جلسه اول صوت

/*! elementor - v3.17.0 - 08-11-2023 */ .elementor-heading-title{padding:0;margin:0;line-height:1}.elementor-widget-heading .elementor-heading-title[class*=elementor-size-]>a{color:inherit;font-size:inherit;line-height:inherit}.elementor-widget-heading .elementor-heading-title.elementor-size-small{font-size:15px}.elementor-widget-heading .elementor-heading-title.elementor-size-medium{font-size:19px}.elementor-widget-heading .elementor-heading-title.elementor-size-large{font-size:29px}.elementor-widget-heading .elementor-heading-title.elementor-size-xl{font-size:39px}.elementor-widget-heading .elementor-heading-title.elementor-size-xxl{font-size:59px}
مقدمات صوت
/*! elementor - v3.17.0 - 08-11-2023 */ .elementor-widget-image{text-align:center}.elementor-widget-image a{display:inline-block}.elementor-widget-image a img[src$=".svg"]{width:48px}.elementor-widget-image img{vertical-align:middle;display:inline-block}
صوت : یک سیگنال است.سیگنال تغییرات در زمان مشخص است،سیگنال صوت تغییرات در فشار هوا(فشردگی هوا) که به گوش ما می رسد.
مثال در بورس تغیرات قیمت.
که ما صوت را برای اینکه درک کنیم به صورت موج میبینیم! که در این نمودار محورx محور زمان است و محورy میزان شدت آن است.ویک نکته صوت که صحبت می کنیم نمودار آن به این قشنگی نیست و از فرکانس های مختلفی تشکیل شده است.که صدا در نگاه اول یک شکل عجیب و غریب است که فوریه گفت هر سیگنال تناوبی را به هر شکلی حتی به صورت موج مربعی را می توان به صورت sin و cos در آورد!
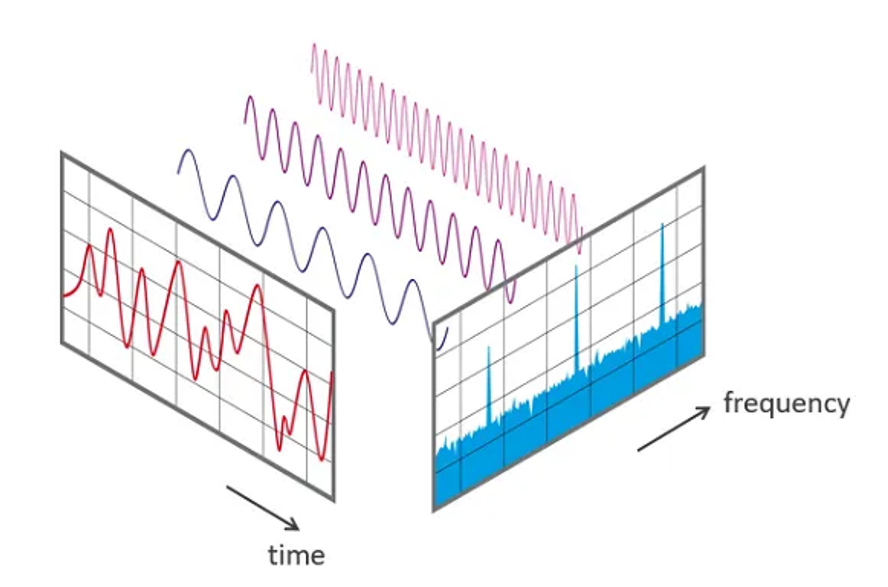
.1_time Domain و 2_ Frequency Domain
تعریف مهفوم اول: وقتی سیگنال می دهند که محور x آن زمان است و محور y میزان شدت صوت را نشان می دهد که این تعریف time Domain است.
برای مفهوم دوم از سری فوریه کمک می گیریم که سیگنال را که مشکنیم به چند سیگنال آن ار به frequency Domain تبدیل می کنم. مثلا 5 ثانیه بر می داریم چه فرکانسی داشته و که محور x آن فرکانس است.و محورy آن Amputate است . یک پریود زمانی در نظر بگیریم ! اون نمودار بر مبنای زمان را به بخش هایی می شکند.
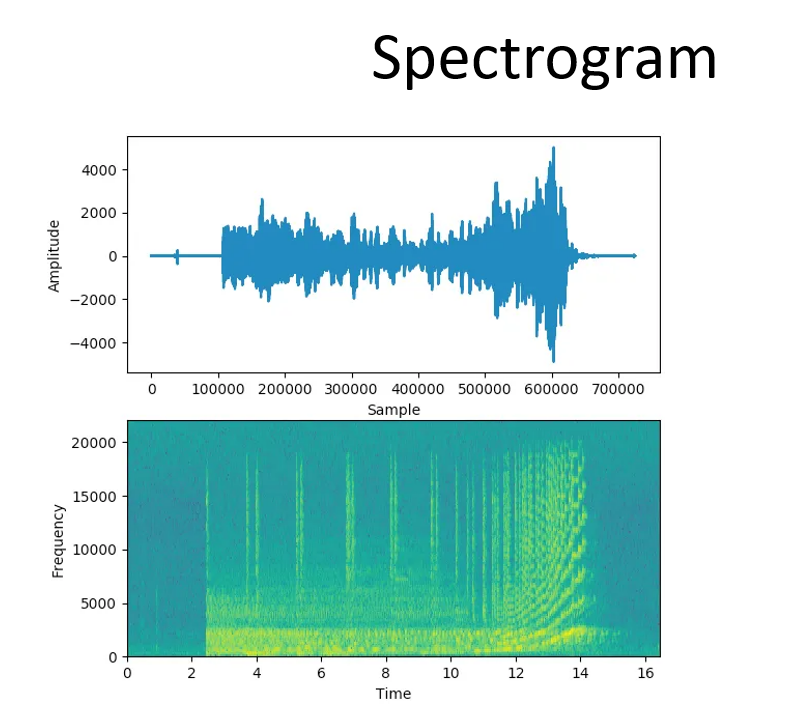
حال نوبت Spectogram :به عنوان پیش پردازش اصوات در یادگیری عمیق استفاده می کنیم من یک داده صوتی دارم که محورx آن زمان sample rate است و y چه بازه فرکانسی آست و شدت آن را براساس رنگ مشخص می شود. از این ترکیب ها نمی فهمد و از فوریه استفاده می کند! که آن را به سیگنال های تشکیل دهند می شکند.
و بعد از آن که ما فایل صوتی را به spectrogram تبدیل کردیم می توانیم مثل تصویر با آن رفتار کنیم !
و یک بعد به آن اضافه می کنیم که بتوانیم روی آن کانولوشن بزنیم و حال مدل شبکه عصبی که ورودی آن است را میسازیم یک کانولوشن ساده در مرا حل بعد ما می توانیم ا ز شبکه های عصبی RNN (LSTM,GRU ) استفاده کنیم . و بعد از آن می توان از ترنسفور مر هم در آن استفاده کنیم
توضیحات کد ساده در خصوص طبقه بندی صوت
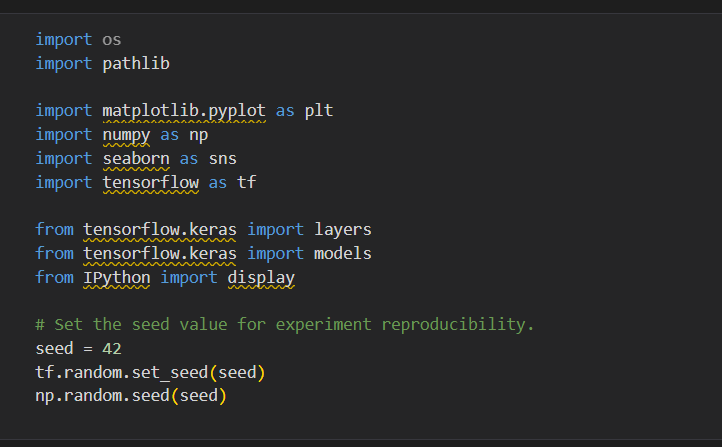
ابتدا مانند هر برنامه دیگری ما کتابخانه های مورد نظر را import می کنیم مانند Tensorflow و numpy و IPython (این کتابخانه برای نمایش spectogram) مورد استفاده قرار می گیرد

پس از بارگذاری و لود داده ها ونمایش صوت که دیدیم نمی توانیم از آن ها الگوهای خاصی استراج کنیم والبته یکسری پیش پردازش شامل squeze کردن ما فایل های wav رابه spectogram تبیدیل می کنیم و چند نمونه از آن را با کمک matplotlib رسم می کنیم.
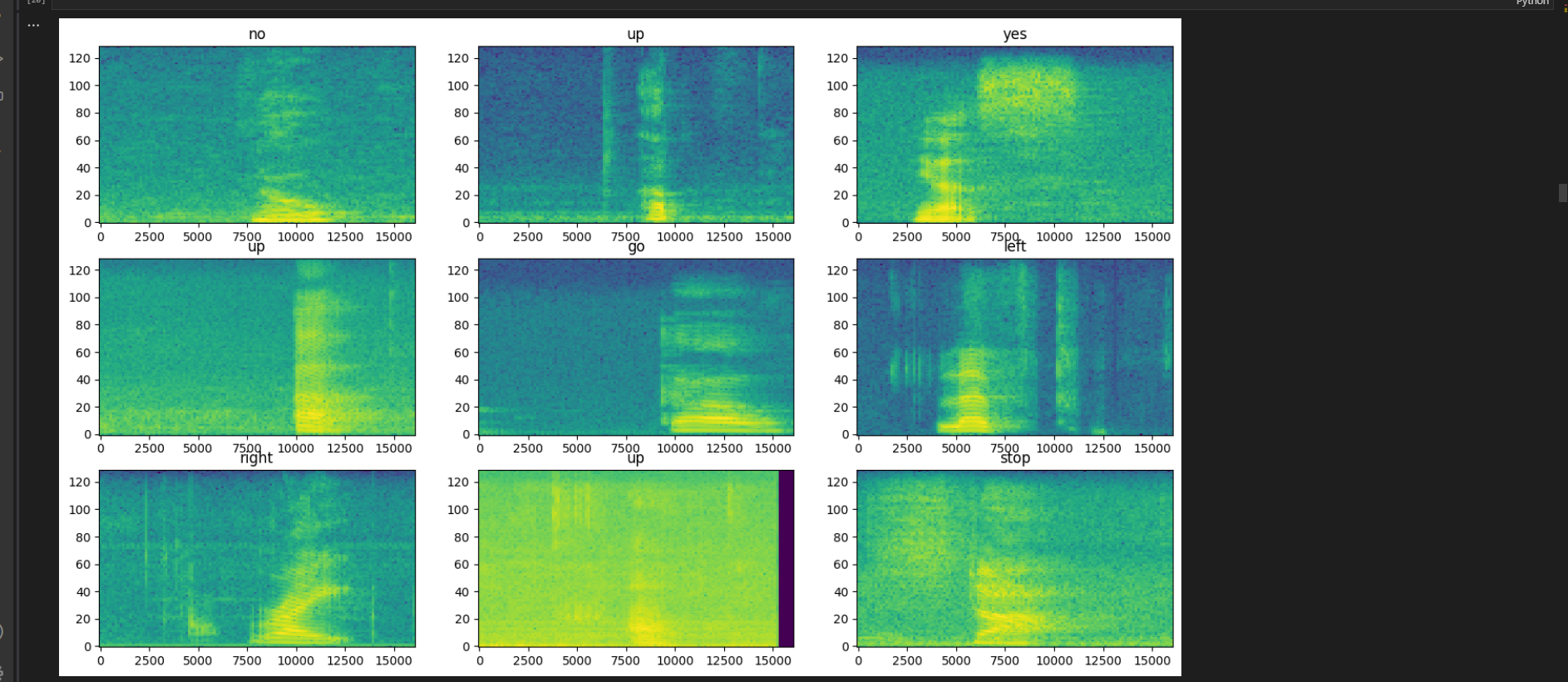
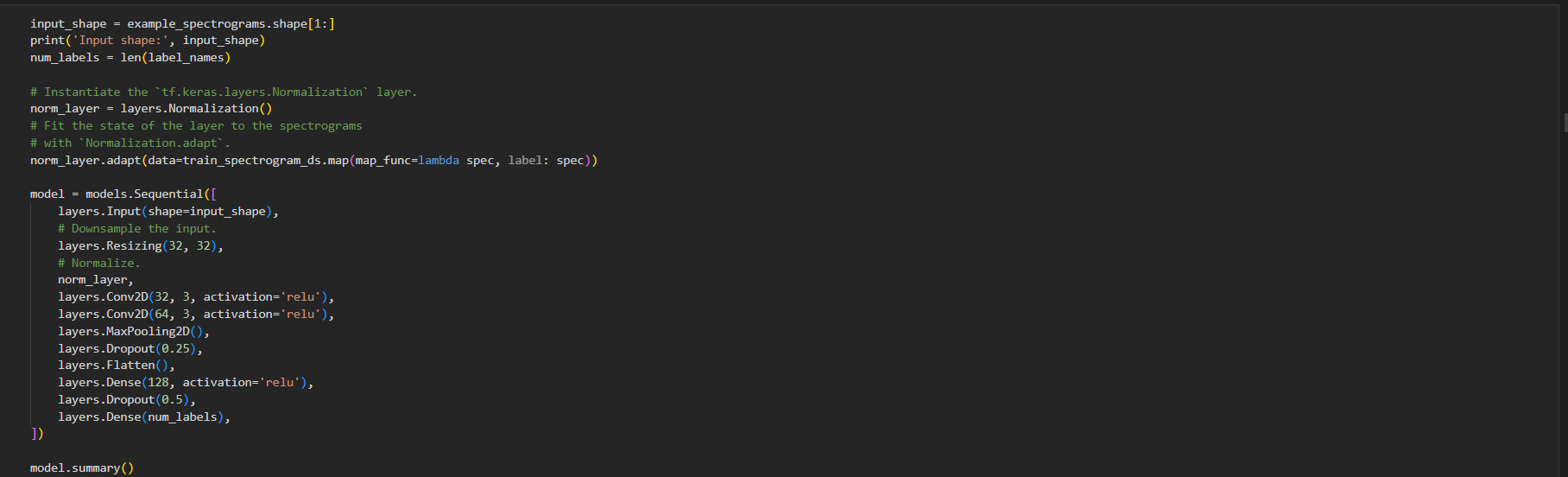
در قسمت همان طور که گفتم الان که توانستم صوت را تبدیل به spectogram کنم کافی است یک شبکه عصبی کانولوشنی ایجاد کنم که مدل یاد بگیرد و بعد از آن دقت مدل را بسنجیم که مدل خوب کار می کند یا نه
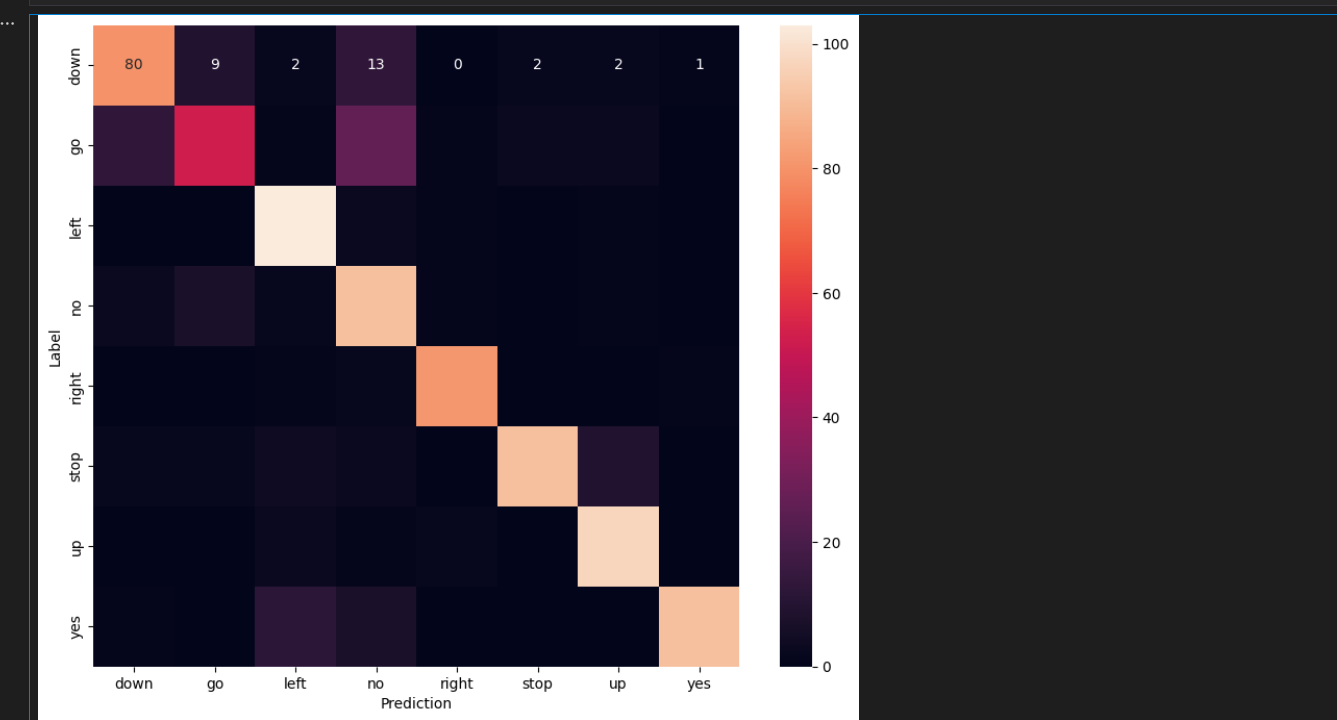
در آخر ما مدل را 10 آیپاک آموزش دادیم و بعد از آن ماتریس آشفتگی را که رسم کردیم نتیجه خیلی مورد رضایت بود که به صورت زیر مشاهده می کنید.