• پروژه شناسایی موجودیتهای اسمی (NER) در زبان فارسی: تشخیص نام و نام خانوادگی

/*! elementor - v3.17.0 - 08-11-2023 */ .elementor-heading-title{padding:0;margin:0;line-height:1}.elementor-widget-heading .elementor-heading-title[class*=elementor-size-]>a{color:inherit;font-size:inherit;line-height:inherit}.elementor-widget-heading .elementor-heading-title.elementor-size-small{font-size:15px}.elementor-widget-heading .elementor-heading-title.elementor-size-medium{font-size:19px}.elementor-widget-heading .elementor-heading-title.elementor-size-large{font-size:29px}.elementor-widget-heading .elementor-heading-title.elementor-size-xl{font-size:39px}.elementor-widget-heading .elementor-heading-title.elementor-size-xxl{font-size:59px}
• پروژه شناسایی موجودیتهای اسمی (NER) در زبان فارسی: تشخیص نام و نام خانوادگی
مصطفی مدبری - محمدامین کیانفرد
در دنیای امروز، هوش مصنوعی و پردازش زبان طبیعی (NLP) نقش بسیار مهمی در تحلیل و استخراج اطلاعات از متون دارد. یکی از کاربردهای مهم NLP، شناسایی موجودیتهای نامگذاری شده (NER) است که به ما امکان میدهد اطلاعات کلیدی مانند نامها، مکانها، و سازمانها را از متون استخراج کنیم. برای بسیاری از کاربرد ها نظیر چت بات ها، نیازمند این هستیم که برخی از موجودیت ها مانند نام افراد از یک متن استخراج گردد. در این بلاگ پست، به بررسی پروژه NER در زبان فارسی میپردازیم که هدف آن تشخیص نام و نام خانوادگی افراد از متون فارسی است.
• هدف اصلی این پروژه چیست؟
هدف اصلی این پروژه، توسعه مدلی است که بتواند با دقت بالا، نام و نام خانوادگی افراد را از متون فارسی شناسایی کند. این مدل میتواند در کاربردهای مختلفی مانند تحلیل متون، جستجوی اطلاعات، و مدیریت دادهها مفید باشد. زبان فارسی دارای ساختار و ویژگیهای منحصر به فردی است که شناسایی موجودیتها را چالشبرانگیز میکند. تفاوتهای نوشتاری، استفاده از حروف مختلف برای یک صدا، و عدم وجود فاصلهگذاری مشخص بین کلمات میتواند شناسایی دقیق نامها را دشوار سازد. مانند دو جمله زیر:
- روحانی محل به مسجد وارد شد.
- روحانی، رییس جمهور پیشین ایران پس از پاسخ به سوالات خبرنگار جلسه را ترک کرد.
در جمله اول، روحانی اسم نیست اما در جمله دوم باید به عنوان موجودیت اسمی انتخاب شود. با توجه به این چالشها، توسعه یک مدل NER برای زبان فارسی اهمیت ویژهای دارد.
• مراحل کلی این پروژه به صورت زیر است:
۱. جمعآوری دادهها و یکپارچه سازی آنان
یکی از اولین و مهمترین مراحل در این پروژه، جمعآوری دادههای مناسب بود. ما نیاز به مجموعهای از متون فارسی داشتیم که حاوی نامها و نام خانوادگیهای مختلف باشند. این دادهها میتوانند از منابع مختلفی مانند اخبار، مقالات، و متون عمومی جمعآوری شوند، اما براساس پیشنهاد استاد راهنما(مهندس علیرضا اخوان پور) به سراغ جمع آوری دیتا از سایت های دانلود فیلم فارسی رفتیم و در کنار آن از دیتاست های آماده NER فارسی نظیر آرمان و پیما استفاده شد.
۲.توسعه مدل
با استفاده از دادههای برچسبگذاری شده، میتوان مدل NER را توسعه داد. مدلهای مختلفی مانند مدلهای مبتنی بر یادگیری عمیق (Deep Learning) و الگوریتمهای کلاسیک میتوانند مورد استفاده قرار گیرند. در این پروژه، از مدلهای یادگیری عمیق مانند Bidirectional LSTM (BiLSTM)استفاده کردیم.
۳.بهبود مدل
با توجه به نتایج ارزیابی، نیاز به بهبود و بهینهسازی مدل داشتیم. این بهبودها شامل افزایش تعداد دادههای آموزشی، تنظیم هایپرپارامترها، و استفاده از تکنیکهای پیشرفتهتر بود.
1. فاز اول، جمعآوری دادهها و یکپارچهسازی دادهها (Data Integration)
• تجمیع دادهها (Data Aggregation) :
دادهها از منابع مختلف (مثلاً چندین وبسایت) جمعآوری شده و در یک مکان متمرکز ذخیره شدند.
در مرحله اول، دادهها از وبسایتهای مختلف با استفاده از کتابخانه Beautiful Soup جمعآوری شدند. Beautiful Soup یک کتابخانه قدرتمند پایتون است که برای استخراج دادهها از فایلهای HTML و XML به کار میرود. این ابزار به ما اجازه میدهد تا به طور مؤثر و خودکار دادههای متنی را از صفحات وب استخراج کنیم. برای این کار، سایت های فیلیمو، نماوا، تلویبیون، آپتیوی، فیلمنت، فیلم2مووی و چندین سایت دیگر برای کرال انتخاب شدند. با این حال برخی از سایت ها نظیر تلویبیون این قابلیت را بسته بودند. معیار انتخاب داده ها، ایرانی بودن فیلم بود که در کد چک میشد. دیتای هدف نیز تگ های <p> خلاصه فیلم، خلاصه داستان و قسمت معرفی بازیگران بود. تمام دیتای جمع آوری شده در یک فایل txt قرار گرفت.
• پاکسازی دادهها (Data Cleaning):
دادههای تجمیع شده بررسی و پاکسازی میشوند تا خطاها، تناقضها، و دادههای تکراری حذف شوند. اطمینان حاصل میشود که دادهها به صورت هماهنگ و بدون نویز هستند.
دادههای جمعآوریشده مورد پیشپردازش قرار گرفتند. این مرحله شامل چندین فرایند کلیدی بود:
- پاکسازی دادهها: علائم نگارشی و حروف انگلیسی از متن حذف شدند. این کار به منظور حذف نویز و تمرکز بر روی محتوای اصلی فارسی انجام شد.
- حذف حروف اضافی: حروف و کلمات اضافی در زبان فارسی، که ممکن است تاثیری در شناسایی موجودیتها نداشته باشند، از متن حذف شدند تا دادهها به صورت پاک و تمیز آماده شوند.
- حذف فاصله های اضافی: دلیمتر های اضافی مانند اسپیس ها و تب های اضافی باید حذف میشدند و نیازی به کاراکتر نیولاین نبود.
این مرحله به بهبود کیفیت دادهها و افزایش دقت مدل در مراحل بعدی کمک شایانی کرد.
• تبدیل دادهها (Data Transformation) :
دادهها به فرمتها و ساختارهای استاندارد تبدیل میشوند تا قابلیت یکپارچهسازی داشته باشند.این شامل نرمالیزه کردن دادهها و تبدیل واحدها و قالبها به یکدیگر است.
- تقسیمبندی جملات: دادهها به جملات جداگانه در فایل txt تا برای مراحل بعدی پردازش آماده شوند.
- تقسیمبندی کلمات و توکنایز داده ها: کلمات هر جمله در یک خط قرار گرفتند تا لیبل به صورت 0 و 1 جلوی آن قرار بگیرد.
حاصل این مرحله 2144 جمله بدون لیبل بود.
/*! elementor - v3.17.0 - 08-11-2023 */ .elementor-widget-image{text-align:center}.elementor-widget-image a{display:inline-block}.elementor-widget-image a img[src$=".svg"]{width:48px}.elementor-widget-image img{vertical-align:middle;display:inline-block}
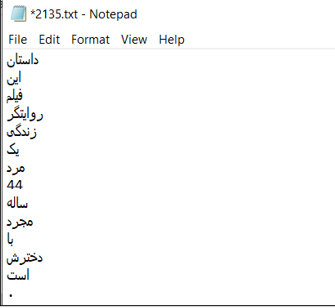
از طرفی از دو دیتاست آماده پیما (Peyma) و آرمان(Arman) استفاده شد. این دیتاست ها از پیش لیبل خورده بودند، منتها این دیتا نیز نیازمند تغییراتی شامل پاکسازی دادهها (Data Cleaning) و تبدیل دادهها (Data Transformation) بود، حاصل این مرحله 18269 فایل txt (هر فایل شامل یک جمله که با نقطه تمام میشد) بود.
نمونه ای از آن در زیر آمده است:
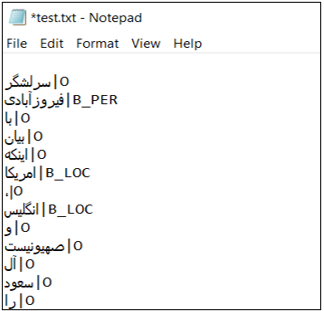
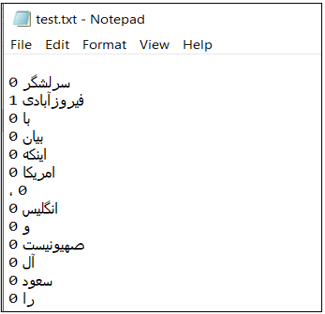
• یکپارچهسازی نهایی (Final Integration):
دادههای پاکسازی و تبدیلشده با هم ترکیب میشوند تا یک مجموعه دادهی یکپارچه و منسجم به دست آید.
در نهایت تمامی دیتای جمع آوری شده از وب (شامل 2144 جمله) در یک دایرکتوری با نام Unlabeled قرار گرفت و دیتاست های arman و peyma نیز (شامل 18269 جمله)در دایرکتوری Labeled قرار گرفتند.
۲. فاز دوم، توسعه مدل:
مرحله اول: (ایده اول)
- تمام کلمات جمعآوریشده در یک آرایه و لیبلها در یک آرایه دیگر ذخیره شد سپس داده به بخشهای کوچکتر (batch) تقسیم و شافل شد.
در این روش از آنجایی که کلمات در قالب جمله به مدل داده نشدهبود مدل به مفهوم جملات حساس نبود.
مرحله دوم: (تغییر روش خواندن دادهها)
- دادهها از فایلهای متنی خواندهشد و جملات در قالب نوع داده string در یک آرایه ذخیره شدند. لیبلها نیز در قالب نوع داده int در یک آرایه دوبعدی ذخیره شد.
- سپس ۲۰ درصد دادهها برای validation جدا شدند.
- تابع وکتورایز به صورت زیر تعریف شد که حداکثر طول جملات ۵۰ توکن تعریف شد. و اندازه lookup table نیز ۱۰۰۰۰ کلمه تعریف شد. سپس بر روی دادهها adapt شد و دادهها وکتورایز شدند.
- به لیبلها در صورت نیاز پدینگ اضافه شد تا همطول متنها شوند از padding = ‘post’ استفاده شد که به انتهای آنها پدینگ اضافه کند
- دادهها ما به فرمت tf.dataتبدیل شد.
- دادهها به بخشهای کوچکتر (batch) تقسیم، شافل و برای افزایش سرعت prefetchشد.
- تعریف مدل:
- ورودی مدل یک بردار با طول50 و نوع داده ورودی را عدد صحیح 32 بیتی است.
- لایه امبدینگ با ورودی ۱۰۰۰۰ توکن (به اندازه lookup table) و embedding_dim = 128، حداکثر طول جمله نیز ۵۰ توکن میباشد
- لایه Dropout که به طور تصادفی 10% از واحدهای ورودی را در هر بهروزرسانی در زمان آموزش غیرفعال میکند تا از اورفیت جلوگیری کند.
- LSTM دوطرفه (به این معنی که اطلاعات از هر دو جهت توالی ورودی را بگیرد) با 64 واحد و که return_sequences=Trueبرای هر ورودی یک توالی خروجی بدهد، نه فقط برای آخرین ورودی.
- لایه ،TimeDistributed این لایه را به صورت توزیعشده در زمان اعمال میکند، به این معنی که لایه متراکم برای هر گام زمانی در توالی ورودی به طور جداگانه اعمال میشود. این کار به مدل اجازه میدهد تا برای هر کلمه در توالی ورودی، پیشبینی جداگانه انجام دهد.

- مدل با optimizer آدام و loss = sparse_categorical_crossentropy کامپایل شد.
- در نهایت با ۱۰ ایپاک مدل فیت شد.
۳. فاز سوم، بهبود مدل
مرحله اول: (اضافه کردن کالبکها)
توقف زودهنگام (Early Stopping) که در صورت عدم بهبود در val_loss پس از ۴ ایپاک متوقف میشود و بهترین وزنهای مدل را از ایپاکهایی که بهترین عملکرد را داشتهاند بازیابی میکند.
مرحله دوم: (تغییر تابع فعالساز لایه آخر)
با توجه به دو کلاسه بودن تسک تابع به sigmoid و loss به binary_croossentropy تغییر داده شد که در تستهای گرفتهشده بهبود حاصل نشد و به حالت قبل بازگشتیم.
مرحله سوم: (تغییرات جزئی در ساختار مدل)
تغییر batch_size از ۱۲۸ به ۶۴
افزایش تعداد ایپاک از ۱۰ به ۱۲
و دیپ کردن LTSM به اندازه ۲

این دو لایه LSTM دوطرفه به مدل اضافه شدهاند تا توانایی مدل در یادگیری روابط پیچیدهتر و طولانیمدت در توالیهای ورودی را افزایش دهند. هر لایه LSTM دوطرفه میتواند اطلاعات را از هر دو جهت توالی یاد بگیرد و به مدل کمک میکند تا ساختارهای زمانی پیچیدهتر را در دادهها درک کند.
در نهایت به این اعداد برای دقت و خطا رسیدیم:
loss: 0.0066
accuracy: 0.9972
val_loss: 0.0367
val_accuracy: 0.9913
که نشاندهنده عدم وجود اورفیت است اما یک نکته مهم این است با توجه به imbalance بودن دیتا این اعداد توضیح مناسبی به ما در مورد وضعیت نمیدهد و بهتر بود از دقت (Precision)، بازخوانی (Recall)، و امتیاز F1 استفاده میکردیم تا مطمئن میشدیم مدل به خوبی عمل میکند و در صورت نیاز از روشهای برخورد با دیتای نامتوازن استفاده کنیم (مانند class weight یا focal loss) که در ورژنهای بعدی پروژه این موضوع اصلاح خواهد شد.
استفاده از مدل:
مرحله اول: (ذخیره مدل)
مدل نهایی به همراه کانفیگ و وزنهای لایه وکتورایز ذخیره شدند.
مرحله دوم: (ساخت اینترفیس)
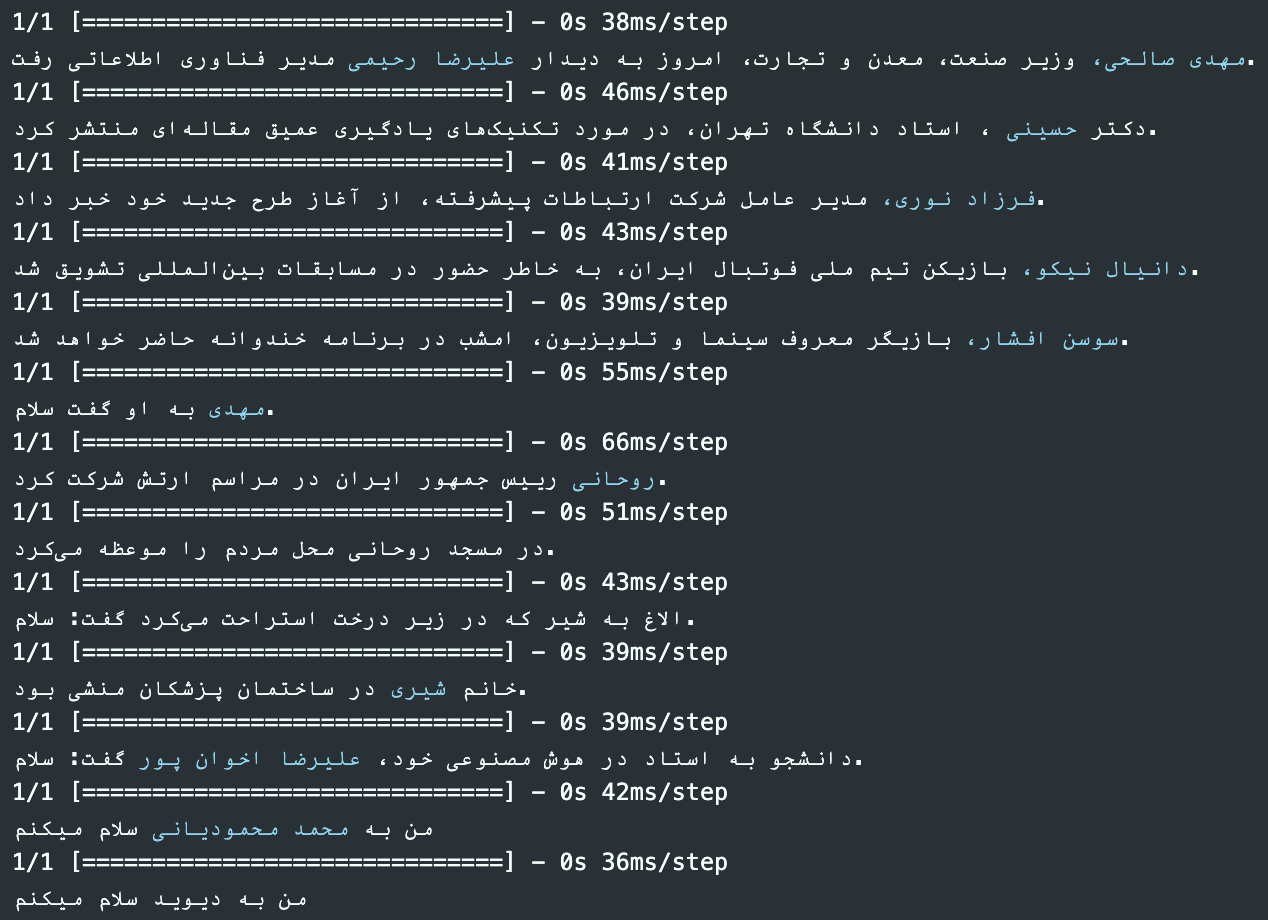
مدل به همراه کانفیگ و وزنهای لایه وکتورایز لود شد و یک تابع برای پیشآمادهسازی و استفاده از مدل برای پیشبینی اسامی موجود در متن ورودی نوشته شد که ورودی آن یک آرایه از استرینگها است و خروجی هر جمله به همراه لیبلهای آن است همچنین یک تابع برای چاپ اسامی به صورت رنگی در جملات نوشته شد که ورودی آن خروجی تابع قبلی است.
مثال از خروجی مدل: