آشنایی با متریک و توضیح ngrams

/*! elementor - v3.17.0 - 08-11-2023 */ .elementor-heading-title{padding:0;margin:0;line-height:1}.elementor-widget-heading .elementor-heading-title[class*=elementor-size-]>a{color:inherit;font-size:inherit;line-height:inherit}.elementor-widget-heading .elementor-heading-title.elementor-size-small{font-size:15px}.elementor-widget-heading .elementor-heading-title.elementor-size-medium{font-size:19px}.elementor-widget-heading .elementor-heading-title.elementor-size-large{font-size:29px}.elementor-widget-heading .elementor-heading-title.elementor-size-xl{font-size:39px}.elementor-widget-heading .elementor-heading-title.elementor-size-xxl{font-size:59px}
جلسه دوم: بررسی دوباره طبقه بندی متن(آشنایی با متریک ها):
هدف این جلسه بررسی دوباره کد طبقه بندی متن برای کد tensorflew و همچنین توضیح کد طبقه بندی متن فارسی. تا اینجا پیش رفتیم که با استفاده از Vectorizeation رسیدیم که سه عمل (1_استاندارسازی ؛tokenizationو در آخر vectorization) انجام ی دهد.که LUT که می ساخت به صورت نزولی بود که به ترتیب به جز شماره 0و1 که از پیش مشخص شده است بقیه کلمات به ترتیت بیشترین تکرار است. و ما یک مشکل داریم که اگر کلمات دارای Avg یکسان بود(ترتیب را عوض کردیم) یکی می دید و یکسان پیش بینی می کرد.
/*! elementor - v3.17.0 - 08-11-2023 */ .elementor-widget-image{text-align:center}.elementor-widget-image a{display:inline-block}.elementor-widget-image a img[src$=".svg"]{width:48px}.elementor-widget-image img{vertical-align:middle;display:inline-block}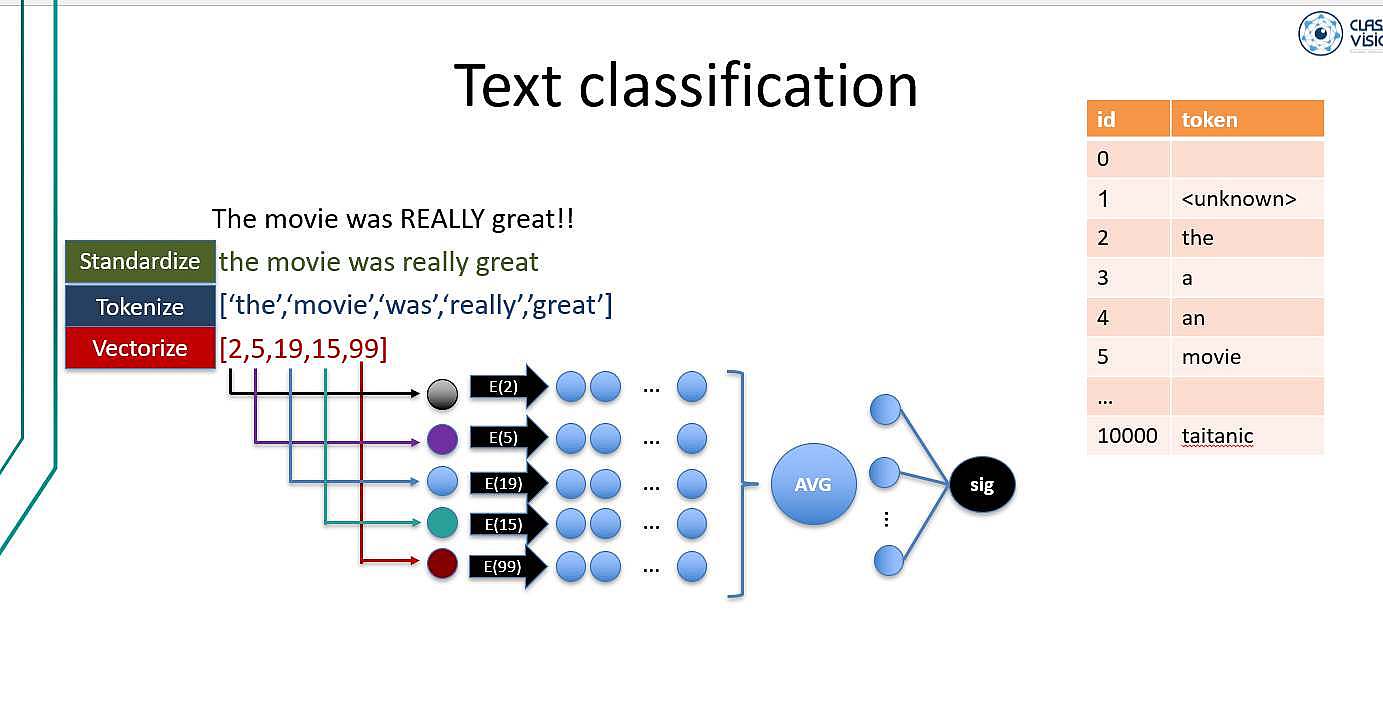
ngrams
یک ایده ای که وجود دارد(ایده ضعیف) دوتایی های کنار هم در نظر بگیریم ! که پارامتر ngrams که هم عدد و هم tuple می گیرد البته در دیتای کوچک ممکن است خراب کند اما در دیتای بزرگ الان که map می زنم بیشتر طول می کشد.و لزوما همه ی bigram ها معنادار نیست و unknown می خورد. حداقل توقع دارم که مشکل قبل ندارد که به این روش ngram می گویند. و بعضی مواقع bigram مهم تر می شوند!
داده های نامتوازن(imbalanced)
یک مشکل را دیدیم اگر داده ها نامتوازن باشد. Metric ها را با مشکل مواجه می کند. یعنی 99 درصد مدل من درست میگه ولی برای وقتی که کلاست ها متوازن باشد . 50 درصد کلاس اول و 50 درصد کلاس دوم.
1_من باید metric را درست کنم Accuracy زمانی خوب است که بالانس باشد کلاس ها
2_ باید روش حل مسئله را بررسی کنم که به کلاس ها کم اهمیت بدهد.
ابتدا روش تغییر متریک : مثال معروف سایت Kaggle که 284807 تراکنش 429 تراکنش frauds می شود (دور زدن بانک)؟ و task این است که fraud هست یا نه ؟ پس در این مسئله ها Acc معیار مناسبی نیست؟پس باید چکار کرد؟ یک جدول می کشند که براساس آن متریک ها را در می آورند؟
سطرها پیش بینی های ما است و ستون ها : label ها واقعی است.
که براساس جدول ما چهار حالت داریم :
1_TP : میزان برچسب هایی که مثبت بوده است و توانسته درست پیش بینی کند.
2_FP : میزان برچسب هایی که مثبت نبوده است و به اشتباه گفته مثبت است.
3_FN : میزان برچسب هایی که مثبت بوده است که به اشتباه گفته منفی است.
4_TN : میزان برچسب هایی که منفی بود است و به درستی گفته منفی است.

precision و recall
براساس این جدول دو معیار precision و recall
1_precison : می گه اگر گفتی کلاس positive را دیدی چقدر مطمئنی بوده
2_recall : چه قدر مطمنی از کلاس positive را توانستی به درستی پیش بینی کند.
من یک معیار ترکیبی از این دوتا باشه،F_measure را تعریف می کنم دو برابر حاصل ضرب precison و recall ضرب در 2 ، تقسیم بر حاصل جمع precison و recall به صورت زیر:
البته این معیار های ارزیابی بوده است که ما استفاده کردیم و در بخش بعد به تکنیک وزن دهی به کلاس ها بررسی می شود

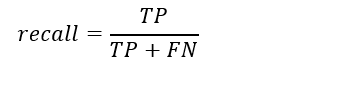
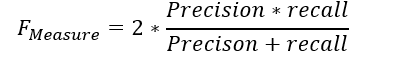
قسمت بعد شامل توضیح کار با داده ها ی نا متوازن و همچنین تکنیک classwitght است در یک بلاگ پست جدا ارائه می کنم