طبقه بندی متن(text classification)

/*! elementor - v3.17.0 - 08-11-2023 */ .elementor-heading-title{padding:0;margin:0;line-height:1}.elementor-widget-heading .elementor-heading-title[class*=elementor-size-]>a{color:inherit;font-size:inherit;line-height:inherit}.elementor-widget-heading .elementor-heading-title.elementor-size-small{font-size:15px}.elementor-widget-heading .elementor-heading-title.elementor-size-medium{font-size:19px}.elementor-widget-heading .elementor-heading-title.elementor-size-large{font-size:29px}.elementor-widget-heading .elementor-heading-title.elementor-size-xl{font-size:39px}.elementor-widget-heading .elementor-heading-title.elementor-size-xxl{font-size:59px}
طبقه بندی متن (text_classification)
/*! elementor - v3.17.0 - 08-11-2023 */ .elementor-widget-image{text-align:center}.elementor-widget-image a{display:inline-block}.elementor-widget-image a img[src$=".svg"]{width:48px}.elementor-widget-image img{vertical-align:middle;display:inline-block}
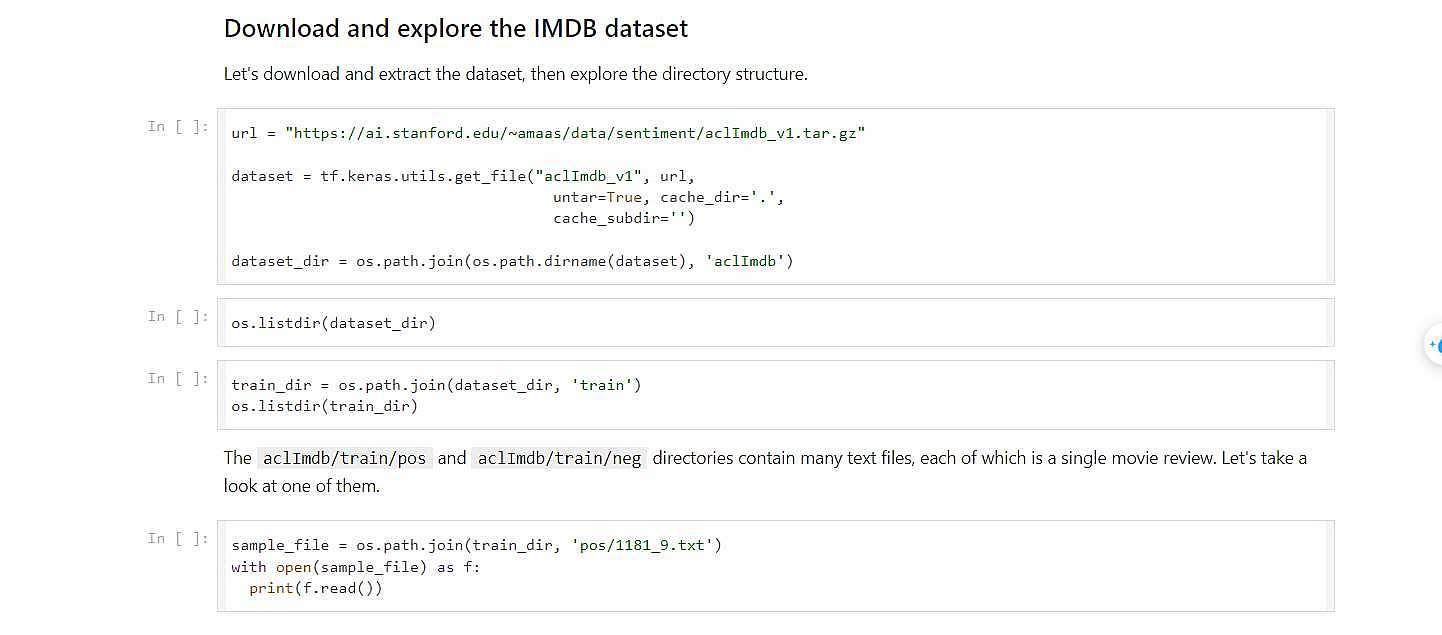
جلسه اول مبا حث ویژه دوم : هدف آشنایی ما با متن است در این جلسه ، در این جلسه ما با طبقه بندی یا کلاس بندی متن شروع می کنیم همان (text_classification)، کد مورد استفاده در این جلسه از سایت رسمی تنسرفلو است! دیتای استفاده شده جهت تحلیل احساسات کاربر است یعنی ( حس کاربر را از روی متن استخراج کنیم) که دیتاست مورد استفاده متن های کامنت های کاربران در سایت IMDB نوشته شده است. ما قرار است براساس این نظرات بفهمیم که کاربر از فیلم حس خوب داشته یا نه از فیلم خوشش نیامده که داده های ما به دو کلاس علاقه مند به فیلم یا منتفر از فیلم تقسیم بندی می شوند!
دیتا ست مورد استفاده
دیتاست که ما در این course استفاده کردیم از سایت استنفورد که داده از سایت IMDB برداشته شده است و تگ گذاری شده که به دو دسته نظرات مثبت و منفی تقسیم شده است که با استفاد از tf.keras.utils.get_file گرفته که می توانیم موقع دانلود بگوییم آن را extract کن . برای load کردن دیتاست ما از دستورtext_dataset_from_directory() استفاده می کنیم ! ما چون آدرس های پوشه ها را نگاه می کند و بر مبنای نام پوشه ها کلست می سازد!ما باید پوشه unsup را حذف کنم و بعد هم در subset می گویم که 80 درصد برای train و 20 درصد را برای validation قرار بده و در این دستور ما از seed هم استفاد کردیم که جهت تکرار پذیری (یک جای دیگر برای دیباگ کردن استفاد می شود). اما اینجا می خواهیم دوبار اجرا کنیم یک بار برای train و یک بار دیگر برای validation چون یکبار shuffle میکند و 80 درصد رای می دهد و اگر seed را ندهیم دوباره shuffle می کند و 20 درصد را که کنار نگذاشته باشد یعنی به زبان راحت تر داده های train در Validation ممکن است تکرار
الان برای آموزش متن با چیکار می کنیم:
1_باید یک سری کارهای پیش پردازش آن ها انجام دهیم پیس یک تحلیل روی داده ها داشته باشیم
1_ بزرگ بودن حروف برای ما کاربردی ندارد و 2_علامت های پرسشی و تعجبی هم برای من بار معنایی خاصی ندارد .
پس ابتدا ما باید متن را استاندارد کنم بعد از آن مرحله tokenize کردن هست!یک جمله که می بینم برای token کردن از کلمه استفاده می کنیم.
البته که توکن را چطور شناسای کنیم مهم است که کتابخانه های tokenizer پرکابرد زیاد است!
و در آخر باید تبدیل کردن به عدد است که ما LUT می سازیم که عدد صفر(0) برای هیچی و عدد یک (1 ) جهت <unknown> کلمات که تکرار آن در دیتاست من کم بوده است.و از عدد 2 به بعد کلمات را به صورت نزولی براساس تعداد تکرار مرتب می کنیم حال اگر کلمه ای در دیتاست ما کم تکرار بود ما آن را unknown در نظر می گیریم
3_vectorize : که با استفاده از LUT می بینیم هر token چه کدی دارد اگر بود کد آن را می خواند و در غیر این صورت unknown می گذاریم این گونه متن تبدیل به یک وکتور می شود که مدل ما روی آن کار کند! که به مرور می فهمد هر عدد یک معنای خاص دارد. این هیچی هما ن padding است ! جهت یکسان سازی ! یکسان سازی طول کلمات در حکم همان zero_padding است در تصاویر.
کار با فریم ورک keras
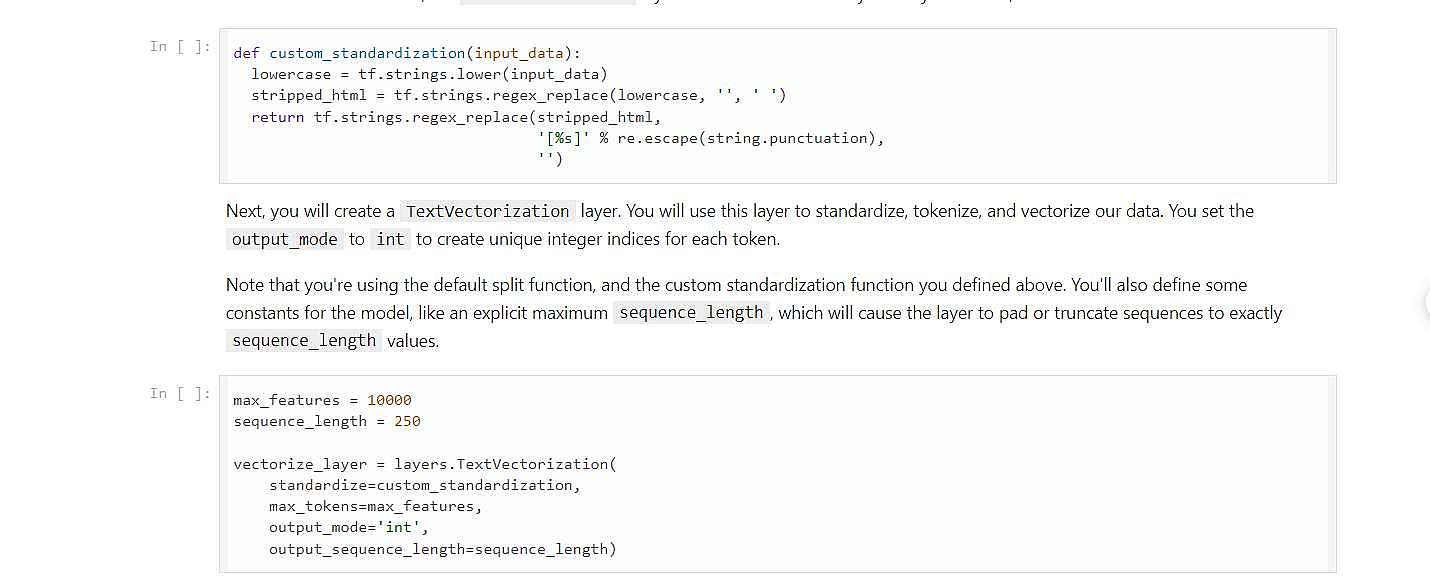
یک لایه ای وجود دارد به نام TextVectorization که 3 کار را انجام می دهد.
1_استاندارسازی_2_tokenize _ 3_vectorize . که به صورت پیش فرض حروف را کوچک می کند و همان علامت سوال و اینا را برمی دارد و علاوه بر این در کلمات دیتابیس یک break قرار گرفته(برو خط بعد) علاوه بر حذف اون موارد این break هم باید حذف کنیم که ما تابع coustom_standard را نوشتیم !
حال ما دو پارامتر دیگر هم داریم 1_squence_length،تا کجا کلمات را داشته باشیم می خواهد طول جمله را مشخص کند.اگر طول آن کمتر بود باید تا طول مورد نظر صفر قرار دهد و در غیر این صورت اگر طول آن بیشتر بود باید تا همان طول را قرار دهد و بقیه را دور بریزد.و max_token هم برای این است که چه تعداد token در LUT قرار بدهم.
در نهایت که tf.data درست می شود یک object هست که می توان روی آن for بزنیم ما می توانیم map بزنیم که تابع روی همه ی minibatch ها اعمال می شود که ورودی من x و y است (text,label )و دیتا را می گیرد ؟ حالا چرا؟ مگر ما vectorize_layer نساخته ام وقتی به آن جمله می دهیم باید آن سه کار را انجام دهد من به آن یک لیست می دهم ! کار نمی کند؟ چون table را ندارد و LUT را قرار است خودش بسازد نه ما پس برا ی ساخت آن ما باید کل دیتا را به آن بدهیم ! پس tf.data که کل دیتا را باید ببیند! حالا برای ساخت LUT به درد می خورد که من آن را adapt کنم به لایه وکتورایزشن حتی با دستودر get_vocabulary به من token ها را می دهد!
حال بریم ببینم چطور ما با مدل می توانیم آن را حل کنیم ؟
.
می گم چه خوب خود اگر داده های ما یکسری ویژگی fetureas داشت اگر من one_hot کنم اونوقت حجم مموری زیاد می گیرد .2_ اگر این کار را انجام دهم هر دو کلمه دو تا فاصله دارند! پس می رود کنار اگر هم فاصله اعداد هم بگیرد خوب نیست.
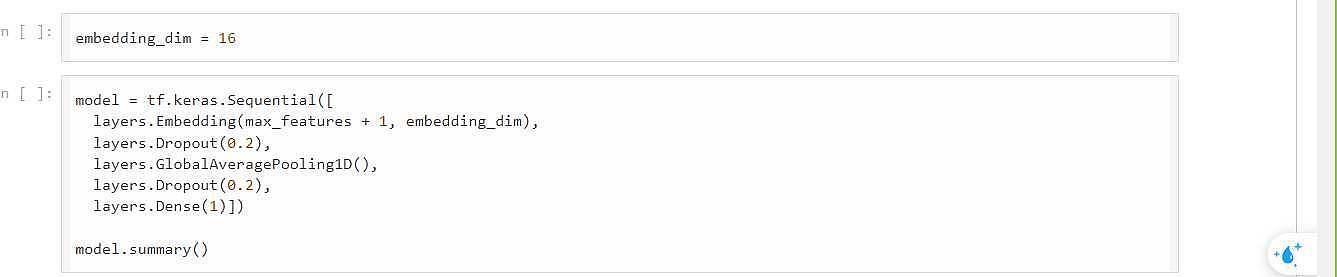
چه خوب بود ما برای کلمات یکسری ویژگی استخراج کنیم اگر کسی این کار را بکند خیلی خوب است اگر ما 16تا ویژگی را embed کند! که می توان یکسری ارتباط منطقی پیدا کرد! که الگوریتم های در این حوزه وجود دارد که روابط را خوب tune می کند ! من می خواهم امکان ساخت این 16 تایی را بدهم !
Embedding_dimaention : یک وکتور چندتایی به عنوان ویژگی بگیریم ، حال مدل از نوع ترتیبی را می سازم و لایه embedding را یک نوع ماتریس و بعد هم یک لایه Avg_pooling را قرار می دهیم و flat کردم و درضمن لایه embedding ما بایاس ندارد.
و در آخر هم مدل را تست کرده که مشاهده می شود زیاد کار ا نیست به علت اینکه میانگین می گرد و به تریت کلمات توجه نمی کند و در آخر مدل را export می گیریم و از آن استفاده می کنیم.
