پلاک خوان

مقدمه و معرفی
پروژه شناسایی پلاک خودرو با استفاده از هوش مصنوعی به عنوان یک گام مهم در جهت بهبود سیستمهای نظارت و کنترل ترافیک شهری و همچنین استفاده در پارکینگ ها طراحی و اجرا شده است. این پروژه با هدف جمعآوری دادههای تصویری از پلاک خودروها و پردازش آنها به منظور تشخیص و خواندن کاراکترهای پلاک، توسعه یافته است. بهکارگیری تکنولوژیهای پیشرفته در این پروژه، شامل استفاده از الگوریتمهای یادگیری عمیق و فریم ورکهای تخصصی هوش مصنوعی، به دستیابی به دقت و کارآیی بالای سیستم کمک شایانی می کند.
پیادهسازی پروژه با YOLOv8 و TensorFlow
در این پروژه، از نسخه هشتم الگوریتم YOLO (You Only Look Once) برای شناسایی پلاک خودروها استفاده شده است. YOLOv8 به عنوان یکی از پیشرفتهترین الگوریتمهای تشخیص اشیا، توانایی تشخیص سریع و دقیق پلاک خودروها را فراهم میکند. همچنین، برای پردازش و آموزش مدلهای یادگیری عمیق، از فریم ورک TensorFlow وKeras استفاده شده است که یکی از پرکاربردترین و قدرتمندترین ابزارهای هوش مصنوعی در دنیا محسوب میشوند.
جمعآوری دادهها و مزایای پروژه
یکی از مهمترین مزایای این پروژه، جمعآوری حجم زیادی از دادههای تصویری از پلاک خودروها است. این دادهها برای تشخیص پلاک خودروها و همچنین برای خواندن دقیق کاراکترهای موجود در پلاکها مورد استفاده قرار میگیرند. با استفاده از این مجموعه دادهها، مدل توانسته است دقت و کارایی بسیار بالایی در شناسایی و تفسیر پلاکها از خود نشان دهد. این ویژگی، امکان پیادهسازی سیستمهای نظارت هوشمندتر و کارآمدتر را در محیطهای مختلف فراهم میکند.
پروژه شناسایی پلاک خودرو با بهرهگیری از تکنولوژیهای پیشرفته هوش مصنوعی، گامی مهم در جهت بهبود سیستمهای ترافیکی و امنیتی است و میتواند به کاهش تخلفات رانندگی و بهبود مدیریت ترافیک کمک کند.
نمای کلی پروژه
 مراحل پروژه
مراحل پروژه
- جمع آوری دیتا برای تشخیص پلاک
- آموزش یولو ورژن 8
- جمع آوری دیتا برای خواندن پلاک
- ساخت پلاک جنریتور
- برچسب گذاری پلاک های واقعی
- ساخت مدل برای خواندن پلاک
- مقایسه و بهبود مدل
- تست نهایی مدل
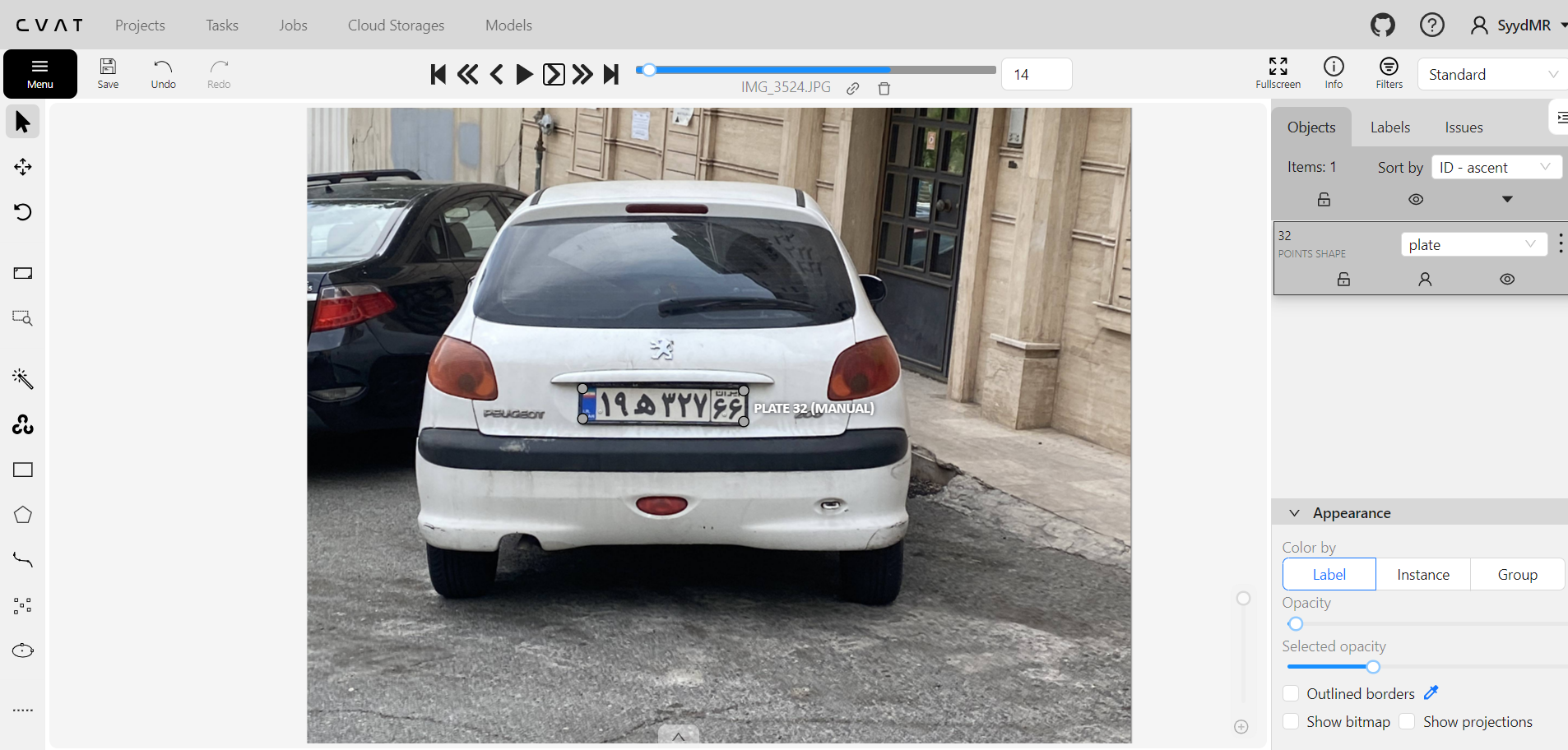 کشیدن مستطیل با 2 نقطه در اطراف پلاک
کشیدن مستطیل با 2 نقطه در اطراف پلاک
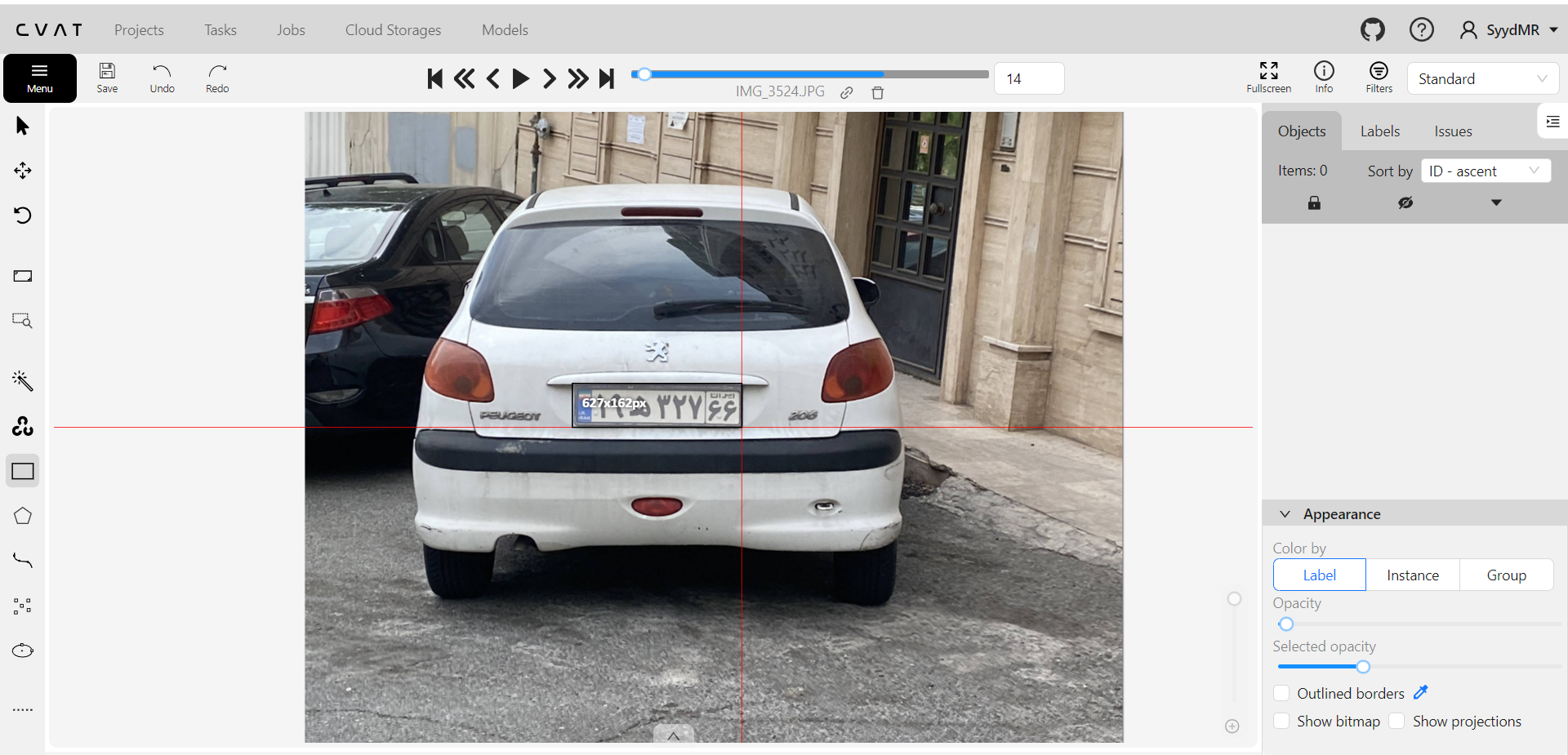 آموزش یولو ورژن 8
پس از آمادهسازی دادهها و انجام برچسبگذاری، مدل YOLO (You Only Look Once) نسخه 8 برای تشخیص پلاکها آموزش داده شد . YOLO یکی از قدرتمندترین مدلهای تشخیص اشیاء است که به دلیل سرعت و دقت بالایش شناخته میشود. نسخه 8 این مدل شامل بهبودهای قابل توجهی در معماری و الگوریتمهای یادگیری است که به افزایش دقت و سرعت در تشخیص اشیاء کمک میکند. دادههای برچسبگذاری شده به مدل وارد شده و مدل با استفاده از این دادهها آموزش داده شد. در این مرحله، پارامترهای مختلف مدل از جمله نرخ یادگیری، تعداد دورههای آموزشی، و اندازه دستهها (batch size) تنظیم شدند تا بهترین عملکرد ممکن حاصل شود.
لینک کد در گیت هاب: https://github.com/SyydMR/PlateLicense/blob/master/Yolo/YoloPoseDetection/Yolo_PoseDetection.ipynb
جمع آوری دیتا برای خواندن پلاک
آموزش یولو ورژن 8
پس از آمادهسازی دادهها و انجام برچسبگذاری، مدل YOLO (You Only Look Once) نسخه 8 برای تشخیص پلاکها آموزش داده شد . YOLO یکی از قدرتمندترین مدلهای تشخیص اشیاء است که به دلیل سرعت و دقت بالایش شناخته میشود. نسخه 8 این مدل شامل بهبودهای قابل توجهی در معماری و الگوریتمهای یادگیری است که به افزایش دقت و سرعت در تشخیص اشیاء کمک میکند. دادههای برچسبگذاری شده به مدل وارد شده و مدل با استفاده از این دادهها آموزش داده شد. در این مرحله، پارامترهای مختلف مدل از جمله نرخ یادگیری، تعداد دورههای آموزشی، و اندازه دستهها (batch size) تنظیم شدند تا بهترین عملکرد ممکن حاصل شود.
لینک کد در گیت هاب: https://github.com/SyydMR/PlateLicense/blob/master/Yolo/YoloPoseDetection/Yolo_PoseDetection.ipynb
جمع آوری دیتا برای خواندن پلاک
- ساخت پلاک جنریتور
- برچسب گذاری پلاک های واقعی
Attention Model
 مقایسه و بهبود مدل
پس از ساخت و آموزش مدلها، نتایج آنها با استفاده از معیارهای مختلف، ارزیابی و مقایسه شدند، که برای ارزیابی عملکرد مدلها مورد استفاده قرار گرفتند. مدلهایی که از مکانیزم Attention استفاده میکردند، عملکرد بهتری در خواندن پلاک داشتند. با استفاده از روش Teacher Forcing نیز دقت مدلها به طور قابل توجهی افزایش یافت. مدلها به طور مداوم بهینهسازی شدند و پارامترهای مختلف آنها تنظیم شدند تا بهترین عملکرد ممکن حاصل شود.
هر 3 مدل CNN، مبتنی بر Attention و مدل Attention با استفاده از روش Teacher Forcing ،در 4 نمودار مختلف معیارهای Loss Train ،Loss Validation ،Accuracy Train و
Accuracy Validation هرکدام از آنها مقایسه شدهاند.
لینک کد در گیت هاب : https://github.com/SyydMR/PlateLicense/blob/master/TestModels/%20ModelEvaluation.ipynb
مقایسه و بهبود مدل
پس از ساخت و آموزش مدلها، نتایج آنها با استفاده از معیارهای مختلف، ارزیابی و مقایسه شدند، که برای ارزیابی عملکرد مدلها مورد استفاده قرار گرفتند. مدلهایی که از مکانیزم Attention استفاده میکردند، عملکرد بهتری در خواندن پلاک داشتند. با استفاده از روش Teacher Forcing نیز دقت مدلها به طور قابل توجهی افزایش یافت. مدلها به طور مداوم بهینهسازی شدند و پارامترهای مختلف آنها تنظیم شدند تا بهترین عملکرد ممکن حاصل شود.
هر 3 مدل CNN، مبتنی بر Attention و مدل Attention با استفاده از روش Teacher Forcing ،در 4 نمودار مختلف معیارهای Loss Train ،Loss Validation ،Accuracy Train و
Accuracy Validation هرکدام از آنها مقایسه شدهاند.
لینک کد در گیت هاب : https://github.com/SyydMR/PlateLicense/blob/master/TestModels/%20ModelEvaluation.ipynb
Loss train
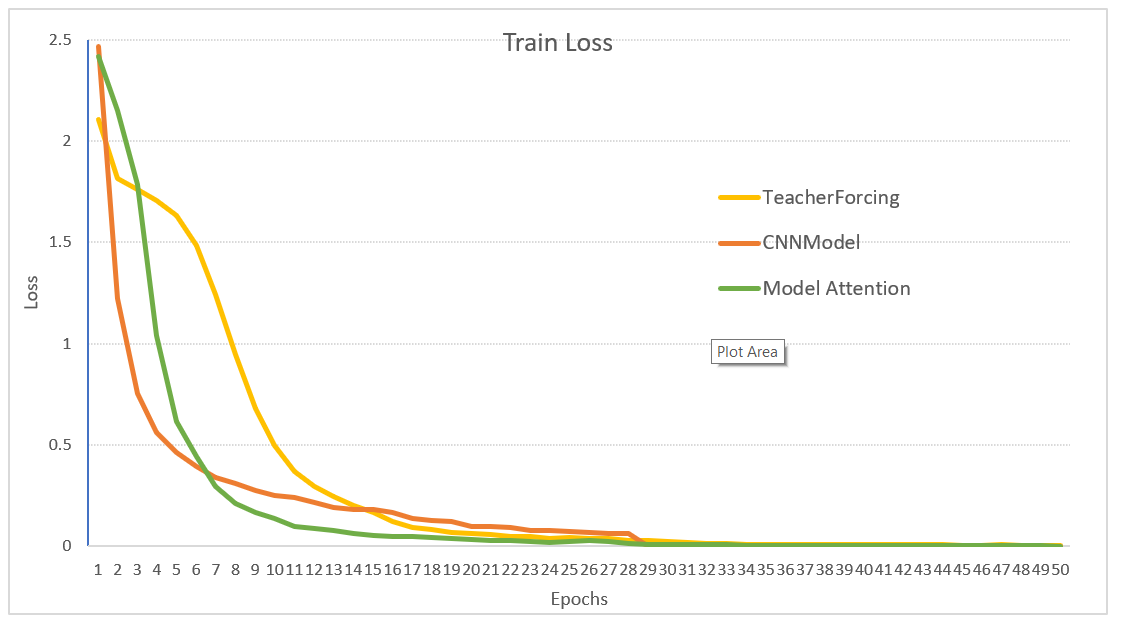 این نمودار نشاندهنده میزان کاهش خطا (Loss) در دادههای آموزشی در طول زمان آموزش مدلهای مختلف است. هدف از این نمودار مقایسه نرخ کاهش خطا در هر یک از مدلها و تحلیل عملکرد آنها در حین آموزش است.
کاهش سریعتر خطا به معنای یادگیری بهتر و سریعتر مدل است. این نمودار به ما نشان میدهد که کدام مدل توانسته است با سرعت بیشتری به دقت مطلوب برسد.
این نمودار نشاندهنده میزان کاهش خطا (Loss) در دادههای آموزشی در طول زمان آموزش مدلهای مختلف است. هدف از این نمودار مقایسه نرخ کاهش خطا در هر یک از مدلها و تحلیل عملکرد آنها در حین آموزش است.
کاهش سریعتر خطا به معنای یادگیری بهتر و سریعتر مدل است. این نمودار به ما نشان میدهد که کدام مدل توانسته است با سرعت بیشتری به دقت مطلوب برسد.
Loss Validation
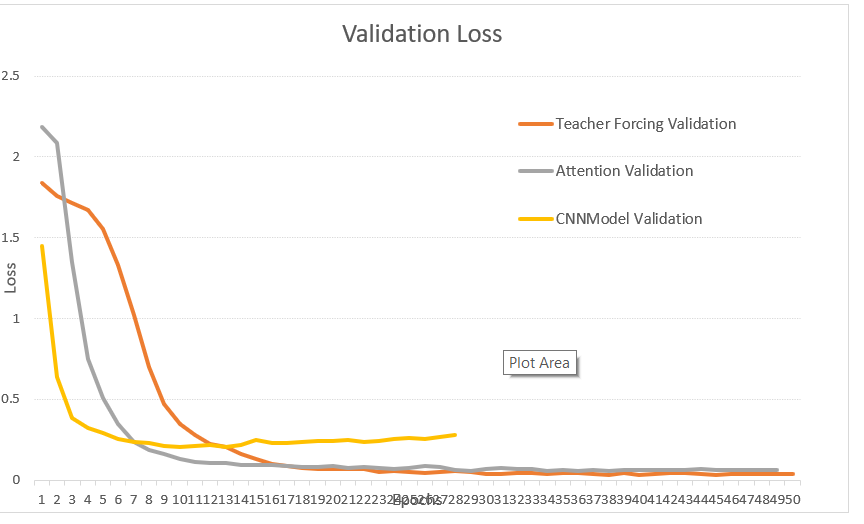 این نمودار میزان کاهش خطا (Loss) در دادههای اعتبارسنجی را در طول زمان نشان میدهد. مانند نمودار قبلی، مدلهای مختلف در این نمودار مقایسه شدهاند تا بتوان عملکرد آنها را در دادههایی که قبلاً در آموزش استفاده نشدهاند، ارزیابی کرد.
این نمودار به ما کمک میکند تا اطمینان حاصل کنیم که مدلها به طور کلی تعمیمپذیری خوبی دارند و در مواجهه با دادههای جدید نیز عملکرد مناسبی دارند. کاهش خطا در دادههای اعتبارسنجی نشاندهنده این است که مدلها از پس دادههای جدید به خوبی برمیآیند و دچار بیشبرازش (overfitting) نشدهاند.
این نمودار میزان کاهش خطا (Loss) در دادههای اعتبارسنجی را در طول زمان نشان میدهد. مانند نمودار قبلی، مدلهای مختلف در این نمودار مقایسه شدهاند تا بتوان عملکرد آنها را در دادههایی که قبلاً در آموزش استفاده نشدهاند، ارزیابی کرد.
این نمودار به ما کمک میکند تا اطمینان حاصل کنیم که مدلها به طور کلی تعمیمپذیری خوبی دارند و در مواجهه با دادههای جدید نیز عملکرد مناسبی دارند. کاهش خطا در دادههای اعتبارسنجی نشاندهنده این است که مدلها از پس دادههای جدید به خوبی برمیآیند و دچار بیشبرازش (overfitting) نشدهاند.
Accuracy Train
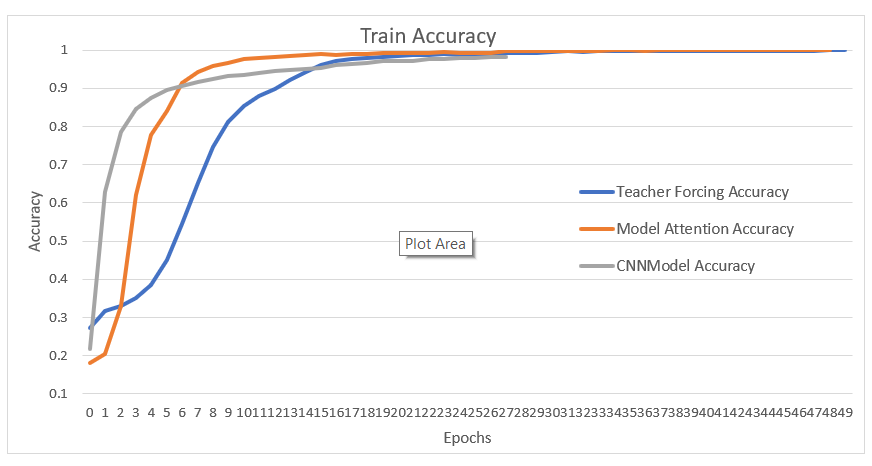 این نمودار دقت (Accuracy) مدلها را در دادههای آموزشی در طول زمان نشان میدهد.
افزایش دقت مدلها در دادههای آموزشی به معنای بهبود توانایی مدلها در شناسایی و خواندن پلاکها است. این نمودار به ما نشان میدهد که کدام مدل با سرعت بیشتری به دقت بالاتر دست یافته و در طول زمان عملکرد بهتری داشته است.
این نمودار دقت (Accuracy) مدلها را در دادههای آموزشی در طول زمان نشان میدهد.
افزایش دقت مدلها در دادههای آموزشی به معنای بهبود توانایی مدلها در شناسایی و خواندن پلاکها است. این نمودار به ما نشان میدهد که کدام مدل با سرعت بیشتری به دقت بالاتر دست یافته و در طول زمان عملکرد بهتری داشته است.
Accuracy Validation
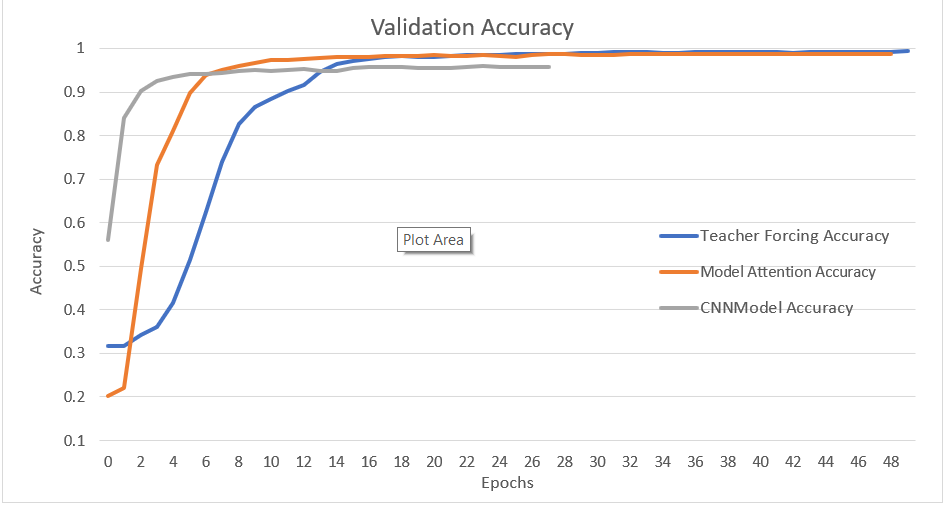 این نمودار دقت مدلها را در دادههای اعتبارسنجی در طول زمان نشان میدهد. مانند نمودارهای قبلی، مدلهای مختلف با یکدیگر مقایسه شدهاند تا بتوان عملکرد آنها را در دادههایی که در آموزش استفاده نشدهاند، ارزیابی کرد.
این نمودار به ما کمک میکند تا ارزیابی کنیم که مدلها چقدر توانایی دارند در دادههای جدید و ناآشنا عملکرد خوبی داشته باشند. دقت بالاتر در دادههای اعتبارسنجی نشاندهنده تعمیمپذیری بهتر مدلها است و اطمینان میدهد که مدلها در شرایط واقعی نیز عملکرد مناسبی خواهند داشت.
تست نهایی مدل
در نهایت، مدلهای نهایی بر روی مجموعهای از دادههای تست که شامل تصاویری بودند که مدلها قبلاً ندیده بودند، آزمایش شدند. این دادهها شامل تصاویر پلاکهای خودرو در شرایط نوری و محیطی مختلف بودند تا عملکرد مدلها در شرایط واقعی سنجیده شود.
Test on CNN model
مدل CNN ، به عنوان اولین مدل آزمایشی مورد ارزیابی قرار گرفت.
Precision: 0.75
Recall: 0.73
F1-Score: 0.74
Accuracy: 0.92
این نمودار دقت مدلها را در دادههای اعتبارسنجی در طول زمان نشان میدهد. مانند نمودارهای قبلی، مدلهای مختلف با یکدیگر مقایسه شدهاند تا بتوان عملکرد آنها را در دادههایی که در آموزش استفاده نشدهاند، ارزیابی کرد.
این نمودار به ما کمک میکند تا ارزیابی کنیم که مدلها چقدر توانایی دارند در دادههای جدید و ناآشنا عملکرد خوبی داشته باشند. دقت بالاتر در دادههای اعتبارسنجی نشاندهنده تعمیمپذیری بهتر مدلها است و اطمینان میدهد که مدلها در شرایط واقعی نیز عملکرد مناسبی خواهند داشت.
تست نهایی مدل
در نهایت، مدلهای نهایی بر روی مجموعهای از دادههای تست که شامل تصاویری بودند که مدلها قبلاً ندیده بودند، آزمایش شدند. این دادهها شامل تصاویر پلاکهای خودرو در شرایط نوری و محیطی مختلف بودند تا عملکرد مدلها در شرایط واقعی سنجیده شود.
Test on CNN model
مدل CNN ، به عنوان اولین مدل آزمایشی مورد ارزیابی قرار گرفت.
Precision: 0.75
Recall: 0.73
F1-Score: 0.74
Accuracy: 0.92
 این نتایج نشان میدهند که مدل CNN توانایی قابل قبولی در تشخیص و خواندن پلاکها دارد، اما همچنان نیاز به بهبود دارد تا دقت و عملکرد بهتری ارائه دهد.
لینک کد در گیت هاب : https://github.com/SyydMR/PlateLicense/blob/master/Models/ModelCNN/CNNModel.ipynb
Test on Attention
مدل مبتنی بر Attention با هدف بهبود عملکرد مدل CNN طراحی و آزمایش شد.
Precision: 0.82
Recall: 0.82
F1-Score: 0.82
Accuracy: 0.96
این نتایج نشان میدهند که مدل CNN توانایی قابل قبولی در تشخیص و خواندن پلاکها دارد، اما همچنان نیاز به بهبود دارد تا دقت و عملکرد بهتری ارائه دهد.
لینک کد در گیت هاب : https://github.com/SyydMR/PlateLicense/blob/master/Models/ModelCNN/CNNModel.ipynb
Test on Attention
مدل مبتنی بر Attention با هدف بهبود عملکرد مدل CNN طراحی و آزمایش شد.
Precision: 0.82
Recall: 0.82
F1-Score: 0.82
Accuracy: 0.96
 نتایج این مدل نشان داد که مکانیزم Attention توانسته است به طور قابل توجهی دقت و کارایی مدل را در تشخیص و خواندن پلاکها افزایش دهد، که نشاندهنده مزیت استفاده از این تکنیک در مدلسازی است.
لینک کد در گیت هاب: https://github.com/SyydMR/PlateLicense/blob/master/Models/ModelAttention/ModelAttention.ipynb
Test on Attention with Teacher Forcing
مدل نهایی، شامل مکانیزم Attention با استفاده از روش Teacher Forcing، مورد آزمایش قرار گرفت.
Precision: 0.86
Recall: 0.86
F1-Score: 0.86
Accuracy: 0.97
نتایج این مدل نشان داد که مکانیزم Attention توانسته است به طور قابل توجهی دقت و کارایی مدل را در تشخیص و خواندن پلاکها افزایش دهد، که نشاندهنده مزیت استفاده از این تکنیک در مدلسازی است.
لینک کد در گیت هاب: https://github.com/SyydMR/PlateLicense/blob/master/Models/ModelAttention/ModelAttention.ipynb
Test on Attention with Teacher Forcing
مدل نهایی، شامل مکانیزم Attention با استفاده از روش Teacher Forcing، مورد آزمایش قرار گرفت.
Precision: 0.86
Recall: 0.86
F1-Score: 0.86
Accuracy: 0.97
 این نتایج نشان میدهند که استفاده از Teacher Forcing توانسته است دقت و کارایی مدل را به حداکثر برساند، و مدل نهایی با این روش توانسته است بهترین عملکرد را در میان تمامی مدلهای آزمایش شده ارائه دهد .
لینک کد در گیت هاب: https://github.com/SyydMR/PlateLicense/blob/master/Models/ModelTForcingAttention/Model.ipynb
نتایج نشان داد که مدلها قادر به تشخیص و خواندن پلاک خودروها با دقت بالایی هستند. عملکرد مدلها با استفاده از معیارهای مختلف ارزیابی شد و مدل نهایی که بهترین دقت و کارایی را داشت، انتخاب شد. مدل انتخاب شده توانست به خوبی پلاکهای خودرو را در شرایط مختلف تشخیص داده و بخواند، که نشان از موفقیت پروژه در رسیدن به اهدافش داشت.
نتیجه گیری
پروژه تشخیص و خواندن پلاک خودرو با استفاده از تکنیکهای پیشرفته هوش مصنوعی و یادگیری عمیق توانسته است به نتایج بسیار مطلوبی دست یابد. مدلهای مختلفی که در این پروژه مورد آزمایش قرار گرفتند، هر یک توانستند در شرایط مختلف عملکرد قابل قبولی داشته باشند. با این حال، مدل مبتنی بر Attention با استفاده از روش
Teacher Forcing بهترین نتایج را نشان داد و دقت و کارایی بالایی را در تشخیص و خواندن پلاکها ارائه کرد. این پروژه نشان داد که استفاده از تکنیکهای پیشرفته میتواند به طور قابل توجهی عملکرد سیستمهای نظارت و مدیریت ترافیک را بهبود بخشد و به کاهش تخلفات رانندگی کمک کند.
این نتایج نشان میدهند که استفاده از Teacher Forcing توانسته است دقت و کارایی مدل را به حداکثر برساند، و مدل نهایی با این روش توانسته است بهترین عملکرد را در میان تمامی مدلهای آزمایش شده ارائه دهد .
لینک کد در گیت هاب: https://github.com/SyydMR/PlateLicense/blob/master/Models/ModelTForcingAttention/Model.ipynb
نتایج نشان داد که مدلها قادر به تشخیص و خواندن پلاک خودروها با دقت بالایی هستند. عملکرد مدلها با استفاده از معیارهای مختلف ارزیابی شد و مدل نهایی که بهترین دقت و کارایی را داشت، انتخاب شد. مدل انتخاب شده توانست به خوبی پلاکهای خودرو را در شرایط مختلف تشخیص داده و بخواند، که نشان از موفقیت پروژه در رسیدن به اهدافش داشت.
نتیجه گیری
پروژه تشخیص و خواندن پلاک خودرو با استفاده از تکنیکهای پیشرفته هوش مصنوعی و یادگیری عمیق توانسته است به نتایج بسیار مطلوبی دست یابد. مدلهای مختلفی که در این پروژه مورد آزمایش قرار گرفتند، هر یک توانستند در شرایط مختلف عملکرد قابل قبولی داشته باشند. با این حال، مدل مبتنی بر Attention با استفاده از روش
Teacher Forcing بهترین نتایج را نشان داد و دقت و کارایی بالایی را در تشخیص و خواندن پلاکها ارائه کرد. این پروژه نشان داد که استفاده از تکنیکهای پیشرفته میتواند به طور قابل توجهی عملکرد سیستمهای نظارت و مدیریت ترافیک را بهبود بخشد و به کاهش تخلفات رانندگی کمک کند.