ترجمه ماشینی یکی از مسائل مهم در پردازش زبان طبیعی است. در این گزارش ما با استفاده از مدل Transformers دقت را به 49 bleu score رساندیم و میتواند دنباله های طولانی تری را ترجمه کند. علاوه بر دقت مدل Transformer قابلیت موازی سازی بیشتری نسبت مدل های Sequential دارد..
مقدمه
ترجمه ماشینی را میتوان به صورت یک مسئله Sequential دید و با استفاده از مدل های Sequence-to-sequence این مسئله را حل کرد. مدل های Sequence-to-sequence دنباله ای را به عنوان ورودی دریافت میکند و در خروجی دنباله مورد نظر انتظار میرود. مدل بسیار ساده که میتواند این مسئله را حل کند از دو بخش Encoder و Decoder تشکیل شده است. بخش Encoder با دیدن ورودی یک بردار خروجی میدهد که تمام ورودی را در خود رمزگذاری کرده است و کار بخش Decoder این است که خروجی Encoder را خوانده و دنباله مورد نظر را تولید کند.
برای اینکه مدل ورودی را به عنوان دنباله ببیند از واحدهایی به نام LSTM استفاده میکنیم که از gate استفاده میکند تا context را در دنباله طولانی مدت حفظ کند.


RNN with Attention (Our Model)
ما این مدل را با Embedding Dimention = 128 و BiRNN Units = 128 برای رفت و برگشت برای Encoder و Decoder Units = 128 ساختیم. در Encoder و Decoder از واحد GRU استفاده کردیم.
در واحد Attention از Attention Units = 10 استفاده کردیم.
نمودار دقت بر هر ایپاک
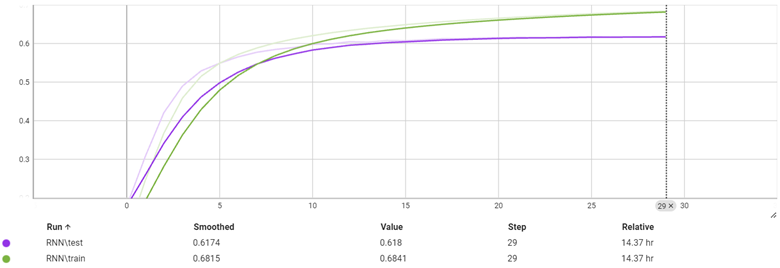
با ترین بر روی 1 میلیون داده که 20% آن برای تست استفاده شد در 29 ایپاک به دقت بالای 61 درصد در زمان تست رسید. مدت زمان ترین حدود 14 ساعت طول کشید و از ایپاک 15 به بعد نمودار تقریبا تغییر زیادی را نشان نداد.
نمودار Loss برحسب هر ایپاک
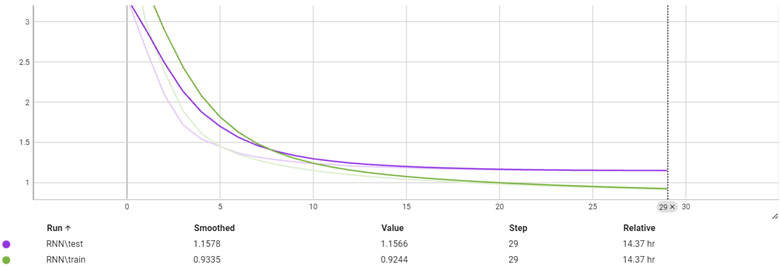
با توجه به نمودار بالا میتوان دید که مشکل overfit تقریبا وجود ندارد. این میتواند به این معنا باشد که اگر مدل سنگین تر با RNN Units بیشتر داشته باشیم دقت بهتری میتوانیم بگیریم. اما با تجربه ای که در ترین این مدل داشتیم، چون موازی سازی در مدل های Sequential اتفاق نمی افتد سرعت ترین به شدت پایین می آید.
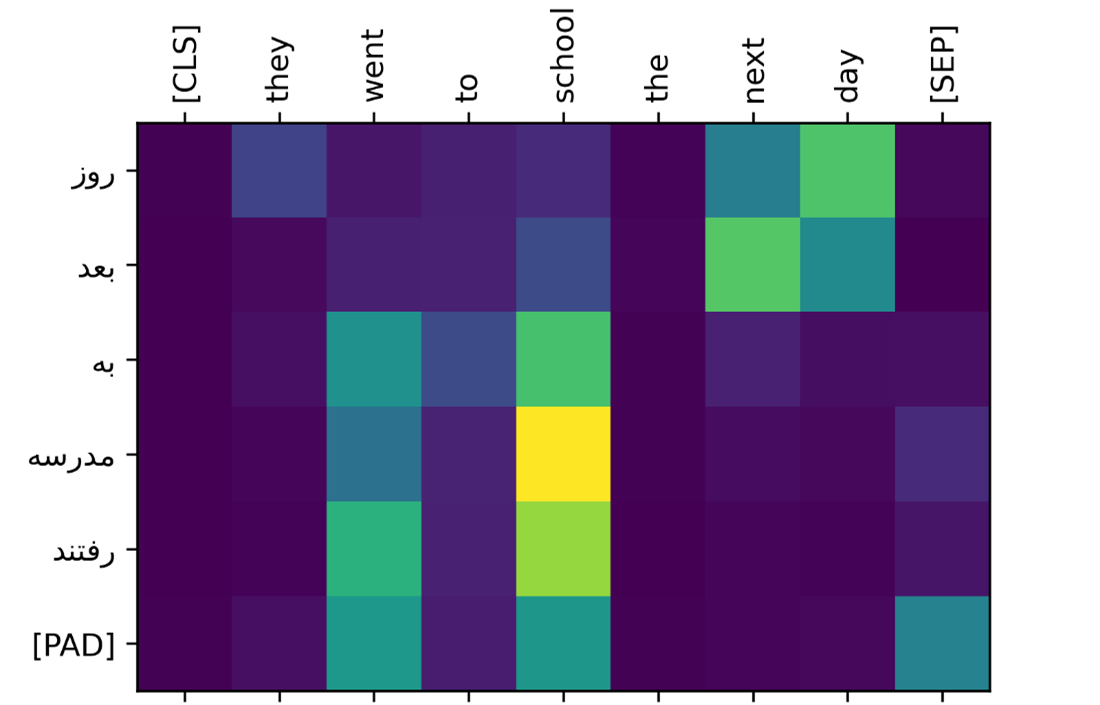
در مثال “
The bank is by the river bank” میتوان به خوبی مشاهده کرد که مدل در هر لحظه به کدام خروجی Encoder توجه داشته است. با توجه به اینکه
bank دوم با
river اماده است معنای آن
ساحل برای رودخانه است که مدل هنگام خروجی دادن
ساحل همزمان به
river و
bank توجه کرده و خروجی درستی نشان داده است. (شکل زیر نشان دهنده attention scores است)

مثال دیگری از توجه:
Evaluation of RNN with attention
ما یک مجموعه برای تست مدل هایمان استفاده کردیم. در این مجموعه سعی کردیم از انواع مختلفی از متن های انگلیسی که چالشی هستند استفاده کنیم.
- متن با زمان های متفاوت
- متن با نقل از فرد دیگر
- متن دارای relative clause
- متن دارای سوال
- متن شامل اصطلاح
- متن دارای عدد و ...
بر روی این مجموعه مدل RNN ما دارای BLEU SCORE: 22 است.
| BLEU Score |
Interpretation |
| 20 - 29 |
The gist is clear, but has significant grammatical errors |
| 30 - 40 |
Understandable to good translations |
| 40 - 50 |
High quality translations |
| 50 - 60 |
Very high quality, adequate, and fluent translations |
یکی از مشکلات اساسی مدل ناتوان بودن در ترجمه اصطلاحات است
.
مشکلات دیگر زمان هایی دیده میشود که عدد در ترجمه استفاده شده و یا متن طولانی تر از معمول شده.
|
Source |
# |
| . 38 تا « 100 دلاره 100 دلار خرید |
She bought three apples for $1.50 each. |
1 |
| خوشحال بودند ، اگرچه پول داشتند. |
They were happy, although they had little money. |
2 |
| چون سرد بود و کت دستکش و پوشید. |
Because it was cold, she wore a coat and gloves. |
3 |
| پروژه که قبلا رفت ، تقریبا کامل است. |
The project, which was started last year, is almost complete. |
4 |
| زودتر از باران شروع کرد |
No sooner had she left than it started raining. |
5 |
| می دونی دریا ؟ |
Can you see the sea? |
6 |
| یک پا را بردارید! |
Break a leg! |
7 |
| باران ها و سگ ها می شکند. |
It's raining cats and dogs. |
8 |
| خورشید می درخشید و پرندگان آواز می خواندند ، روز برای روز کامل ساخته بودند. |
The sun was shining, and the birds were singing, which made for a perfect day. |
9 |
| مثل فیلم خیلی دوست نداشت ، اما او از موسیقی لذت برد. |
She didn't like the movie because it was too long, but she enjoyed the music. |
10 |
جدول بالا بخشی از مجموعه است که نشان میدهد مدل RNN نتوانسته به خوبی عمل کند و تقریبا همه آنها را به اشتباه یا با دقت کم ترجمه کرده.
ما حدس میزنیم اگه مدل پیچیده تر داشتیم دقت مدل بسیار بهتر میشد و این موضوع در نمودار های بالا واضح است. اما مشکل موازی سازی مدل های RNN هنوز حل نشده که در مدل Transformer آن را حل میکنیم.
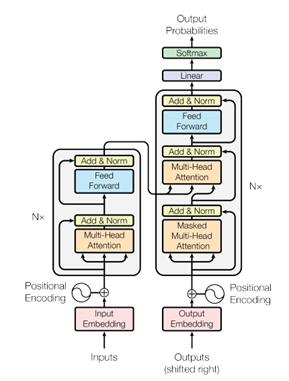
Transformers
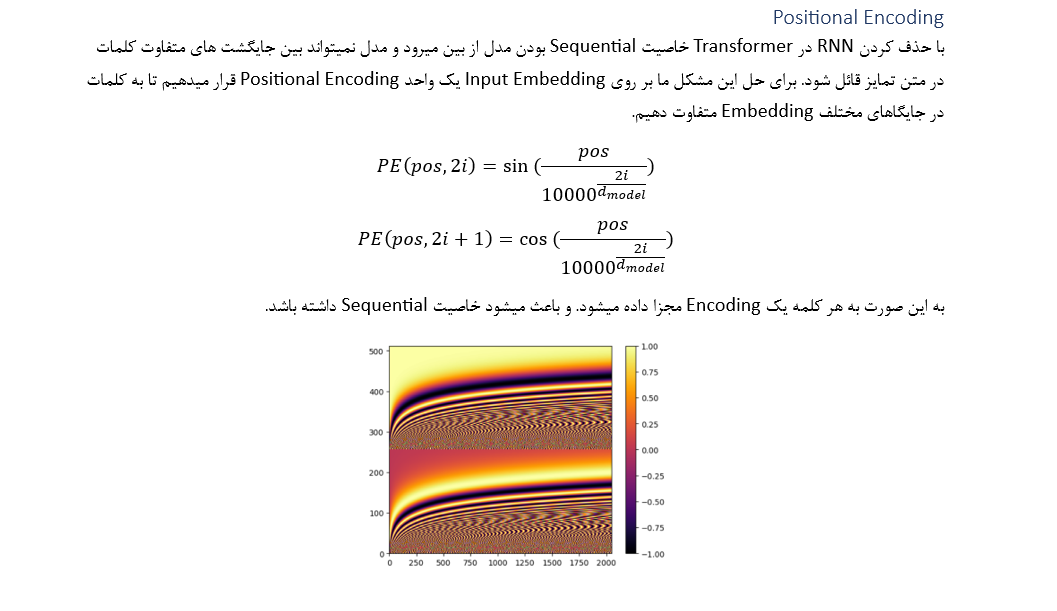
این مدل مشکل موازی سازی مدل قبلی را برطرف میکند. در این مدل هدف این است که تمامی محاسبات را به صورت موازی محاسبه کنیم. مشکل Sequential نبودن این محاسبات را با Positional Encoding حل میکنیم.
Attention
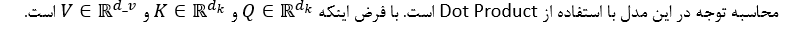
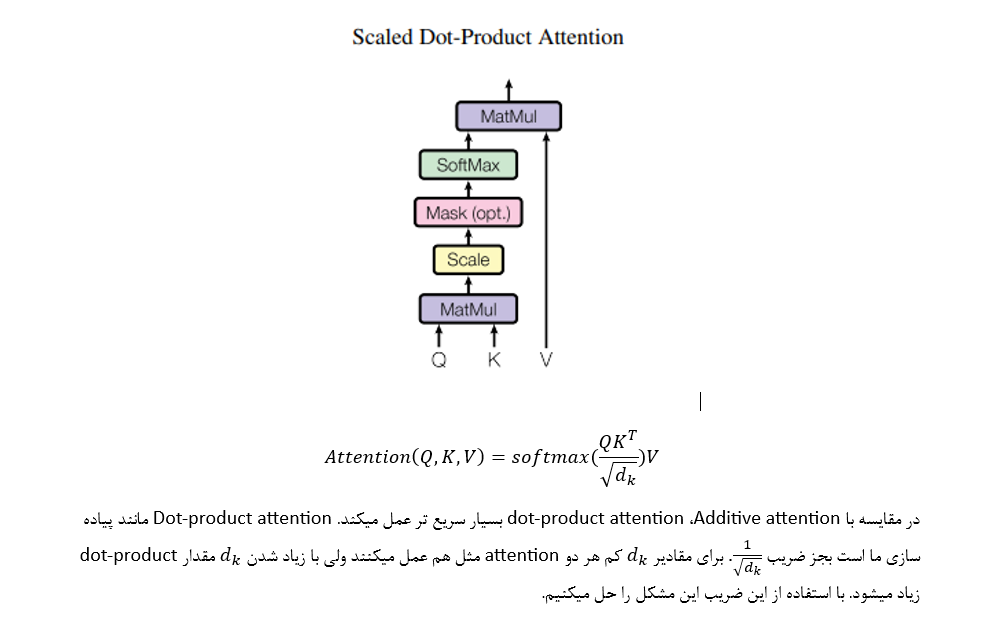
Multihead-Attention
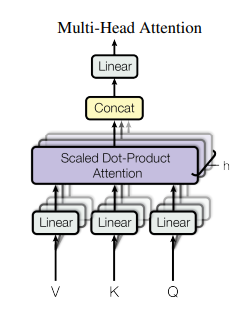

Masked Multihead attention
در هنگام خروجی دادن Decoder مانند Encoder ابتدا یک لایه self attention دارد. اما مشکل اینجا بوجود می آید که ما نباید در هر timestep به زمان های جلوتر توجه کنیم. برای همین یک Mask برای صفر کردن توجه به زمان های آینده استفاده میکنیم.
Cross Multihead Attention
علاوه بر توجه به خود در Decoder ما نیاز داریم به خروجی Encoder توجه کنیم (مانند Attention در قسمت RNN with Attention). به همین دلیل خروجی لایه قبلی Decoder را به Q در Cross Multihead Attention میدهیم و خروجی های Encoder را به K, V همین لایه میدهیم تا Similarity بین این دو پیدا کند.
شکل بالا مقادیر برای کلمه در یک جمله را نشان میدهد. اگر دقت کنید هیچ خط عمودی نمیتوانید بکشید که مقادیر یکسان داشته باشد.
Transformer 16M
مدل سبک Transformer ما به صورت زیر تعریف میشود
- N=4
- d_model=128
- h=8
- dff=512
- dropout rate=0.1
در تمامی لایه ها dropout_rate برابر 0.1 برای مقابله با overfit استفاده میشود. این مدل دارای 16M پارامتر است.
Warmup scheduler
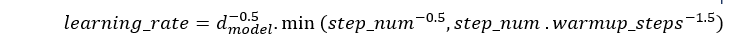
- در ابتدای یادگیری برای جلوگیری کردن از نوسان در آینده و بروزرسانی های بزرگ در ابتدای یادگیری از این scheduler استفاده میکنیم. این به یادگیری stable تر مدل کمک میکند.
- با افزایش learning_rate مدل سریع تر converge میشود.
- با کاهش learning_rate بعد از مرحله warmup باعث finetune شدن مدل میشود.
در این پروژه برابر 15% کل step های زمان train است.
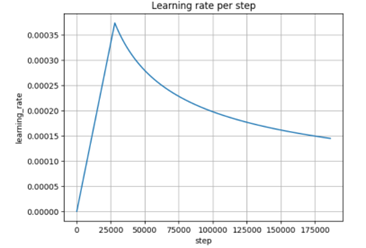
نمودار بالا نمودار
learning_rate در هر
step است.
Train
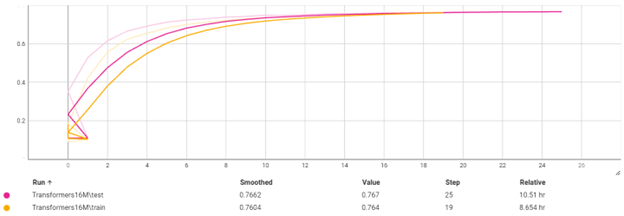
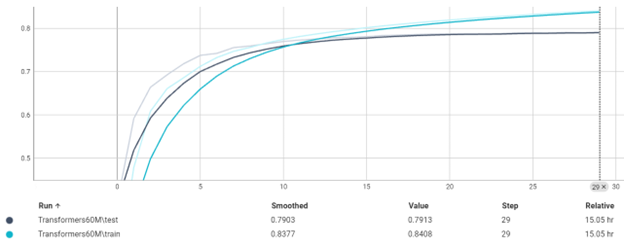
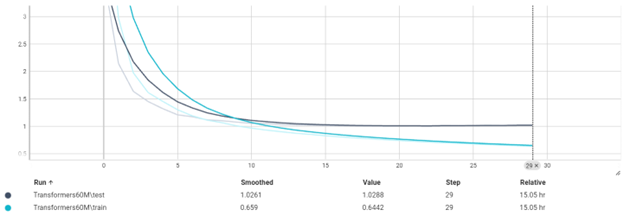
این مدل تا ایپاک 25 به دقت 76% بر روی تست رسیده که دقت خوبی است. زمان مورد نیاز برای train بر روی 1 میلیون داده که 20% آن برای تست استفاده شده است حدود 11 ساعت است. این نشان دهنده خاصیت موازی سازی در Transformers است.
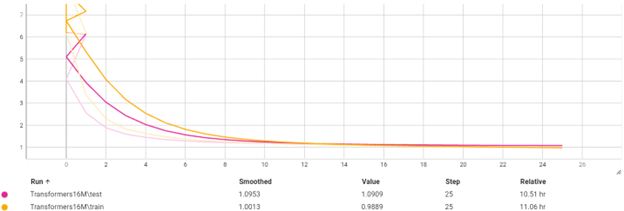
این مدل نشان میدهد که مشکل
overfit به هیچ وجه وجود ندارد و با پیچیده تر کردن مدل میتوانیم به دقت بهتری برسیم. دقت کنید که 10 ایپاک لازم بوده تا مدل
converge شود.
Evaluation Transformer 16M
ما یک مجموعه برای تست مدل هایمان استفاده کردیم. در این مجموعه سعی کردیم از انواع مختلفی از متن های انگلیسی که چالشی هستند استفاده کنیم.
- متن با زمان های متفاوت
- متن با نقل از فرد دیگر
- متن دارای relative clause
- متن دارای سوال
- متن شامل اصطلاح
- متن دارای عدد و ...
بر روی این مجموعه مدل Transformer 16M ما دارای BLEU SCORE: 45 است.
| BLEU Score |
Interpretation |
| 20 - 29 |
The gist is clear, but has significant grammatical errors |
| 30 - 40 |
Understandable to good translations |
| 40 - 50 |
High quality translations |
| 50 - 60 |
Very high quality, adequate, and fluent translations |
| Target |
Source |
# |
| او سه سیب برای 1.50 دلار خرید. |
She bought three apples for $1.50 each. |
1 |
| آن ها خوشحال بودند ، اگرچه پول کمی داشتند. |
They were happy, although they had little money. |
2 |
| چون سرد بود کت و دستکش پوشیده بود. |
Because it was cold, she wore a coat and gloves. |
3 |
| پروژه ای که سال گذشته شروع شد تقریبا کامل است. |
The project, which was started last year, is almost complete. |
4 |
| به محض اینکه او رفت از باران شروع به رفتن کرد. |
No sooner had she left than it started raining. |
5 |
| دریا را می بینی ؟ |
Can you see the sea? |
6 |
| یک پا بشکنید! |
Break a leg! |
7 |
| باران گربه ها و سگ ها می بارد. |
It's raining cats and dogs. |
8 |
| خورشید می درخشید و پرندگان آواز می خواندند که برای یک روز کامل ساخته می شدند. |
The sun was shining, and the birds were singing, which made for a perfect day. |
9 |
| او فیلم را دوست نداشت زیرا خیلی طولانی بود ، اما از موسیقی لذت می برد. |
She didn't like the movie because it was too long, but she enjoyed the music. |
10 |
یکی از مشکلات اساسی مدل ناتوان بودن در ترجمه اصطلاحات است
.
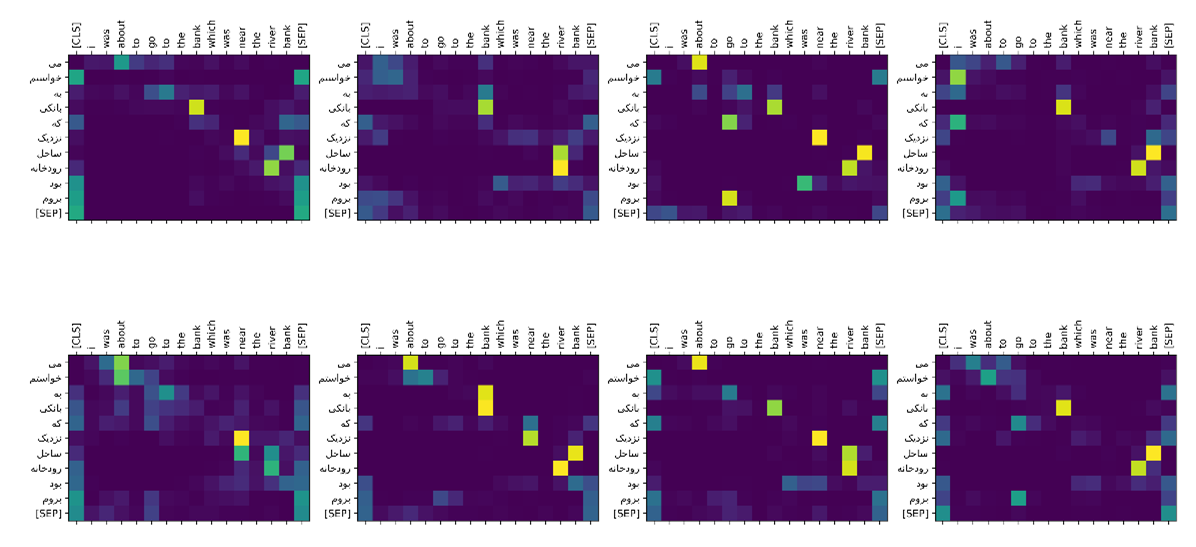
شکل بالا نشان دهنده توجه Decoder به خروجی Encoder است. میتوانید ببینید که به ازای هر head توجه متفاوتی یاد میگیرد.
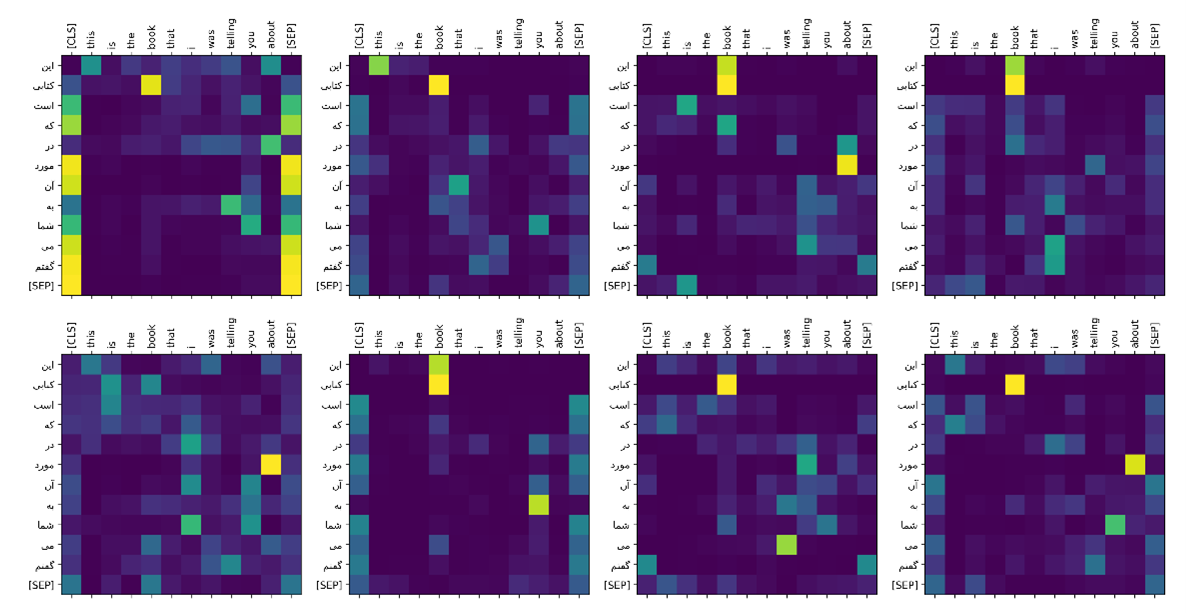
مثال های بیشتر:
Transformer 60M
مدل Transformers سنگین ما به صورت زیر تعریف میشود
- N=6
- d_model=256
- h=8
- dff=1024
- dropout rate=0.1
در تمامی لایه ها dropout_rate برابر 0.1 برای مقابله با overfit استفاده میشود. این مدل بر روی همان داده ها و به صورت مدل های قبلی Train میشود.
دقت در هر ایپاک
سنگین ترین مدل ما به دقت رسید و زمان train شدن آن حدود ساعت است.
نمودار Loss در هر ایپاک
نمودار بالا نشان میدهد که مشکل
overfit داریم.
Evaluation
ما یک مجموعه برای تست مدل هایمان استفاده کردیم. در این مجموعه سعی کردیم از انواع مختلفی از متن های انگلیسی که چالشی هستند استفاده کنیم.
- متن با زمان های متفاوت
- متن با نقل از فرد دیگر
- متن دارای relative clause
- متن دارای سوال
- متن شامل اصطلاح
- متن دارای عدد و ...
بر روی این مجموعه مدل Transformer 60M ما دارای BLEU SCORE: 49 است.
| BLEU Score |
Interpretation |
| 20 - 29 |
The gist is clear, but has significant grammatical errors |
| 30 - 40 |
Understandable to good translations |
| 40 - 50 |
High quality translations |
| 50 - 60 |
Very high quality, adequate, and fluent translations |
| Target |
Source |
# |
| او هر کدام سه سیب با 1.50 دلار خرید. |
She bought three apples for $1.50 each. |
1 |
| آن ها خوشحال بودند ، اگرچه پول کمی داشتند. |
They were happy, although they had little money. |
2 |
| چون سرد بود کت و دستکش پوشید. |
Because it was cold, she wore a coat and gloves. |
3 |
| پروژه ای که سال گذشته شروع شد تقریبا کامل است. |
The project, which was started last year, is almost complete. |
4 |
| به محض اینکه او رفت ، باران شروع به باریدن کرد. |
No sooner had she left than it started raining. |
5 |
| آیا می توانید دریا را ببینید ؟ |
Can you see the sea? |
6 |
| یک پا را بشکن! |
Break a leg! |
7 |
| باران گربه و سگ می بارد. |
It's raining cats and dogs. |
8 |
| خورشید می درخشید و پرندگان آواز می خواندند که روز کاملی می ساخت. |
The sun was shining, and the birds were singing, which made for a perfect day. |
9 |
| او فیلم را دوست نداشت زیرا خیلی طولانی بود ، اما از موسیقی لذت می برد. |
She didn't like the movie because it was too long, but she enjoyed the music. |
10 |
Tokenizers
در این پروژه ما از توکنایزهای از پیش train شده استفاده میکنیم. این نوع توکنایزرها مقادیرهایی که در vocabulary خود پیدا نمیکنند آن را به اجزای کوچک تر تبدیل میکنند و از آنها استفاده میکنند.
برای انگلیسی از BERT و برای فارسی از GPT2 استفاده کردیم.
استفاده از این توکنایزرها مشکل تولید شدن توکن <UNK> را حل میکند.
Data
داده های ما از زیرنویس فیلم ها، کتاب ها، اخبار، پادکست ها و ... بدست آمده است. جملات انگلیسی را جمع آوری کردیم و سپس با یک script داده ها را به صورت دسته دسته بر روی چند thread به google translate دادیم و ترجمه آن را بدست آوردیم. داده های تکراری حذف شده و سپس زبان انگلیسی با استفاده از NLTK نرمال سازی میشود و زبان فارسی با استفاده از Parsivar نرمال سازی میشود.
یکی از مشکلات داده ها این است که برخی از انواع جملات به خصوص اصطلاحات در آن نیست (اگر باشد گوگل نتوانسته به درستی آن را ترجمه کند).
مثلا
Game of go به معنای بازی Go در دیتاست نیست پس قائدتا مدل نمیتواند به درستی آن را تشخیص دهد.
تعداد داده ها در مدل برای این تسک بسیار کم است.
Beam Search
ما از Beam Search برای بهبود ترجمه استفاده میکنیم. این روش به جای انتخاب حریصانه تنها بهترین کلمه در هر زمان، چندین گزینه را در هر مرحله انتخاب میکند و تا انتهای دنباله پیش میرود. سپس، بهترین جمله تولید شده از بین گزینههای مختلف برگردانده میشود. Beam Search به دلیل بررسی و ارزیابی چندین مسیر ترجمه، دقت نهایی ترجمه را بهطور قابل توجهی افزایش میدهد. با این حال، این افزایش دقت با هزینه کاهش سرعت اجرا همراه است، زیرا الگوریتم نیاز به پردازش و ارزیابی چندین مسیر بهطور همزمان دارد.
مقایسه
دقت در هر ایپاک
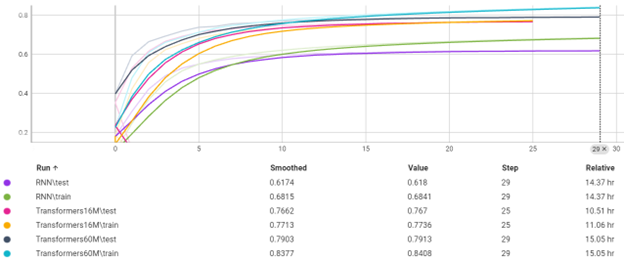
Loss در هر ایپاک
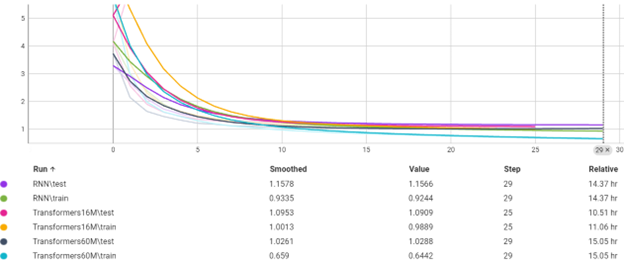
نمودار های بالا نشان میدهد که مدل Transformer بهتر از RNN عمل کرده با وجود اینکه مدل سبک Transformer با 16M پارامترهمانند RNN دارای Embedding dim = 128
سنگین ترین مدل ما با 60M پارامتر فقط 30min بیشتراز RNN زمان برای ترین نیاز داشته که همین نشان دهنده مشکل RNN در موازی سازی است.
مدل های Transformer نشان دادند که جملات طولانی را بهتر از RNN ترجمه میکنند و Long term dependency را در جملات بهتر پیدا میکنند.
| Accuracy |
BLUE Score Beam |
BLEU Score Greedy |
Parameters |
Model |
| 61% |
- |
22 |
10M |
RNN With Attention |
| 76% |
47 |
45 |
16M |
Transformer 16M |
| 79% |
51 |
49 |
60M |
Transformer 60M |
قدم های بعدی
- مدلی که در مقاله Attention is all you need ارائه شده بر روی 30M داده ترین شده و ما فقط 1M داده داشتیم. در مراحل بعد هدف داریم تا داده های بیشتری جمع آوری کنیم.
- داده ها باید جنبه های مختلف داشته باشد مثلا اصطلاحات بیشتری در خود داشته باشد
- داده ها باید بهتر تمیز شود و فقط به گوگل بسنده نمیکنیم
