دسته بندی متون فارسی با استفاده از شبکه های عصبی ترنسفورمر پیش آموزش دیده

/*! elementor - v3.17.0 - 08-11-2023 */ .elementor-heading-title{padding:0;margin:0;line-height:1}.elementor-widget-heading .elementor-heading-title[class*=elementor-size-]>a{color:inherit;font-size:inherit;line-height:inherit}.elementor-widget-heading .elementor-heading-title.elementor-size-small{font-size:15px}.elementor-widget-heading .elementor-heading-title.elementor-size-medium{font-size:19px}.elementor-widget-heading .elementor-heading-title.elementor-size-large{font-size:29px}.elementor-widget-heading .elementor-heading-title.elementor-size-xl{font-size:39px}.elementor-widget-heading .elementor-heading-title.elementor-size-xxl{font-size:59px}
دسته بندی متون فارسی با استفاده از شبکه های عصبی ترنسفورمر پیش آموزش دیده
در این بلاگ پست که با هدف توضیح پروژه یادگیری عمیق است قصد به توضیح کامل مراحل دارم در این پروژه که از دیتاست ویکی پدیا که 14 کلاس را جمع آوری شده بود استفاده شده و مراحل کلی برای انجام آن به این صورت می باشد:1_پاکسازی داده ها و پیش پردازش های مربوط به متن _2_محاسبه و ارزیابی با استفاده از شبکه عصبی با لایه امبدینگ(Embedding)و شبکه عصبی بازگشتی(RNN)_3_استفاده از شبکه عصبی ترنسفورمر _4_مقایسه تمام نتیایج مانند recall و F_score آنها و رسم ماتریس آشفتگی(Confusion )است که البته علاوه بر شبکه عصبی پیش آموزش دیده bert فارسی که توسط دانشگاه اصفهان پیاده سازی شده است و یک مدل دیگر که البته من با استفاده از یک کتابخانه بهترین مقادیر را برای آن شبکه پیدا کردم که در ادامه به توصیف کامل هر بخش می پردازم و در آخر یک جمع بندی کلی انجام می دهم.1_ پیش پردازش و پاکسازی داده ها
برای این کار ابتدا من متن ها را خواندم و از هر دسته را بررسی کردم و به تنایج زیر رسیدم که موارد زیر باید از متن حذف شوند: 1_ حذف علائم نگارشی 2_ حذف تنوین ها و تشدید 3_حذف کلامات غیر فارسی (انگلیسی و فرانسوی و ژاپنی و ....) 4_ حذف دو عبارت که به شدت تکرار شده بودند عبارت "به انگلیسی"، "انگلیسی" و نام هر زبان دگیری که من این عبارت هم حذف کردم 5_ حذف خط تیره ها که در متن بود 6_حذف فاصله های اضافه 7_تبدیل نیم فاصله به فاصله 8_حذف اعداد 9_ این قستمت شامل حذف stopwords ها می شود که این را در یک فایل پایتونی جدا انجام دادم 10_حذف فایل های خالی بود که این مراحل را من با استفاده از regex استفاده کردم و برای حذف stopwordsها من از کتابخانه hazm استفاده کردم در ادامه من کدهای مربروط به قسمت پاکسازی مت را قرار می دهم . /*! elementor - v3.17.0 - 08-11-2023 */ .elementor-widget-image{text-align:center}.elementor-widget-image a{display:inline-block}.elementor-widget-image a img[src$=".svg"]{width:48px}.elementor-widget-image img{vertical-align:middle;display:inline-block}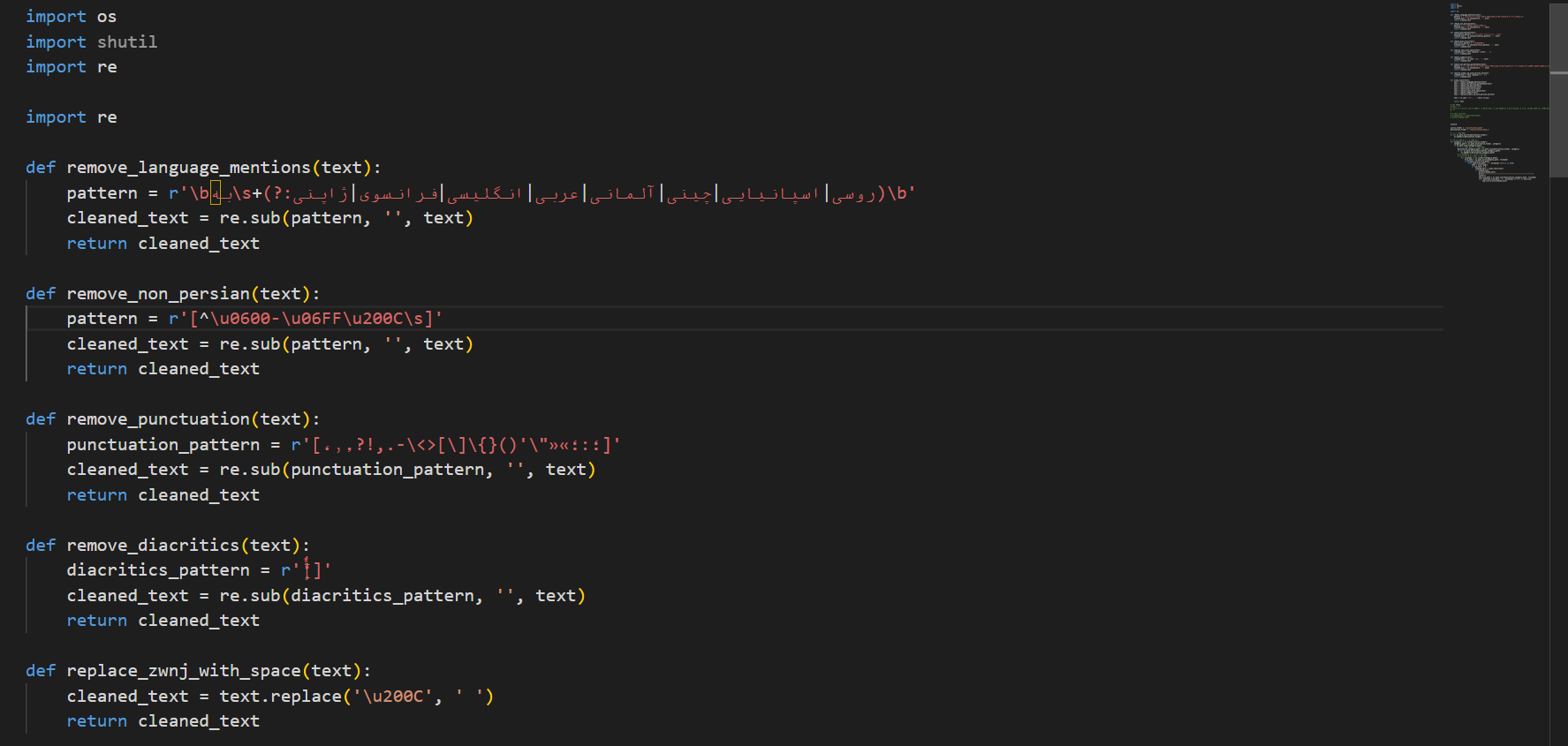 بخش دوم پاکسازی داده ها
بخش دوم پاکسازی داده ها
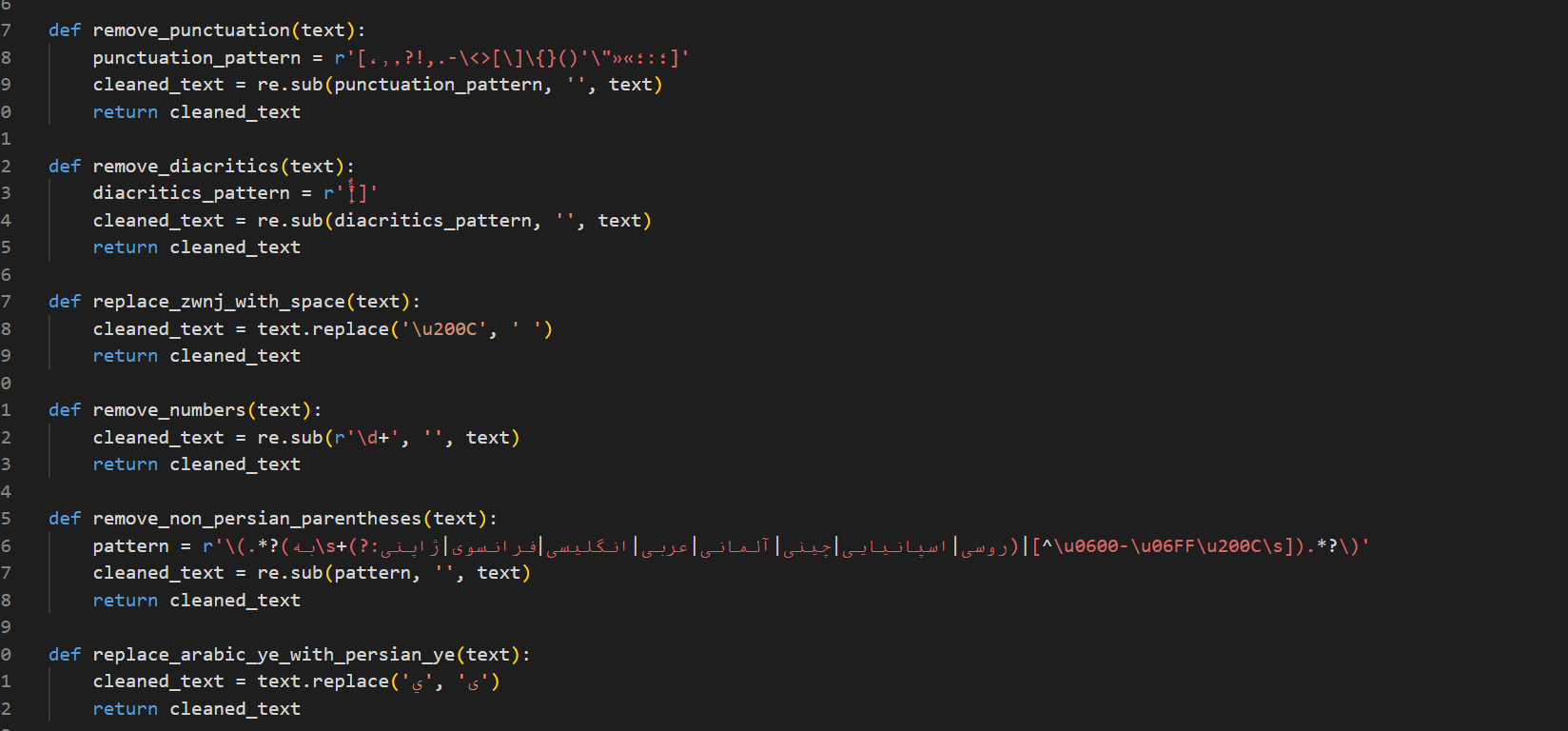 بخش آخر پایکسازی متن حذف فایل های خالی
بخش آخر پایکسازی متن حذف فایل های خالی
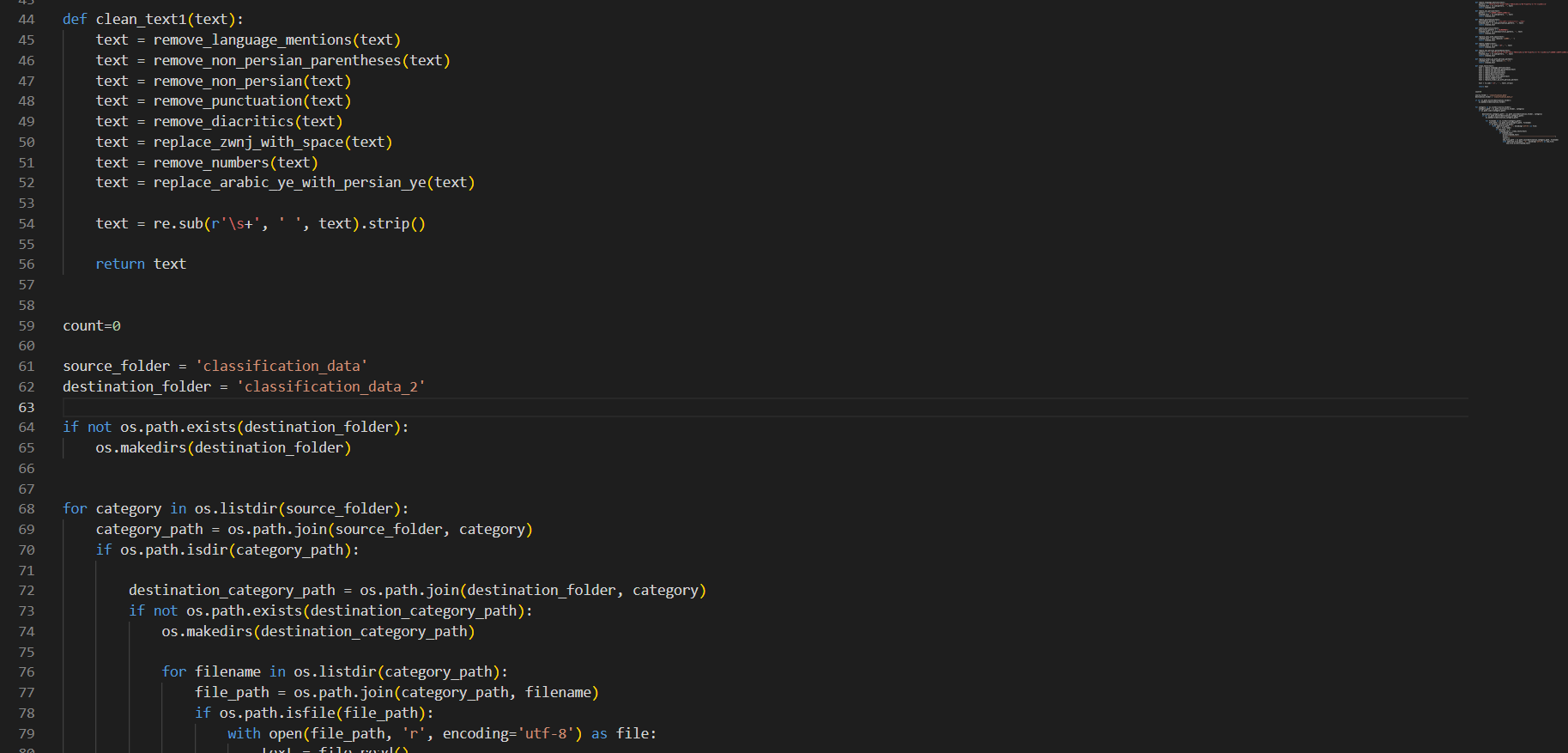

2_استفاده از مدل ها embedding و RNN
در ابتدا برای پروژه گفتم که بهتر است از مدل های که سر کلاس تدریس شده استفاده شده به همین خاطر به سراغ مدل های امبدینگ ساده و RNN ها رفتم در این روش ها با این که نسبت به ترنسفورمر در این دومدل من دچارoverfiting شدیدی بودم به قدری که که f1_score در داده های مخصوص آموزش به 99 درصد می رسید ولی در validation نهایت به 89 البته در امبدینگ در RNN توانستم اوضاع را یک مقدار بهتر کنم و f1_score به 92 به ولیدیش رسید که سعی کردم باز هم در RNN عمیق تر شوم و لایه ها LSTMو GRU استفاده کنم و لی متاسفانه رشد چندانی حاصل نشد ولی نتیجه هم بد نبود تقریبا و به خاطر نامتوازن بودن دیتا ها بیشتر چند متن نمونه که دادم به من گفت که مربوط به کلاس جغرافیا و مکان است: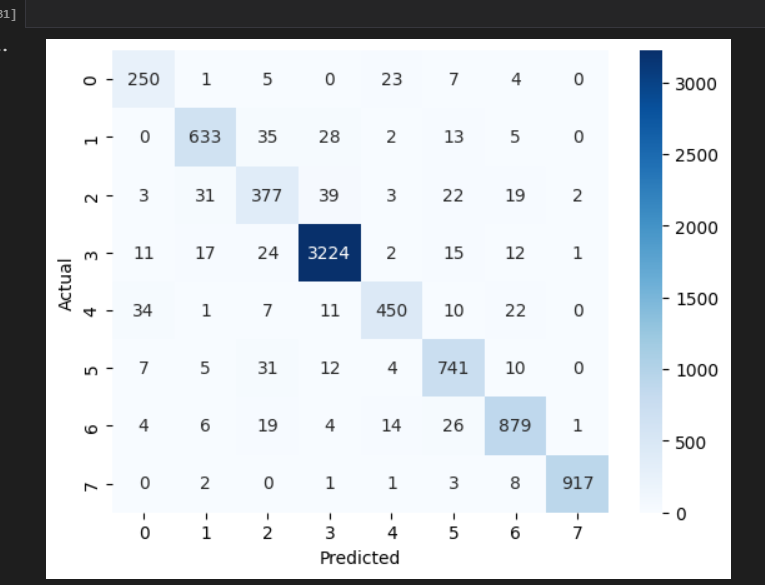
3_مقدمه ای بر ترنسفور مر ها
در ابتدا قبل از نحوه استفاده بنده از ترنسفورمر ها اجاز دهید توضیحات مختصری پیرامون این شبکه ها بدهم.شبکه های عصبی ترنسفورمر که امروز کاربرد گسترده ای پیدا کرده اند که از دو بخش اصلی تشکلیل شده است یک انکودر و یک دیکودر که برای طبقه بندی متن از encoder آن استفاده می شود که جهت استفاده در پروژه من از مدل آموزش دیده bert فارسی و شبکه عصبی ترسفورمرXLM-RoBERTaبهره برددو تغیراتی در ان ها دادم مانند اضافه کردن لایه ی dense و dropout و همچنین یک تابع نوشتم برای پیدا کردم بهترین مقادیر که به شرح زیر ابتدا در خصوص شبکه های ترسفورمر توضیح می دهم و بعد بخش های مهم کد و در آخر یک نتیجه گیری :شبکه عصبی XLM-RoBERTa
مدل XLM-RoBERTa: XLM-RoBERTa یک مدل زبانی مبتنی بر Transformer است که به طور خاص برای پردازش زبانهای مختلف طراحی شده است. این مدل از معماری RoBERTa استفاده میکند که خود بهبود یافتهای از BERT (Bidirectional Encoder Representations from Transformers) است. معماری BERT: BERT یک مدل مبتنی بر Transformer است که از معماری encoder-only استفاده میکند. این مدل شامل چندین لایه encoder است که هر کدام از لایهها شامل دو بخش اصلی است:- Multi-head Self-Attention Mechanism: این بخش به مدل اجازه میدهد که توجه بیشتری به بخشهای مختلف جمله داشته باشد و ارتباطات بین کلمات را به خوبی درک کند.
- Feed-forward Neural Network: این بخش شامل یک شبکه عصبی ساده است که بعد از لایه Self-Attention قرار میگیرد و به تقویت و پردازش اطلاعات کمک میکند.
توضیحات پیاده ساززی
ابتدا پس از بارگزاری داده ها و تقسیم آن ها ه به داده ها برای یادگیری و تست و validation باید آن ها را تبدیل به توکن کرد یه همین منظور من از یک شبکه پیش آموزش دیده استفاده کرده و ابتدا توکن ساز آن را بارگذاری می کنم و حداکثر طول توکن ها رابرابر 250 قرار می دهم . و سپس یک تابع توکن سازی که ورودی متن را می گیرد و متن به با طول حداکثر 250 کاراکتر برش داده و تبدیل به توکن می کند و pading هم داریم این بخش اولیه بخش بعد آموزش مدل است
- تعریف مدل سفارشی: کلاسی برای مدل
BertForSequenceClassificationWithDropoutایجاد شده که شامل و من یک (dropout) اضافی و لایه طبقهبندی (classifier) است. - بارگذاری مدل: یک نمونه از این مدل با استفاده از نام مدل و تعداد برچسبهای خروجی ساخته میشود.
- تنظیمات آموزش: پارامترهای مربوط به آموزش مدل مانند مسیر ذخیره نتایج، نرخ یادگیری، تعدادآپا کها و وزنزدایی تنظیم میشوند.
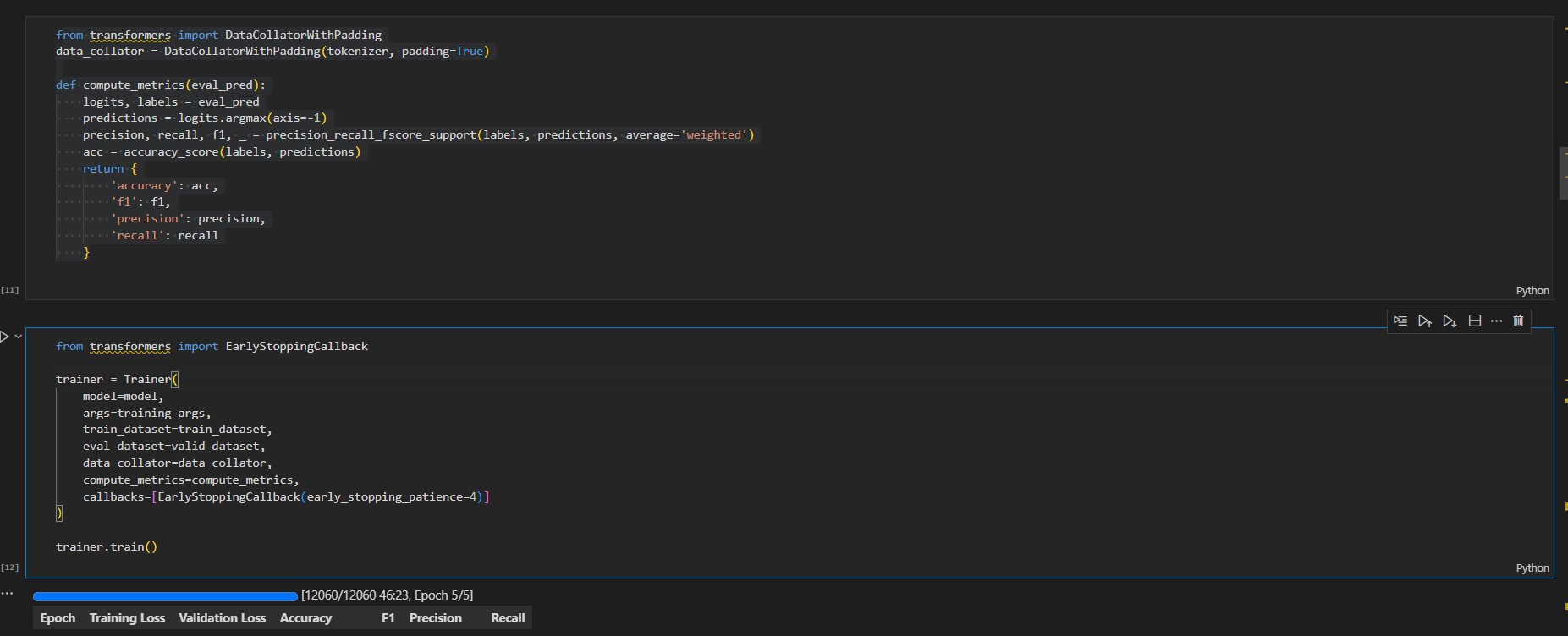
- تعریف (Trainer): مربی با استفاده از تنظیمات آموزش، دیتاستهای آموزشی و ارزیابی، و محاسبهگر متریکها (مانند دقت و f1) پیکربندی میشود.
- آغاز آموزش: آموزش مدل با استفاده از مربی (Trainer) آغاز میشود.
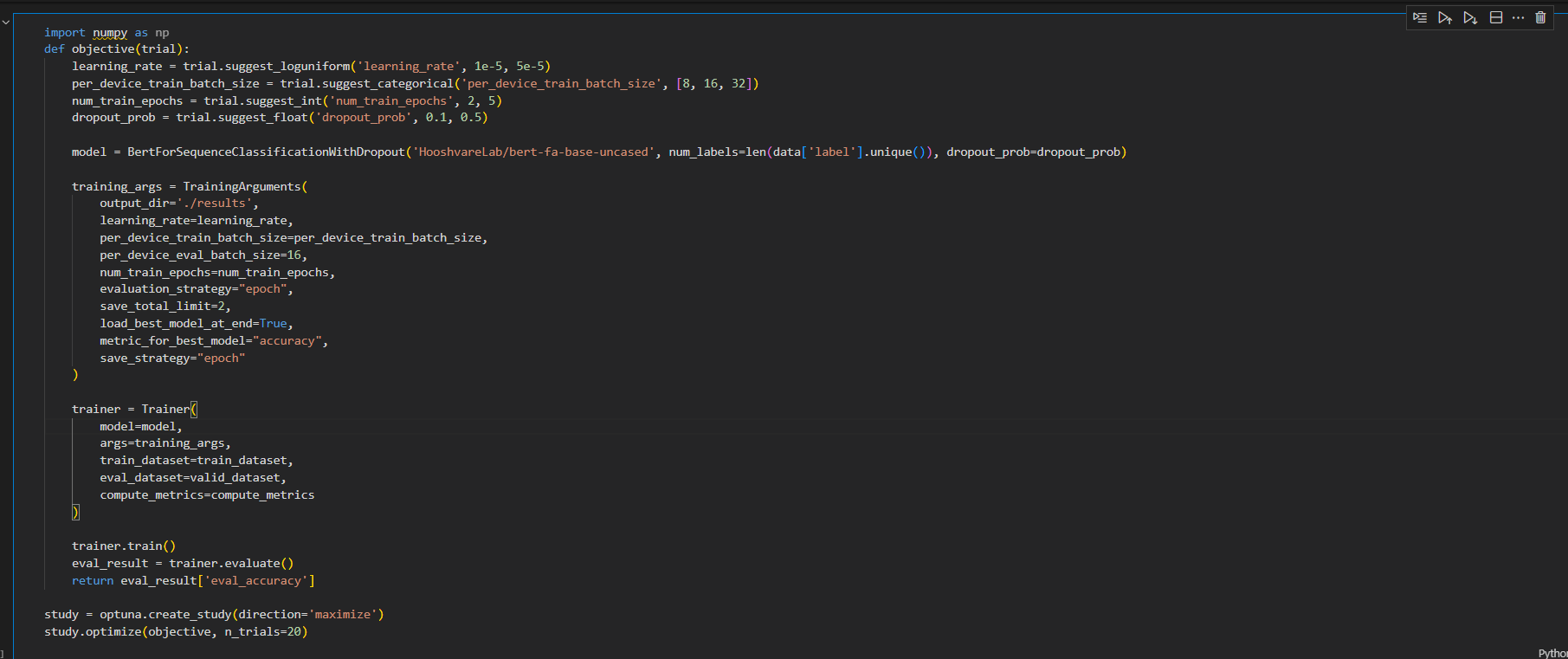
 برای پیدا کردن بهترین هایپرپارامتر ها می توان از کتابخانه OPtuna استفاده کردم و یک تابع هدف مانند تصویر زیر ایجاد کرد ویک نمونه از مدل را به آن داد و در آن بازه های مقادیر هایپرپارامتر را تعیین کرده و سپس این تابع این قدر این کار را ادامه بده تا بهترین حالت را برمی گرداند و لی این کار میتواند زمان بر باشد و 12 حالت را من بررسی کردم ولی در کل تعداد زیادی را بررسی می تواند کرد.
برای پیدا کردن بهترین هایپرپارامتر ها می توان از کتابخانه OPtuna استفاده کردم و یک تابع هدف مانند تصویر زیر ایجاد کرد ویک نمونه از مدل را به آن داد و در آن بازه های مقادیر هایپرپارامتر را تعیین کرده و سپس این تابع این قدر این کار را ادامه بده تا بهترین حالت را برمی گرداند و لی این کار میتواند زمان بر باشد و 12 حالت را من بررسی کردم ولی در کل تعداد زیادی را بررسی می تواند کرد.
4_نتیجه گیری
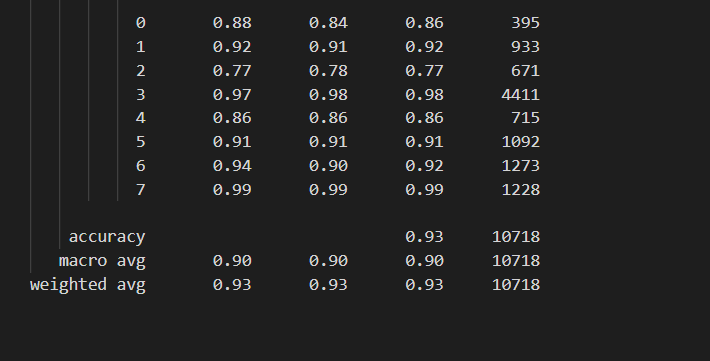
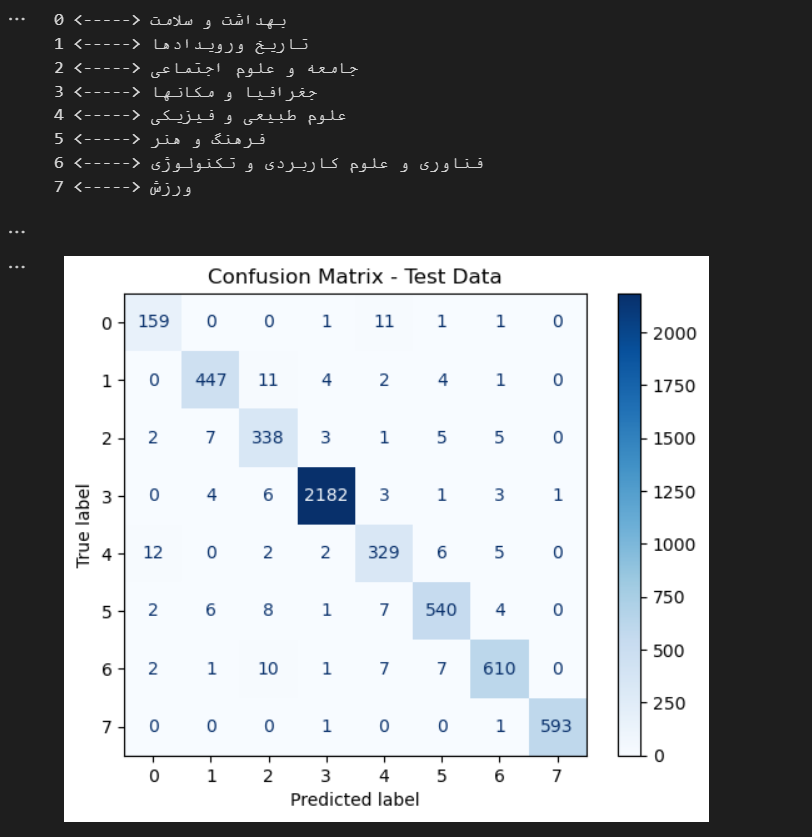
در آخر پس از استفاده از شبکه های پیش آموزش دیده bert توانستم که دقت را به 96 درصد در Validation برسانم و البته که overfit هم نداشتم تمام معیار های ارزیابی مانند f_score و recall و percesion به عدد 96 درصد رسد که البته باپیدا کردن مقادیر بهینه برای مدل که نحوه آن را در بخش 3_ شبکه های ترنسفور مر توضیح دادم به نزدیک 97 درصد هم در تست و validation رسیدم که البته باز هم جا برای بهبود دارد مانن پیاده سازی یک شبکه عصبی ترنسفور توسط خودم یا این که داده ها را افزایش بدهم کل داده های من برای ساخت شبکه 60000 متن بوده است که باید ان را فزایش داد که البته برای کارهای آینده است در آخر من نتایج تست وtrain و همچینین کد های بخش های تست کردن مدل که خوب کار می کند یا نه را برای شما قرار می دهم :
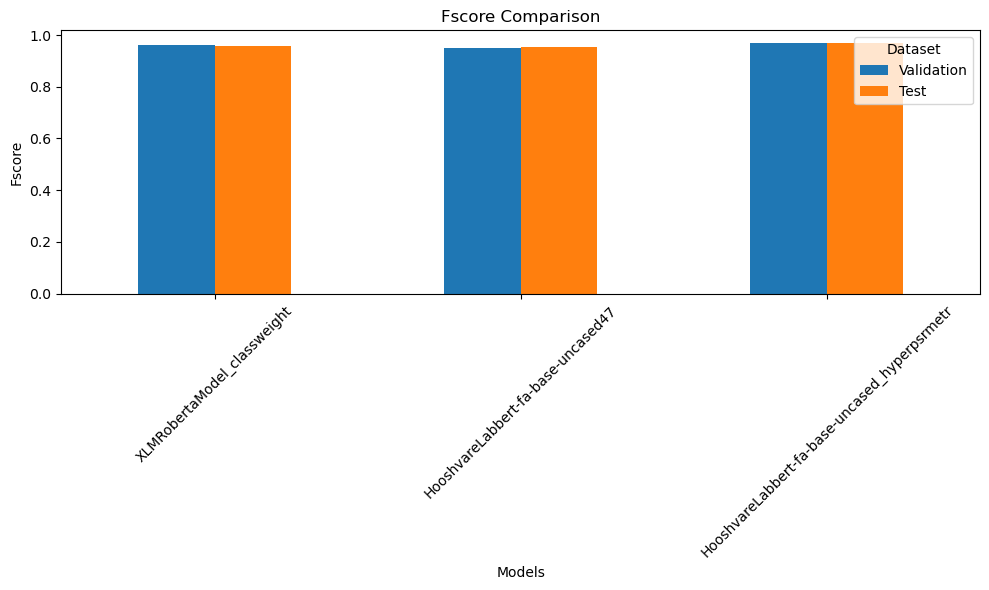
 در این جا می خواهم نمودار های مقایسه چند مدل ترسفور که ببینم آیا جای برای بهبود داشته است که با پیدا کردن مقادیر بهینه می توان مقادیر آن را بهبود بخشید را به شما نشان بدهم.
در این جا می خواهم نمودار های مقایسه چند مدل ترسفور که ببینم آیا جای برای بهبود داشته است که با پیدا کردن مقادیر بهینه می توان مقادیر آن را بهبود بخشید را به شما نشان بدهم.
تست مدل
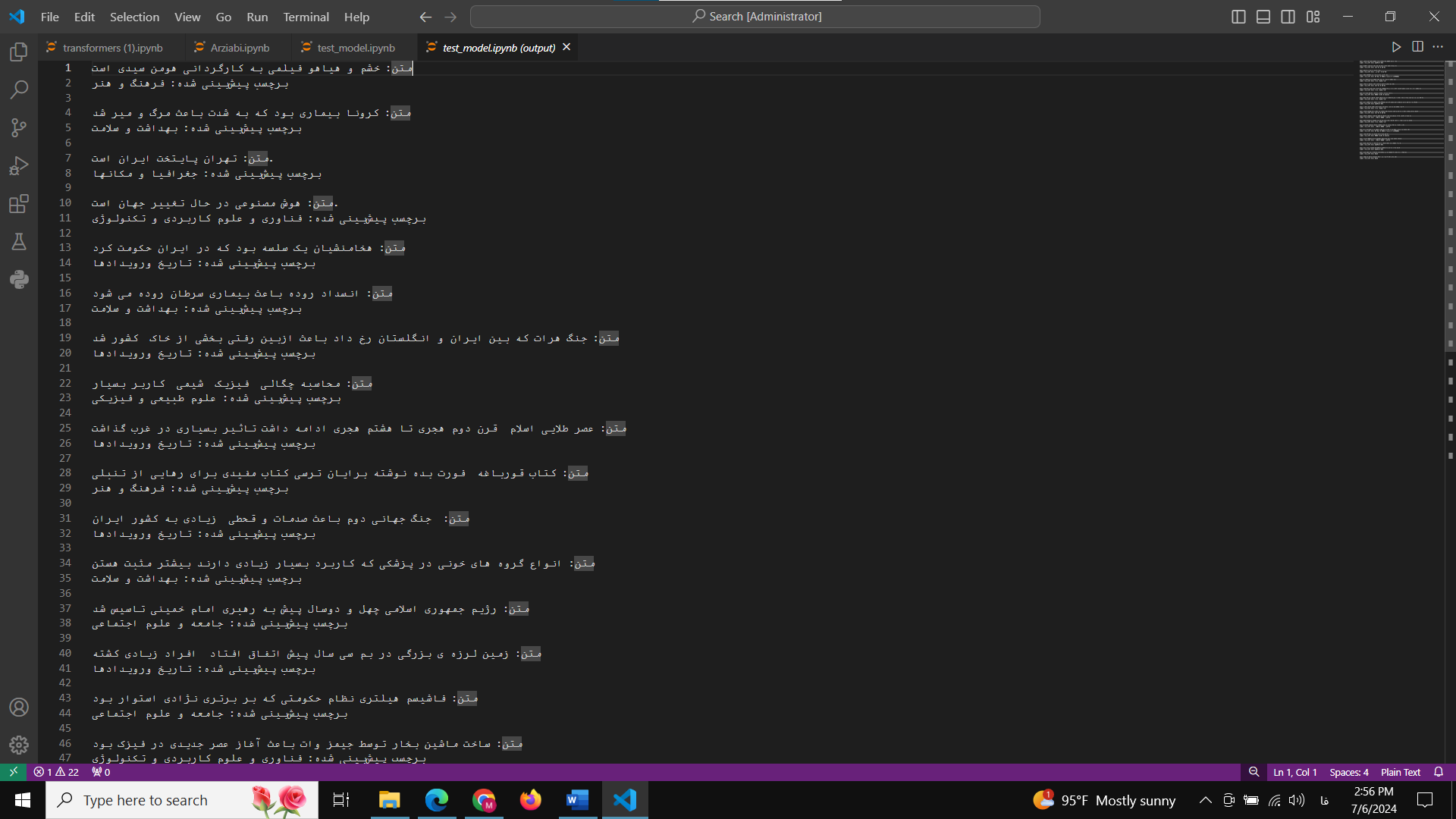
در قسمت هم نمونه متن های پیش بینی شده توسط مدل را خدمت شما ارائه می کنم تا از کارایی مدل مطمئن شوید.