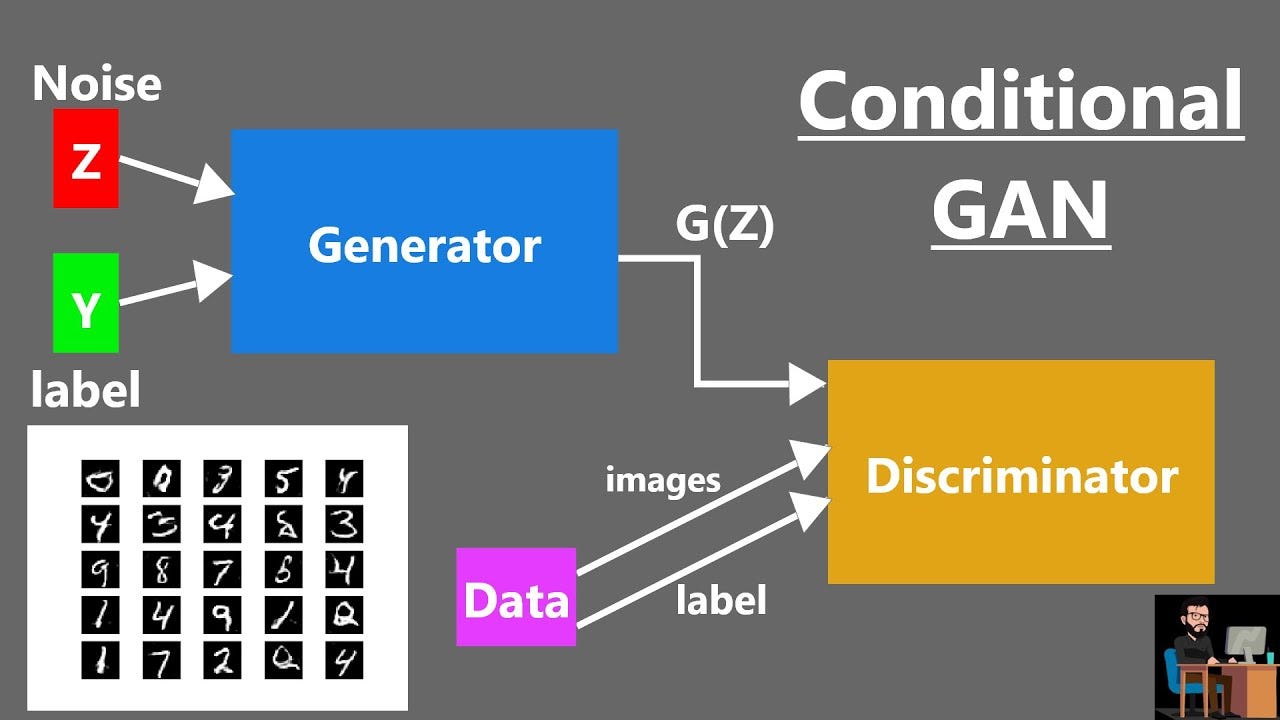
پیاده سازی:
این مثال نیاز به TensorFlow 2.5 یا بالاتر دارد، همچنین نیاز به TensorFlow Docs نیز دارد که با استفاده از دستور زیر قابل نصب است:!pip install -q git+https://github.com/tensorflow/docs
Imports:
import keras from keras import layers from keras import ops from tensorflow_docs.vis import embed import tensorflow as tf import numpy as np import imageio
Constants and hyperparameters:
batch_size = 64 num_channels = 1 num_classes = 10 image_size = 28 latent_dim = 128
Loading the MNIST dataset and preprocessing it:
# We'll use all the available examples from both the training and test
# sets.
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
all_digits = np.concatenate([x_train, x_test])
all_labels = np.concatenate([y_train, y_test])
# Scale the pixel values to [0, 1] range, add a channel dimension to
# the images, and one-hot encode the labels.
all_digits = all_digits.astype("float32") / 255.0
all_digits = np.reshape(all_digits, (-1, 28, 28, 1))
all_labels = keras.utils.to_categorical(all_labels, 10)
# Create tf.data.Dataset.
dataset = tf.data.Dataset.from_tensor_slices((all_digits, all_labels))
dataset = dataset.shuffle(buffer_size=1024).batch(batch_size)
print(f"Shape of training images: {all_digits.shape}")
print(f"Shape of training labels: {all_labels.shape}")

Calculating the number of input channel for the generator and discriminator:
در یک "شبکههای تولیدی مقابلهای" معمولی (بدون شرط)، ابتدا نویزی (از یک توزیع نرمال) با ابعاد ثابت نمونهبرداری میکنیم. در مورد ما، نیز باید برچسبهای کلاس را در نظر بگیریم. باید تعداد کلاسها را به کانالهای ورودی مولد (ورودی نویز) و همچنین دیسکریمیناتور (ورودی تصویر تولید شده) اضافه کنیم.
generator_in_channels = latent_dim + num_classes discriminator_in_channels = num_channels + num_classes print(generator_in_channels, discriminator_in_channels) output: 138 11
Creating the discriminator and generator:
# Create the discriminator. discriminator = keras.Sequential( [ keras.layers.InputLayer((28, 28, discriminator_in_channels)), layers.Conv2D(64, (3, 3), strides=(2, 2), padding="same"), layers.LeakyReLU(negative_slope=0.2), layers.Conv2D(128, (3, 3), strides=(2, 2), padding="same"), layers.LeakyReLU(negative_slope=0.2), layers.GlobalMaxPooling2D(), layers.Dense(1), ], name="discriminator", ) # Create the generator. generator = keras.Sequential( [ keras.layers.InputLayer((generator_in_channels,)), # We want to generate 128 + num_classes coefficients to reshape into a # 7x7x(128 + num_classes) map. layers.Dense(7 * 7 * generator_in_channels), layers.LeakyReLU(negative_slope=0.2), layers.Reshape((7, 7, generator_in_channels)), layers.Conv2DTranspose(128, (4, 4), strides=(2, 2), padding="same"), layers.LeakyReLU(negative_slope=0.2), layers.Conv2DTranspose(128, (4, 4), strides=(2, 2), padding="same"), layers.LeakyReLU(negative_slope=0.2), layers.Conv2D(1, (7, 7), padding="same", activation="sigmoid"), ], name="generator", )
Creating a ConditionalGAN model:
class ConditionalGAN(keras.Model):
def __init__(self, discriminator, generator, latent_dim):
super().__init__()
self.discriminator = discriminator
self.generator = generator
self.latent_dim = latent_dim
self.seed_generator = keras.random.SeedGenerator(1337)
self.gen_loss_tracker = keras.metrics.Mean(name="generator_loss")
self.disc_loss_tracker = keras.metrics.Mean(name="discriminator_loss")
@property
def metrics(self):
return [self.gen_loss_tracker, self.disc_loss_tracker]
def compile(self, d_optimizer, g_optimizer, loss_fn):
super().compile()
self.d_optimizer = d_optimizer
self.g_optimizer = g_optimizer
self.loss_fn = loss_fn
def train_step(self, data):
# Unpack the data.
real_images, one_hot_labels = data
# Add dummy dimensions to the labels so that they can be concatenated with
# the images. This is for the discriminator.
image_one_hot_labels = one_hot_labels[:, :, None, None]
image_one_hot_labels = ops.repeat(
image_one_hot_labels, repeats=[image_size * image_size]
)
image_one_hot_labels = ops.reshape(
image_one_hot_labels, (-1, image_size, image_size, num_classes)
)
# Sample random points in the latent space and concatenate the labels.
# This is for the generator.
batch_size = ops.shape(real_images)[0]
random_latent_vectors = keras.random.normal(
shape=(batch_size, self.latent_dim), seed=self.seed_generator
)
random_vector_labels = ops.concatenate(
[random_latent_vectors, one_hot_labels], axis=1
)
# Decode the noise (guided by labels) to fake images.
generated_images = self.generator(random_vector_labels)
# Combine them with real images. Note that we are concatenating the labels
# with these images here.
fake_image_and_labels = ops.concatenate(
[generated_images, image_one_hot_labels], -1
)
real_image_and_labels = ops.concatenate([real_images, image_one_hot_labels], -1)
combined_images = ops.concatenate(
[fake_image_and_labels, real_image_and_labels], axis=0
)
# Assemble labels discriminating real from fake images.
labels = ops.concatenate(
[ops.ones((batch_size, 1)), ops.zeros((batch_size, 1))], axis=0
)
# Train the discriminator.
with tf.GradientTape() as tape:
predictions = self.discriminator(combined_images)
d_loss = self.loss_fn(labels, predictions)
grads = tape.gradient(d_loss, self.discriminator.trainable_weights)
self.d_optimizer.apply_gradients(
zip(grads, self.discriminator.trainable_weights)
)
# Sample random points in the latent space.
random_latent_vectors = keras.random.normal(
shape=(batch_size, self.latent_dim), seed=self.seed_generator
)
random_vector_labels = ops.concatenate(
[random_latent_vectors, one_hot_labels], axis=1
)
# Assemble labels that say "all real images".
misleading_labels = ops.zeros((batch_size, 1))
# Train the generator (note that we should *not* update the weights
# of the discriminator)!
with tf.GradientTape() as tape:
fake_images = self.generator(random_vector_labels)
fake_image_and_labels = ops.concatenate(
[fake_images, image_one_hot_labels], -1
)
predictions = self.discriminator(fake_image_and_labels)
g_loss = self.loss_fn(misleading_labels, predictions)
grads = tape.gradient(g_loss, self.generator.trainable_weights)
self.g_optimizer.apply_gradients(zip(grads, self.generator.trainable_weights))
# Monitor loss.
self.gen_loss_tracker.update_state(g_loss)
self.disc_loss_tracker.update_state(d_loss)
return {
"g_loss": self.gen_loss_tracker.result(),
"d_loss": self.disc_loss_tracker.result(),
}
Training the Conditional GAN:
cond_gan = ConditionalGAN( discriminator=discriminator, generator=generator, latent_dim=latent_dim ) cond_gan.compile( d_optimizer=keras.optimizers.Adam(learning_rate=0.0003), g_optimizer=keras.optimizers.Adam(learning_rate=0.0003), loss_fn=keras.losses.BinaryCrossentropy(from_logits=True), ) cond_gan.fit(dataset, epochs=20)
output:
Epoch 1/20
18/1094 [37m━━━━━━━━━━━━━━━━━━━━ 10s 9ms/step - d_loss: 0.6321 - g_loss: 0.7887
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
I0000 00:00:1704233262.157522 6737 device_compiler.h:186] Compiled cluster using XLA! This line is logged at most once for the lifetime of the process.
1094/1094 ━━━━━━━━━━━━━━━━━━━━ 24s 14ms/step - d_loss: 0.4052 - g_loss: 1.5851 - discriminator_loss: 0.4390 - generator_loss: 1.4775
Epoch 2/20
1094/1094 ━━━━━━━━━━━━━━━━━━━━ 10s 9ms/step - d_loss: 0.5116 - g_loss: 1.2740 - discriminator_loss: 0.4872 - generator_loss: 1.3330
Epoch 3/20
1094/1094 ━━━━━━━━━━━━━━━━━━━━ 10s 9ms/step - d_loss: 0.3626 - g_loss: 1.6775 - discriminator_loss: 0.3252 - generator_loss: 1.8219
Epoch 4/20
1094/1094 ━━━━━━━━━━━━━━━━━━━━ 10s 9ms/step - d_loss: 0.2248 - g_loss: 2.2898 - discriminator_loss: 0.3418 - generator_loss: 2.0042
Epoch 5/20
1094/1094 ━━━━━━━━━━━━━━━━━━━━ 10s 9ms/step - d_loss: 0.6017 - g_loss: 1.0428 - discriminator_loss: 0.6076 - generator_loss: 1.0176
Epoch 6/20
1094/1094 ━━━━━━━━━━━━━━━━━━━━ 10s 9ms/step - d_loss: 0.6395 - g_loss: 0.9258 - discriminator_loss: 0.6448 - generator_loss: 0.9134
Epoch 7/20
1094/1094 ━━━━━━━━━━━━━━━━━━━━ 10s 9ms/step - d_loss: 0.6402 - g_loss: 0.8914 - discriminator_loss: 0.6458 - generator_loss: 0.8773
Epoch 8/20
1094/1094 ━━━━━━━━━━━━━━━━━━━━ 10s 9ms/step - d_loss: 0.6549 - g_loss: 0.8440 - discriminator_loss: 0.6555 - generator_loss: 0.8364
Epoch 9/20
1094/1094 ━━━━━━━━━━━━━━━━━━━━ 10s 9ms/step - d_loss: 0.6603 - g_loss: 0.8316 - discriminator_loss: 0.6606 - generator_loss: 0.8241
Epoch 10/20
1094/1094 ━━━━━━━━━━━━━━━━━━━━ 10s 9ms/step - d_loss: 0.6594 - g_loss: 0.8169 - discriminator_loss: 0.6605 - generator_loss: 0.8218
Epoch 11/20
1094/1094 ━━━━━━━━━━━━━━━━━━━━ 10s 9ms/step - d_loss: 0.6719 - g_loss: 0.7979 - discriminator_loss: 0.6649 - generator_loss: 0.8096
Epoch 12/20
1094/1094 ━━━━━━━━━━━━━━━━━━━━ 10s 9ms/step - d_loss: 0.6641 - g_loss: 0.7992 - discriminator_loss: 0.6621 - generator_loss: 0.7953
Epoch 13/20
1094/1094 ━━━━━━━━━━━━━━━━━━━━ 10s 9ms/step - d_loss: 0.6657 - g_loss: 0.7979 - discriminator_loss: 0.6624 - generator_loss: 0.7924
Epoch 14/20
1094/1094 ━━━━━━━━━━━━━━━━━━━━ 10s 9ms/step - d_loss: 0.6586 - g_loss: 0.8220 - discriminator_loss: 0.6566 - generator_loss: 0.8174
Epoch 15/20
1094/1094 ━━━━━━━━━━━━━━━━━━━━ 10s 9ms/step - d_loss: 0.6646 - g_loss: 0.7916 - discriminator_loss: 0.6578 - generator_loss: 0.7973
Epoch 16/20
1094/1094 ━━━━━━━━━━━━━━━━━━━━ 10s 9ms/step - d_loss: 0.6624 - g_loss: 0.7911 - discriminator_loss: 0.6587 - generator_loss: 0.7966
Epoch 17/20
1094/1094 ━━━━━━━━━━━━━━━━━━━━ 10s 9ms/step - d_loss: 0.6586 - g_loss: 0.8060 - discriminator_loss: 0.6550 - generator_loss: 0.7997
Epoch 18/20
1094/1094 ━━━━━━━━━━━━━━━━━━━━ 10s 9ms/step - d_loss: 0.6526 - g_loss: 0.7946 - discriminator_loss: 0.6523 - generator_loss: 0.7948
Epoch 19/20
1094/1094 ━━━━━━━━━━━━━━━━━━━━ 10s 9ms/step - d_loss: 0.6525 - g_loss: 0.8039 - discriminator_loss: 0.6497 - generator_loss: 0.8066
Epoch 20/20
1094/1094 ━━━━━━━━━━━━━━━━━━━━ 10s 9ms/step - d_loss: 0.6480 - g_loss: 0.8005 - discriminator_loss: 0.6469 - generator_loss: 0.8022
Interpolating between classes with the trained generator:
# We first extract the trained generator from our Conditional GAN.
trained_gen = cond_gan.generator
# Choose the number of intermediate images that would be generated in
# between the interpolation + 2 (start and last images).
num_interpolation = 9 # @param {type:"integer"}
# Sample noise for the interpolation.
interpolation_noise = keras.random.normal(shape=(1, latent_dim))
interpolation_noise = ops.repeat(interpolation_noise, repeats=num_interpolation)
interpolation_noise = ops.reshape(interpolation_noise, (num_interpolation, latent_dim))
def interpolate_class(first_number, second_number):
# Convert the start and end labels to one-hot encoded vectors.
first_label = keras.utils.to_categorical([first_number], num_classes)
second_label = keras.utils.to_categorical([second_number], num_classes)
first_label = ops.cast(first_label, "float32")
second_label = ops.cast(second_label, "float32")
# Calculate the interpolation vector between the two labels.
percent_second_label = ops.linspace(0, 1, num_interpolation)[:, None]
percent_second_label = ops.cast(percent_second_label, "float32")
interpolation_labels = (
first_label * (1 - percent_second_label) + second_label * percent_second_label
)
# Combine the noise and the labels and run inference with the generator.
noise_and_labels = ops.concatenate([interpolation_noise, interpolation_labels], 1)
fake = trained_gen.predict(noise_and_labels)
return fake
start_class = 8 # @param {type:"slider", min:0, max:9, step:1}
end_class = 6 # @param {type:"slider", min:0, max:9, step:1}
fake_images = interpolate_class(start_class, end_class)
output:
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 427ms/step
در اینجا، ابتدا نویز را از یک توزیع نرمال نمونهبرداری میکنیم و سپس آن را به تعداد "درون یابی"بار تکرار میکنیم و نتیجه را مطابقاً تغییر شکل میدهیم. سپس آن را به صورت یکنواخت برای "درون یابی" توزیع میکنیم و هویت برچسبها در نسبتی مشخص حاضر است.
:سوالات
(GAN)سوال ۱:شبکههای تولیدی مقابلهای چه امکانی را به ما میدهد ؟ الف) ایجاد دادههای تصویری ویدیویی و صوتی جدید ب) کنترل ظاهر نمونههای تولید شده ج) تولید دادههای عددی د) تولید دادههای متنی
(GAN)سوال ۲: چه اطلاعاتی باید به عنوان ورودی معنایی به شبکههای تولیدی مقابله ای داده شود؟ الف) یک بردار ب) یک تصویر ج) اطلاعات مربوط به کلاس یا ویژگی مورد نظر
سوال ۳: چه تفاوتی بین دیسکریمیناتور و مولد در یک شبکه تولیدی مقابلهای وجود دارد؟
الف ) دیسکریمیناتور داده هارا تولید میکند و مولد انهارا تشخیص میدهد
ب ) دیسکریمیناتور سعی میکند داده های تولید شده را از داده های واقعی تشخیص دهد در حالی که مولد سعی میکند داده های جدید تولید کند
ج ) دیسکریمیناتور داده های واقعی را تولید میکند و مولد داده های مصنوعی را تولید میکند
(GAN)سوال ۴: چرا استفاده از شبکههای تولیدی مقابلهای در تولید دادههای تصویری مورد توجه قرار گرفته است؟ الف) به علت امکان ایجاد دادههای واقعگرایانه و شبیه به دادههای واقعی ب) به علت قابلیت کنترل کامل بر فرایند تولید داده ج) به علت سرعت بالای پردازش در تولید دادههای تصویری د) به علت امکان استفاده از منابع کمتر در مقایسه با روشهای سنتی