خلاصه سازی متن

/*! elementor - v3.17.0 - 08-11-2023 */ .elementor-heading-title{padding:0;margin:0;line-height:1}.elementor-widget-heading .elementor-heading-title[class*=elementor-size-]>a{color:inherit;font-size:inherit;line-height:inherit}.elementor-widget-heading .elementor-heading-title.elementor-size-small{font-size:15px}.elementor-widget-heading .elementor-heading-title.elementor-size-medium{font-size:19px}.elementor-widget-heading .elementor-heading-title.elementor-size-large{font-size:29px}.elementor-widget-heading .elementor-heading-title.elementor-size-xl{font-size:39px}.elementor-widget-heading .elementor-heading-title.elementor-size-xxl{font-size:59px}
text summarizer (خلاصه سلزی متن با transformer)
تعریف خلاصه سازی متن: گرفتن یک متن بلند و دادن یک متن با تعداد کلمات کمتر ولی هم مفهوم با متن قبلی
ابتدا با انواع خلاصه سازی آشنا شویم
- 1 - Extractive Summarization
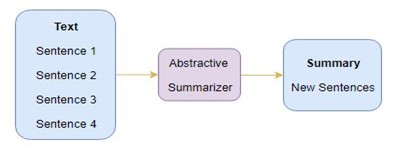
- 2 - Abstractive Summarization
در Extractive summarization به اینگونه هست که یک سری جمله از جملات انتخاب میکنیم میکنیم و روی آنها مدل را ران میکنیم:
/*! elementor - v3.17.0 - 08-11-2023 */ .elementor-widget-image{text-align:center}.elementor-widget-image a{display:inline-block}.elementor-widget-image a img[src$=".svg"]{width:48px}.elementor-widget-image img{vertical-align:middle;display:inline-block}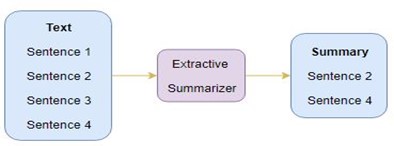
در حالت abstractive summarization به اینگونه هست که متن را میگیرد و یک متن جدید میسازد که این حالت را با دیتا ست cnn text summary آن را انجام میدهیم
برای انجام این کار ما نیاز به یک معماری به نام teacher forcing است که به اینگونه عمل میکند
یک ورودی که همان متن اصلی است را میگیرد و که به این بخش encoder میگویند
یک ورودی دیگر که به بخش decoder میرود و آن همان متن خلاصه شده است
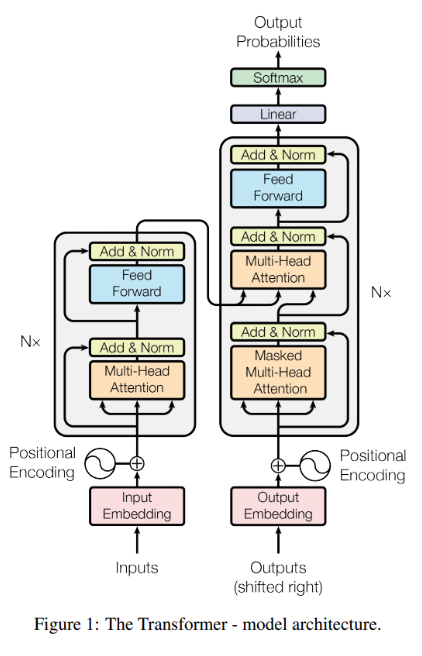
که این را با معماری transformer انجام میدهیم:
 ابتدا دیتا های خود را لود میکنیم:
** چون محدودیت gpu داشتیم تعداد دیتا ها کم می کنیم و فقط تعداد 120000 تا از آنها را می آوریم
import tensorflow as tfimport numpy as npimport matplotlib.pyplot as pltimport pandas as pdimport redataset = pd.read_csv('summarizer/Reviews.csv', low_memory=False)dataset.drop_duplicates(subset=['Text'], inplace=True)dataset = dataset[['Summary', 'Text']]dataset = dataset.iloc[:120000]dataset['Summary'] = dataset['Summary'].astype(str)dataset['Text'] = dataset['Text'].astype(str)train_dataset = dataset.iloc[:int(len(dataset)*.8)]val_dataset = dataset.iloc[int(len(dataset)*.8):]a = []for i in dataset['Summary']: a.append('startofseq ' + i + ' endofseq')
از این دیکشنری هم در مپ کردن دیتا استفاده میشود:
contraction_mapping = {"ain't": "is not", "aren't": "are not","can't": "cannot", "'cause": "because", "could've": "could have", "couldn't": "could not", "didn't": "did not", "doesn't": "does not", "don't": "do not", "hadn't": "had not", "hasn't": "has not", "haven't": "have not", "he'd": "he would","he'll": "he will", "he's": "he is", "how'd": "how did", "how'd'y": "how do you", "how'll": "how will", "how's": "how is", "I'd": "I would", "I'd've": "I would have", "I'll": "I will", "I'll've": "I will have","I'm": "I am", "I've": "I have", "i'd": "i would", "i'd've": "i would have", "i'll": "i will", "i'll've": "i will have","i'm": "i am", "i've": "i have", "isn't": "is not", "it'd": "it would", "it'd've": "it would have", "it'll": "it will", "it'll've": "it will have","it's": "it is", "let's": "let us", "ma'am": "madam", "mayn't": "may not", "might've": "might have","mightn't": "might not","mightn't've": "might not have", "must've": "must have", "mustn't": "must not", "mustn't've": "must not have", "needn't": "need not", "needn't've": "need not have","o'clock": "of the clock", "oughtn't": "ought not", "oughtn't've": "ought not have", "shan't": "shall not", "sha'n't": "shall not", "shan't've": "shall not have", "she'd": "she would", "she'd've": "she would have", "she'll": "she will", "she'll've": "she will have", "she's": "she is", "should've": "should have", "shouldn't": "should not", "shouldn't've": "should not have", "so've": "so have","so's": "so as", "this's": "this is","that'd": "that would", "that'd've": "that would have", "that's": "that is", "there'd": "there would", "there'd've": "there would have", "there's": "there is", "here's": "here is","they'd": "they would", "they'd've": "they would have", "they'll": "they will", "they'll've": "they will have", "they're": "they are", "they've": "they have", "to've": "to have", "wasn't": "was not", "we'd": "we would", "we'd've": "we would have", "we'll": "we will", "we'll've": "we will have", "we're": "we are", "we've": "we have", "weren't": "were not", "what'll": "what will", "what'll've": "what will have", "what're": "what are", "what's": "what is", "what've": "what have", "when's": "when is", "when've": "when have", "where'd": "where did", "where's": "where is", "where've": "where have", "who'll": "who will", "who'll've": "who will have", "who's": "who is", "who've": "who have", "why's": "why is", "why've": "why have", "will've": "will have", "won't": "will not", "won't've": "will not have", "would've": "would have", "wouldn't": "would not", "wouldn't've": "would not have", "y'all": "you all", "y'all'd": "you all would","y'all'd've": "you all would have","y'all're": "you all are","y'all've": "you all have", "you'd": "you would", "you'd've": "you would have", "you'll": "you will", "you'll've": "you will have", "you're": "you are", "you've": "you have"}
از این تابع هم برای پیش پردازشی که روی داده ها داریم استفاده میکینم
از آن آرایه a که داریم فقط برای این استفاده میکنیم که به اول و آخر همه خلاصه ها چیز ثابتی را اضافه کند تا بتوانیم آن را به مدل خود بدهیم ولی این آرایه برای آن است که آن را به text_vecotorization_layer بدهیمش:
def preprocess_text(text, flag): text = tf.strings.lower(text) text = tf.strings.regex_replace(text, r'<br />' ,'') text = tf.strings.regex_replace(text, r'</ br>' ,'')
text = tf.strings.regex_replace(text, r'([^)]*)', '') text = tf.strings.regex_replace(text, '"', '') def replace_contractions(text): for key, value in contraction_mapping.items(): text = tf.strings.regex_replace(text, key, value) return text text = tf.numpy_function(replace_contractions, [text], tf.string) text = tf.strings.regex_replace(text, r"'sb", "") text = tf.strings.regex_replace(text, "[^a-zA-Z]", " ") text = tf.strings.strip(text) def remove_short_words(text): pattern = r'bw{1,3}b' text = tf.strings.regex_replace(text, pattern, '') text = tf.strings.strip(text) return text if flag: text = remove_short_words(text) return texttext_vectorization_layer = tf.keras.layers.TextVectorization(max_tokens=1000, output_sequence_length=80)text_vectorization_layer.adapt(preprocess_text(dataset['Text'], True))summary_vectorization_layer = tf.keras.layers.TextVectorization(max_tokens=1000, output_sequence_length=80)summary_vectorization_layer.adapt(preprocess_text(a, False))
برای لود دیتا:
@tf.functiondef load_data(text_batch, label_batch):
batch_size = text_batch.shape batch_size = batch_size[0] text_batch = preprocess_text(text_batch, True) label_batch = preprocess_text(label_batch, False) start_token = tf.constant(['startofseq ']*batch_size) end_token = tf.constant([' endofseq']*batch_size) l = tf.constant(['']*batch_size) text_batch = tf.strings.join([l, text_batch]) x_train_dec = tf.strings.join([start_token, label_batch]) y_train = tf.strings.join([label_batch, end_token]) text_batch = text_vectorization_layer(text_batch) x_train_dec = summary_vectorization_layer(x_train_dec) y_train = summary_vectorization_layer(y_train) return (text_batch, x_train_dec), y_traintrain_ds = tf.data.Dataset.from_tensor_slices( (tf.convert_to_tensor(train_dataset['Text']), tf.convert_to_tensor(train_dataset['Summary'])))train_ds = train_ds.batch(128, drop_remainder=True)train_ds = train_ds.map(load_data)val_ds = tf.data.Dataset.from_tensor_slices( (tf.convert_to_tensor(val_dataset['Text']), tf.convert_to_tensor(val_dataset['Summary'])))val_ds = val_ds.batch(128, drop_remainder=True)val_ds = val_ds.map(load_data)max_length = 80vocab_size = 1000num_heads = 8dropout_rate = .1n_units = 128N = 2embed_size = 128
ابتدا دیتا های خود را لود میکنیم:
** چون محدودیت gpu داشتیم تعداد دیتا ها کم می کنیم و فقط تعداد 120000 تا از آنها را می آوریم
import tensorflow as tfimport numpy as npimport matplotlib.pyplot as pltimport pandas as pdimport redataset = pd.read_csv('summarizer/Reviews.csv', low_memory=False)dataset.drop_duplicates(subset=['Text'], inplace=True)dataset = dataset[['Summary', 'Text']]dataset = dataset.iloc[:120000]dataset['Summary'] = dataset['Summary'].astype(str)dataset['Text'] = dataset['Text'].astype(str)train_dataset = dataset.iloc[:int(len(dataset)*.8)]val_dataset = dataset.iloc[int(len(dataset)*.8):]a = []for i in dataset['Summary']: a.append('startofseq ' + i + ' endofseq')
از این دیکشنری هم در مپ کردن دیتا استفاده میشود:
contraction_mapping = {"ain't": "is not", "aren't": "are not","can't": "cannot", "'cause": "because", "could've": "could have", "couldn't": "could not", "didn't": "did not", "doesn't": "does not", "don't": "do not", "hadn't": "had not", "hasn't": "has not", "haven't": "have not", "he'd": "he would","he'll": "he will", "he's": "he is", "how'd": "how did", "how'd'y": "how do you", "how'll": "how will", "how's": "how is", "I'd": "I would", "I'd've": "I would have", "I'll": "I will", "I'll've": "I will have","I'm": "I am", "I've": "I have", "i'd": "i would", "i'd've": "i would have", "i'll": "i will", "i'll've": "i will have","i'm": "i am", "i've": "i have", "isn't": "is not", "it'd": "it would", "it'd've": "it would have", "it'll": "it will", "it'll've": "it will have","it's": "it is", "let's": "let us", "ma'am": "madam", "mayn't": "may not", "might've": "might have","mightn't": "might not","mightn't've": "might not have", "must've": "must have", "mustn't": "must not", "mustn't've": "must not have", "needn't": "need not", "needn't've": "need not have","o'clock": "of the clock", "oughtn't": "ought not", "oughtn't've": "ought not have", "shan't": "shall not", "sha'n't": "shall not", "shan't've": "shall not have", "she'd": "she would", "she'd've": "she would have", "she'll": "she will", "she'll've": "she will have", "she's": "she is", "should've": "should have", "shouldn't": "should not", "shouldn't've": "should not have", "so've": "so have","so's": "so as", "this's": "this is","that'd": "that would", "that'd've": "that would have", "that's": "that is", "there'd": "there would", "there'd've": "there would have", "there's": "there is", "here's": "here is","they'd": "they would", "they'd've": "they would have", "they'll": "they will", "they'll've": "they will have", "they're": "they are", "they've": "they have", "to've": "to have", "wasn't": "was not", "we'd": "we would", "we'd've": "we would have", "we'll": "we will", "we'll've": "we will have", "we're": "we are", "we've": "we have", "weren't": "were not", "what'll": "what will", "what'll've": "what will have", "what're": "what are", "what's": "what is", "what've": "what have", "when's": "when is", "when've": "when have", "where'd": "where did", "where's": "where is", "where've": "where have", "who'll": "who will", "who'll've": "who will have", "who's": "who is", "who've": "who have", "why's": "why is", "why've": "why have", "will've": "will have", "won't": "will not", "won't've": "will not have", "would've": "would have", "wouldn't": "would not", "wouldn't've": "would not have", "y'all": "you all", "y'all'd": "you all would","y'all'd've": "you all would have","y'all're": "you all are","y'all've": "you all have", "you'd": "you would", "you'd've": "you would have", "you'll": "you will", "you'll've": "you will have", "you're": "you are", "you've": "you have"}
از این تابع هم برای پیش پردازشی که روی داده ها داریم استفاده میکینم
از آن آرایه a که داریم فقط برای این استفاده میکنیم که به اول و آخر همه خلاصه ها چیز ثابتی را اضافه کند تا بتوانیم آن را به مدل خود بدهیم ولی این آرایه برای آن است که آن را به text_vecotorization_layer بدهیمش:
def preprocess_text(text, flag): text = tf.strings.lower(text) text = tf.strings.regex_replace(text, r'<br />' ,'') text = tf.strings.regex_replace(text, r'</ br>' ,'')
text = tf.strings.regex_replace(text, r'([^)]*)', '') text = tf.strings.regex_replace(text, '"', '') def replace_contractions(text): for key, value in contraction_mapping.items(): text = tf.strings.regex_replace(text, key, value) return text text = tf.numpy_function(replace_contractions, [text], tf.string) text = tf.strings.regex_replace(text, r"'sb", "") text = tf.strings.regex_replace(text, "[^a-zA-Z]", " ") text = tf.strings.strip(text) def remove_short_words(text): pattern = r'bw{1,3}b' text = tf.strings.regex_replace(text, pattern, '') text = tf.strings.strip(text) return text if flag: text = remove_short_words(text) return texttext_vectorization_layer = tf.keras.layers.TextVectorization(max_tokens=1000, output_sequence_length=80)text_vectorization_layer.adapt(preprocess_text(dataset['Text'], True))summary_vectorization_layer = tf.keras.layers.TextVectorization(max_tokens=1000, output_sequence_length=80)summary_vectorization_layer.adapt(preprocess_text(a, False))
برای لود دیتا:
@tf.functiondef load_data(text_batch, label_batch):
batch_size = text_batch.shape batch_size = batch_size[0] text_batch = preprocess_text(text_batch, True) label_batch = preprocess_text(label_batch, False) start_token = tf.constant(['startofseq ']*batch_size) end_token = tf.constant([' endofseq']*batch_size) l = tf.constant(['']*batch_size) text_batch = tf.strings.join([l, text_batch]) x_train_dec = tf.strings.join([start_token, label_batch]) y_train = tf.strings.join([label_batch, end_token]) text_batch = text_vectorization_layer(text_batch) x_train_dec = summary_vectorization_layer(x_train_dec) y_train = summary_vectorization_layer(y_train) return (text_batch, x_train_dec), y_traintrain_ds = tf.data.Dataset.from_tensor_slices( (tf.convert_to_tensor(train_dataset['Text']), tf.convert_to_tensor(train_dataset['Summary'])))train_ds = train_ds.batch(128, drop_remainder=True)train_ds = train_ds.map(load_data)val_ds = tf.data.Dataset.from_tensor_slices( (tf.convert_to_tensor(val_dataset['Text']), tf.convert_to_tensor(val_dataset['Summary'])))val_ds = val_ds.batch(128, drop_remainder=True)val_ds = val_ds.map(load_data)max_length = 80vocab_size = 1000num_heads = 8dropout_rate = .1n_units = 128N = 2embed_size = 128
حال نوبت به نوشتن positional encoder میرسد برای مشخص کردن اینکه هر کلمه در کجای جمله قرار دارد:
class PositionalEncoding(tf.keras.layers.Layer): def __init__(self, max_length, embed_size, dtype=tf.float32, **kwargs): super().__init__(dtype=dtype, **kwargs) assert embed_size % 2 == 0, "embed_size must be even" p, i = np.meshgrid(np.arange(max_length), 2 * np.arange(embed_size // 2)) pos_emb = np.empty((1, max_length, embed_size)) pos_emb[0, :, ::2] = np.sin(p / 10_000 ** (i / embed_size)).T pos_emb[0, :, 1::2] = np.cos(p / 10_000 ** (i / embed_size)).T self.pos_encodings = tf.constant(pos_emb.astype(self.dtype)) self.supports_masking = True def call(self, inputs): batch_max_length = tf.shape(inputs)[1] return inputs + self.pos_encodings[:, :batch_max_length]بعد از این نوبت به نوشتن انکودر میشود:
class Encoder(tf.keras.Model): def __init__(self, embed_size): super().__init__() self.encoder_embedding = tf.keras.layers.Embedding(vocab_size, embed_size, mask_zero=True) self.pos_embed_layer = tf.keras.layers.Embedding(max_length, embed_size) self.pos_en = PositionalEncoding(max_length, embed_size) self.att1 = tf.keras.layers.MultiHeadAttention(num_heads=num_heads, key_dim=embed_size, dropout=dropout_rate) self.norm1 = tf.keras.layers.LayerNormalization() self.Dense1 = tf.keras.layers.Dense(n_units, activation="relu") self.Dense2 = tf.keras.layers.Dense(embed_size) self.dropout = tf.keras.layers.Dropout(dropout_rate) self.norm2 = tf.keras.layers.LayerNormalization() def call(self, inputs, training=True): embed_outpot = self.encoder_embedding(inputs) pos_embed_layer = self.pos_en encoder_in = pos_embed_layer(embed_outpot) encoder_pad_mask = tf.math.not_equal(inputs, 0)[:, tf.newaxis] Z = encoder_in for _ in range(N): skip = Z attn_layer = self.att1 Z = attn_layer(Z, value=Z, attention_mask=encoder_pad_mask) Z = self.norm1(tf.keras.layers.Add()([Z, skip])) skip = Z Z = self.Dense1(Z) Z = self.Dense2(Z) Z = self.dropout(Z) Z = self.norm2(tf.keras.layers.Add()([Z, skip])) return Z,encoder_pad_maskو بعد از این decoder خود را میسازیم:
یک تفاوت در دادن به ورودی به دیکودر هست بعد از اینکه positional_encoding روی ورودی انجام میشود در انکودر آنها را mask میکنیم که آن مقدار هایی که مقدار صفر دارند در نظر گرفته نشون (paddings) ولی در انکودر علاوه برانجام این باید آن را causal هم کنیم چون در دیکودر ما نیاز به این نداریم بدانیم که بعد از این چه چیزی وجود دارد ولی در انکودر نیاز هست(مانند bidirectional rnn)
class Decoder(tf.keras.Model): def __init__(self, embed_size): super().__init__() self.embedding = tf.keras.layers.Embedding(vocab_size, embed_size, mask_zero=True) self.pos_de = PositionalEncoding(max_length, embed_size) self.mask_att = tf.keras.layers.MultiHeadAttention(num_heads=num_heads, key_dim=embed_size, dropout=dropout_rate) self.norm1 = tf.keras.layers.LayerNormalization() self.cross_att = tf.keras.layers.MultiHeadAttention( num_heads=num_heads, key_dim=embed_size, dropout=dropout_rate) self.norm2 = tf.keras.layers.LayerNormalization() self.Dense1 = tf.keras.layers.Dense(n_units, activation="relu") self.Dense2 = tf.keras.layers.Dense(embed_size) self.norm3 = tf.keras.layers.LayerNormalization() def call(self, inputs1, training = True): l, decoder_input_ids = inputs1 Z, encoder_pad_mask = l embedding_output = self.embedding(decoder_input_ids) pos_embed_layer = self.pos_de decoder_in = pos_embed_layer(embedding_output) decoder_pad_mask = tf.math.not_equal(decoder_input_ids, 0)[:, tf.newaxis] batch_max_len_dec = tf.shape(embedding_output)[1] causal_mask = tf.linalg.band_part( tf.ones((batch_max_len_dec, batch_max_len_dec), tf.bool), -1, 0) encoder_outputs = Z Z = decoder_in for _ in range(N): skip = Z attn_layer = self.mask_att Z = attn_layer(Z, value=Z, attention_mask=causal_mask & decoder_pad_mask) Z = self.norm1(tf.keras.layers.Add()([Z, skip])) skip = Z attn_layer = self.cross_att Z = attn_layer(Z, value=encoder_outputs, attention_mask=encoder_pad_mask) Z = self.norm2(tf.keras.layers.Add()([Z, skip])) skip = Z Z = self.Dense1(Z) Z = self.Dense2(Z) Z = self.norm3(tf.keras.layers.Add()([Z, skip])) return Zو حال نوبت به نوشتن کلاسی میرسد که در آن از encoder , decoder استفاده شود
class Summarizer(tf.keras.Model): def __init__(self, vocab_size, embed_size): super().__init__() self.encoder = Encoder(embed_size) self.decoder = Decoder(embed_size) self.output_layer = tf.keras.layers.Dense(vocab_size, activation='softmax') def call(self, inputs, trainging=True): encoder_inputs_ids, decoder_inputs_ids = inputs encoder_outputs= self.encoder(encoder_inputs_ids) Z = self.decoder((encoder_outputs, decoder_inputs_ids)) Y_proba = self.output_layer(Z) return Y_probamodel = Summarizer(vocab_size, embed_size)model.compile(loss="sparse_categorical_crossentropy", optimizer="nadam", metrics=["accuracy"])history = model.fit(train_ds, epochs=30, validation_data=val_ds, batch_size=128) تابعی برای inference time: def summaraize(sentense_en): summaraization = 'startofseq ' for word_idx in range(max_length): X = np.array([sentense_en]) X_dec = np.array([summaraization]) y_proba = model.predict((X, X_dec))[0, word_idx] predicted_word_idx = np.argmax(y_proba) predicted_word = summary_vectorization_layer.get_vocabulary()[predicted_word_idx] if predicted_word == 'endofseq': break summaraization += ' ' + predicted_word return summaraization.strip('startofseq ')