Linear Regression
ما از رابطه رگرسیون خطی جهت یافتن رابطه علت و معلولی بین متغیر ها جهت پیش بینی خروجی باتوجه به ورودی استفاده می کنیم.در رابطه رگرسیون خطی بین متغیر مسقل x و متغیر وابسته y رابطه خطی ایجاد میکنیم.در ابتدا با تعریف یک صفحه از نقاط رندم در کد پایتون خود نمودار x و y اولیه را تعریف میکنیم بدین صورت که:
x = np.linspace(-3, 3, 100)
دیتاست فرضی ما و تقسیم بندی ورودی و خروجی های ما بر اساس نمودار xوy بصورت زیر است
سپس از 75 درصد دیتا به عنوان trainو از 25 درصد باقی به عنوان مجموعه test استفاده میکنیم
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
از الگوریتم های موجود در LinearRegression جهت فیت کردن رگرسیون خطی خود استففاده میکنیم
from sklearn.linear_model import LinearRegression
regressor = LinearRegression()
regressor.fit(X_train, y_train)
پس از فیت کردن دیتاست خود مقادیر عرض از مبدا (_intercept)و ضرائب(_coef) برای رگرسیون خطی ما تعریف میشوند
از انجا که رگرسیون خطی ما از توابع خطی پیروی میکند رابطه xوy بصورت عبارت ریاضی زیر تعرف خواهد شد:
سپس با استفاده از مقادیرmax و min بدست امده ازمعادله بالا خط رگرسیون را پیدا میکنیم
min_pt = X.min() * regressor.coef_[0] + regressor.intercept_
max_pt = X.max() * regressor.coef_[0] + regressor.intercept_
plt.plot([X.min(), X.max()], [min_pt, max_pt])
plt.plot(X_train, y_train, 'o');
انقدر خط بدست امده از رگرسیون را جابجا میکنیم تا نقاط دیتا ست ما کمترین فاصله ممکن(یا کمترین تابع هزینه ) را از خط رگرسیون داشته باشند
MSE(تابع هزینه)
جهت محاسبه تابع هزینه خط رگرسیون از دیتاست از فرمول زیر استفاده میکنیم
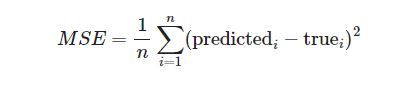
Linear models
مدل های خطی زمانی مفید هستند که داده های کمی در دسترس باشد یا برای فضاهای ویژگی بسیار بزرگ مانند طبقه بندی متن. علاوه بر این، انها یک مطالعه موردی خوب برای regularization را تشکیل می دهند.
مدل های خطی برای رگرسیون
y_pred = x_test[0] * coef_[0] + ... + x_test[n_features-1] * coef_[n_features-1] + intercept_
ما از مدل های متفاوتی جهت تنظیم ضرائب و عرض از مبدا رگرسیون خطی خود استفاده میکنیم تا با توجه به انها محدوده مناسب برای پیدا کردن مناسبترین ضرائب (coef_) با کمترین میزان تابع هزینه داشته باشیم
استاندارد ترین مدل خطی "ordinary least squares regression" است که اغلب به سادگی "رگرسیون خطی" نامیده می شود. این هیچ محدودیت اضافی در coef_ قرار نمی دهد، بنابراین هنگامی که تعداد ویژگی ها زیاد است، ان را خراب می کند و مدل overfit خواهد شد
Linear Regression
تابع هزینه ما یافتن کمترین مقدار(MIN) عبارت زیر خواهد بود
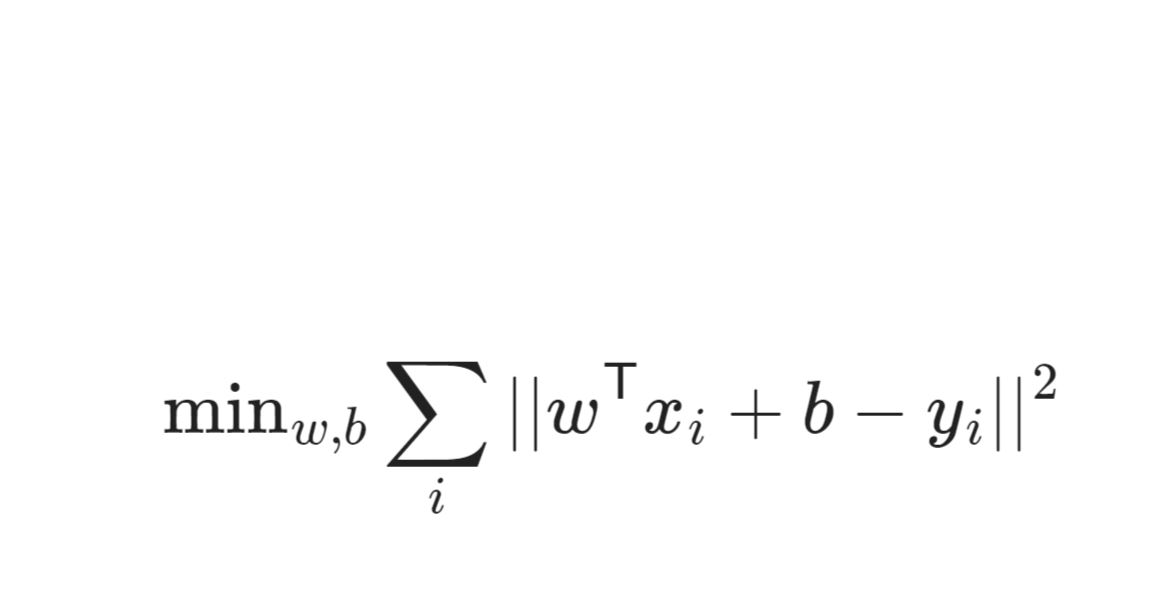
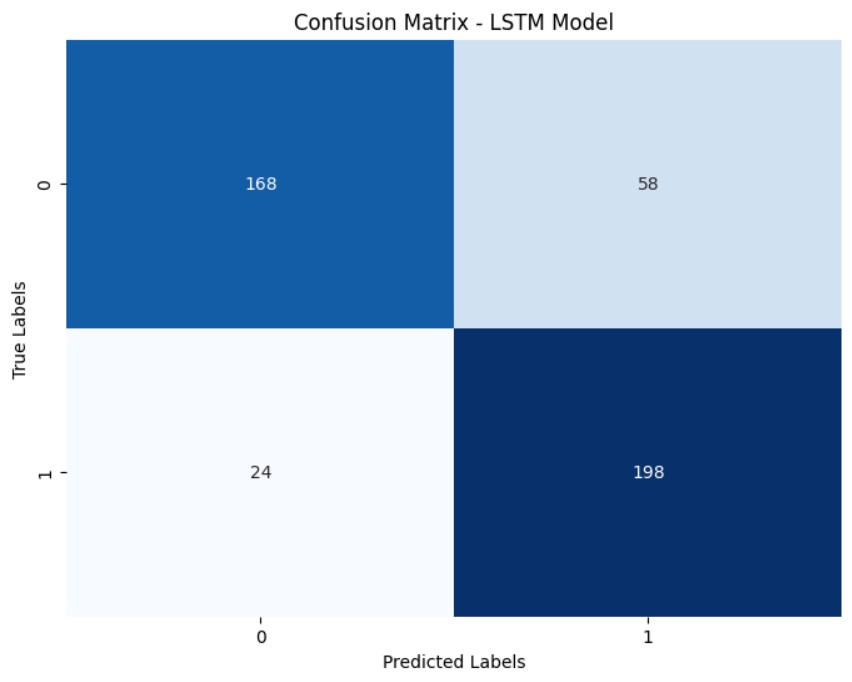
پس از تقسیم بندی دیتاست به مجموعه train و test وسپس فیت(fit) کردن مجموعه train بر رگرسیون به نمودار مشابه با تصویر زیر دست خواهیم یافت که تفاوت دقت رگرسیون ما با اصل دیتا ست با دو رنگ متفاوت نارنجی و ابی مشخص است:
Ridge Regression (L2 penalty)
در ridge regression از روش دیگری برای محدود کردن ضرائب خود استفاده می کنیم, در مدل قبلی regression به علت توجه بیش از اندازه به بعضی ویژگی ها که خیلی در تعیین y موثر نخواهند بود نیاز داریم تا از alpha برای تعیین کمترین مقدار تابع هزینه خود استفاده کنیم تا بتوانیم قدرت کنترل تاثیر مقدار مربع ضرائب (w^2) بر ویژگی های بدرد نخور را محدود کنیم
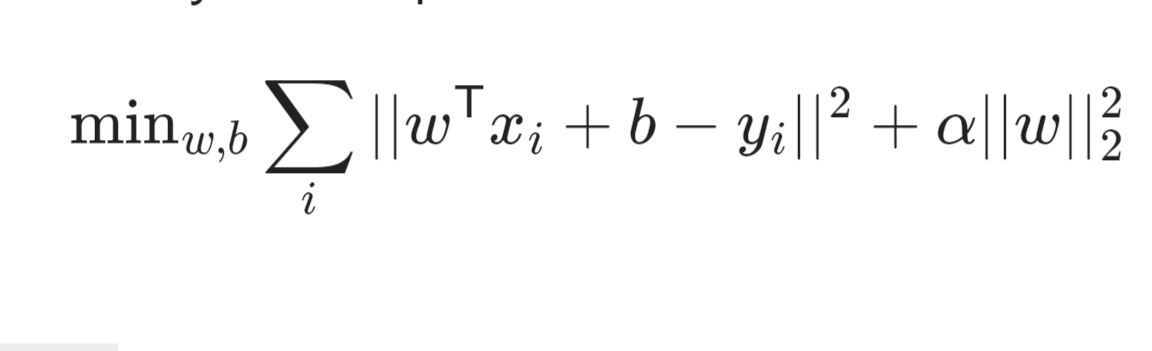
سپس بصورت تقریبی چند مقدار مختلف را برای alpha انتخاب میکنیم و در مجموعه ای قرار میدهیم و سپس با مقایسه مقدار تابع هزینه رگرسیون با توجه به هر کدام از alpha ها مناسب ترین انها را انتخاب میکنیم
from sklearn.linear_model import Ridge
ridge_models = {}
training_scores = []
test_scores = []
for alpha in [100, 10, 1, .01]:
ridge = Ridge(alpha=alpha).fit(X_train, y_train)
training_scores.append(ridge.score(X_train, y_train))
test_scores.append(ridge.score(X_test, y_test))
ridge_models[alpha] = ridge
plt.figure()
plt.plot(training_scores, label="training scores")
plt.plot(test_scores, label="test scores")
plt.xticks(range(4), [100, 10, 1, .01])
plt.legend(loc="best")
با توجه به نمودار بالا بهترین مقدار alpha با کمترین مقدار تابع هزینه یا mse برای رگرسیون ما مقدار alpha=10 خواهد بود
Lasso (L1 penalty)
نحوه کارکرد و محدوده یابی ضرائب تابع در رگرسیون لاسو(lasso) مانند روشridge خواهد بود با این تفاوت که در اینجا alpha بر خود ضرائب w (و نه مقدار مربع ضرائب w^2) را محدود میکند تا از تاثیر ضرائب در ویژگی های کم اهمیت تر دیتاست ها جلو گیری کند
تابع یافتن mse در روشlasso بصورت زیر خواهد بود
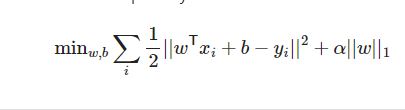
سپس مانند روش قبلی در ridge regression در مجموعه ای بصورت تقریبی چند مقدار مختلف را برایalpha انتخاب میکنیم و در مجموعه ای قرار میدهیم و سپس با مقایسه مقدار تابع هزینه رگرسیون با توجه به هر کدام از alpha ها مناسب ترین انها را انتخاب میکنیم
from sklearn.linear_model import Lasso
lasso_models = {}
training_scores = []
test_scores = []
for alpha in [30, 10, 1, .01]:
lasso = Lasso(alpha=alpha).fit(X_train, y_train)
training_scores.append(lasso.score(X_train, y_train))
test_scores.append(lasso.score(X_test, y_test))
lasso_models[alpha] = lasso
plt.figure()
plt.plot(training_scores, label="training scores")
plt.plot(test_scores, label="test scores")
plt.xticks(range(4), [30, 10, 1, .01])
plt.legend(loc="best")
با توجه به نمودار بالا بهترین مقدار alpha با کمترین مقدار تابع هزینه یا mse برای رگرسیون ما مقدار alpha=10 خواهد بود
Linear models for classification
در روش های قبلی رگرشن ما از توابع جهت تعیین معادله برای یافتن مقدار پیشبینی شده خروجی(y) بر اساس ورودی های ما (x) و دیتاست های موجود از x و y میتوانستیم بصورت حدودی و مقداری پیوسته خروجی را محاسبه کنیم
اما برای استفاده از classification و طبقه بندی داده ها به دسته های گسسته متفاوت , باید از مدل های دیگر رگرشن نظیر logistic regression وsvc استفاده کنیم
تفاوت کارکرد تابع ریاضی classifiction نسبت به رگرشن های قبلی وجود شرط treshold بزرگتر از 0 خواهد بود
y_pred = x_test[0] * coef_[0] + ... + x_test[n_features-1] * coef_[n_features-1] + intercept_ > 0

Multi-class linear classification
یکی از روشهای خوب برای دسته بندی داده های به محدوده های مختص خودشان با استفاده از خطوط مرزی روش
svc در نمونه دیتا ست زیر خواهد بود
در این روش مانند سری قبلی با فیت (fit) کردن مدل svc براساس xو y های موجود در دیتاست ضرائب coefficients و عرض از مبدا ها intercept بهترین خطوط مرزی با کمترین مقدار تابع هزینه نسبت به دیتا ست را پیدا کرده و در کلاس بندی فرضی خود رسم میکنیم
from sklearn.svm import LinearSVC
linear_svm = LinearSVC().fit(X, y)
print(linear_svm.coef_.shape)
print(linear_svm.intercept_.shape)
در نهایت طبقه بندی دیتا ست ما در خروجی به مدل زیر خواهد بود
logistic regression
در روش لجستیک logistic ما به جواب های binary نسبت به قرار گیری یک داده در مجموعه ای خاص دست پیدا میکنیم
مبنی اصلی کارکرد تابع لجستیک بر استفاده از تابع سیگموید و نزدیک ساختن ان به تابع پله با دادن ضرائب مناسب است تا هنگام پیشبینی جواب 0 یا 1 بودن معادله با توجه به ورودی دریافتی باکمترین میزان هزینه در صحت جواب خروجی مان (انتروپی) برسیم
تابع sigmoid

حال اگر بخواهیم تابع sigmoid را به تابع پله نزدیکتر کنیم تا جواب های مان به باینری بودن نزدیکتر شوند از ورژن وزن دار(w) این تابع استفاده میکنیم

ما باید به ماشین یادگیری خود این قابلیت را بدهیم تا بهترین w متناسب با دیتاست خود را برای تابع انتخاب کند, همچنین جهت ازادی حرکت تابع در جهت محور x ها مقدار
b هم کنار wx- فرمول نهایی خود قرار می دهیم بدین صورت که:

انتروپی و نحوه محاسبه کمترین مقدار هزینه تابع با بهترین مقدار w و b بصورت زیر خواهد بود:

دیاگرام مراحل کارکرد رگرسیون لجستیک(logistic) بصورت زیر خواهد بود

سوالات:
1-کدام یک از روش های regression زیر مخصوص classification میباشد؟
الف)lasso
ب)ridge
ج)logistic
د)linear
2-کدام یک از روش های regression زیر برای محاسبه کمترین میزان خطای خود از روش زیر استفاده میکند؟
الف)lasso
ب)ridge
ج)logistic
د)linear
3- اگر بخواهیم در تابع sigmoid را به تابع پله نزدیکتر کنیم از چه روشی باید کمک گرفت؟
الف)تمام xهای موجود را به 2x تبدیل کنیم
ب)جواب نهایی تابع را معکوس کنیم
ج)از مدل های وزن دار تابع استفاده کنیم
د)از جواب نهایی تابع لگاریتم بگیریم
4-دومین مرحله در استفاده از ساختار لجستیک رگرسیون چه گامی است؟
الف)تعیین مقادیر جدید برای ضرایب
ب)محاسبه میزان خطا با کراس انتروپی
ج)بررسی میزان خطا
د)محاسبه خروجی تابع سیگموید
5- برای پیشبینی مقادیر متغیر پاسخ برای دادههایtest (دادههایی که در فرآیند مدلسازی حضور نداشتهاند) کدام یک از مدل های رگرسیون زیر مناسب نیست؟
الف)linear
ب)ridge
ج)lasso
د)هیچ کدام مناسب نیستند
پاسخ سوالات:
1-ج
2-الف
3-ج
4-د
5-الف
