طبقه بند نزدیکترین همسایه (KNN)

طبقه بند KNN یک الگوریتم یادگیری ماشین نظارت شده است که میتواند برای حل مسائل طبقه بندی استفاده شود. این الگوریتم به این صورت کار میکند که ابتدا مجموعه داده های آموزش را که شامل نمونههایی با برچسب است میگیرد. سپس، برای طبقه بندی یک نمونه جدید، فاصله آن را با تمام نمونههای آموزش محاسبه میکند. K همسایه نزدیکترین نمونه جدید را پیدا میکند و طبقه غالب همسایه ها را تعیین میکند.
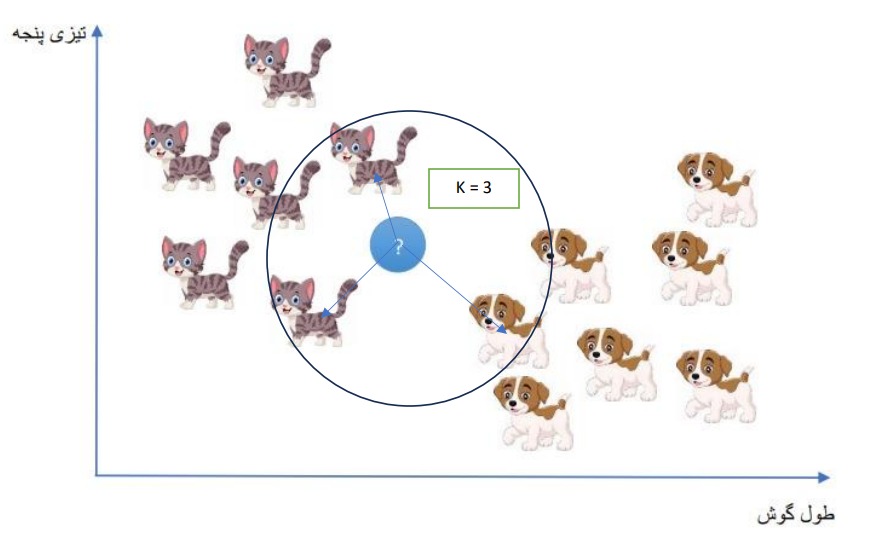
بیایید با یک مثال این الگوریتم را توضیح دهیم. فرض کنید مجموعه داده ای از گربه ها و سگ ها داریم که با دو ویژگی (تیزی پنجه و طول گوش) گربه یا سگ بودن آنها تشخیص داده میشود. یعنی مجموعه دادهی ما شامل دو کلاس گربه و سگ است.

حالا اگر طبق شکل زیر یک نمونه ی جدید داشته باشیم، گربه تشخیص داده میشود یا سگ؟

همانطور که قابل حدس است، نمونهی جدید با احتمال بالا گربه تشخیص داده میشود و مبنای این پیش بینی فاصلهی نمونهی جدید با دیگر دادهها است.
حالا دلیل این پیش بینی را بیان می کنیم. فرض کنید قرار است سه دادهی نزدیک به نمونهی جدید را پیدا کنیم یعنی تعداد همسایههای نمونهی جدید برابر 3 باشد. (k = 3)
آنگاه طبق شکل متوجه میشویم که دو داده از سه داده گربه است پس نتیجهی غالب گربه است و پیش بینی ما درست است. (در محاسبه فاصله، مراکز تصاویر اهمیت دارد.)
استفاده از فاصله اقلیدسی برای سنجش فاصله میان دادهها:
پرکاربردترین فاصله برای این الگوریتم، فاصله اقلیدسی (Euclidean Distance) است که با نامهای L2-Distance و L2-Norm نیز شناخته میشود که فرمول آن به صورت زیر است:
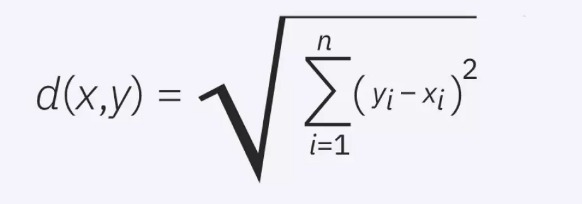
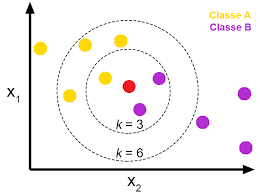
حالا طبق توضیحات داده شده پیش بینی کنید نمونهی جدید (دایره قرمز) در مجموعه داده زیر با توجه به مقدار k مطلق به کدام کلاس است؟
کاربرد الگوریتم در هوش مصنوعی:
الگوریتم KNN برای دسته بندی (classification) مجموعه دادهها به شدت کاربرد دارد. یعنی اگر چند کلاس مختلف داشته باشیم، قصد داریم بدانیم دادههای جدید ما در کدام یک از کلاس ها قرار میگیرند.
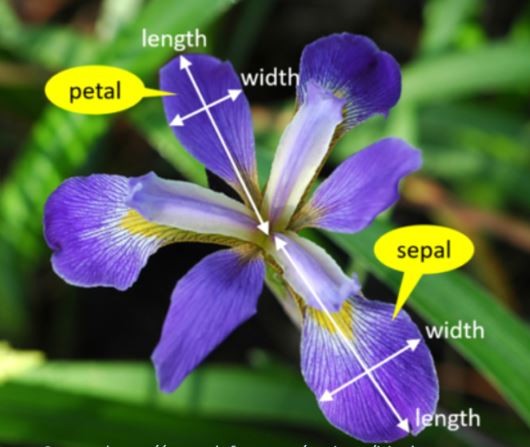
فرض کنید مسئله و نیاز ما این باشد که میخواهیم نوع گلی را تشخیص بدهیم و آن را منتسب به یکی از این سه دسته 'setosa' 'versicolor' 'virginica' کنیم.
برای انجام این کار قرار است مدلی طراحی کنیم که این نوع گلها را با توجه به ویژگیهایشان یاد بگیرد و در نهایت کلاس پیش بینی شده را به درستی بیان کند.
کدی برای حل این مسئله ارائه میدهیم و خط به خط آن را توضیح خواهیم داد.
در این بخش کتابخانههای مورد نیاز را تعریف کردیم.
import pandas as pd import numpy as np import mglearn # dont forget install mglearn (pip install mglearn)
باید مجموعه داده ای برای یادگیری مدلمان تهیه کنیم که با کد زیر و استفاده از مجموعه دادههای موجود در sklearn، مجموعه داده مورد نظر خود را بارگذاری میکنیم و آن را در متغیر iris_dataset قرار میدهیم.
حالا بیایید بیشتر با مجموعه داده iris_dataset آشنا شویم.
from sklearn.datasets import load_iris iris_dataset = load_iris()
این مجموعه داده از جنس دیکشنری میباشد که کلیدهای آن در نتیجه کد مشخص شده.
print("Keys of iris_dataset:n", iris_dataset.keys())Output:
Keys of iris_dataset: dict_keys(['data', 'target', 'target_names', 'DESCR', 'feature_names', 'filename'])
با اجرای کد زیر توضیحی در مورد این مجموعه داده، داده میشود.
print(iris_dataset['DESCR'][:193] + "n...")
Output:
.. _iris_dataset:
Iris plants dataset
--------------------
**Data Set Characteristics:**
:Number of Instances: 150 (50 in each of three classes)
:Number of Attributes: 4 numeric, pre
...همانطور که قبلا گفته شد قرار است سه دسته یا کلاس گل داشته باشیم که توسط این مجموعه داده تعیین شده است. که اسم کلاس ها را (Target names) را در نتیجه کد میبینیم:
print("Target names:", iris_dataset['target_names'])
Output:Target names: ['setosa' 'versicolor' 'virginica']حالا باید با ویژگی (features) گلها آشنا شویم. باید بدانیم براساس چه ویژگیهایی مدل ما قرار است یاد بگیرد تا گل جدیدی با مقادیری از همان ویژگی ها را پیش بینی کند.
print("Feature names:n", iris_dataset['feature_names'])
Output:Feature names: ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
با اجرای کد زیر نوع دیتاست ما مشخص میشود که یک numpy array است.
print("Type of data:", type(iris_dataset['data']))
Output:Type of data: <class 'numpy.ndarray'>برای ما اهمیت دارد که بدانیم دیتاست ما چه تعداد داده دارد. که با اجرای کد زیر تعداد نمونههای دادههای ما و تعداد ویژگیهایشان داده میشود.
print("Shape of data:", iris_dataset['data'].shapeOutput:150 تا نمونهی گل داریم که هر کدام 4 ویژگی دارند.Shape of data: (150, 4)حالا بیایید بیشتر با دیتاست آشنا شویم و 5 نمونهی اول آن را ببینیم:
print("First five rows of data:n", iris_dataset['data'][:5])Output:First five rows of data: [[5.1 3.5 1.4 0.2] [4.9 3. 1.4 0.2] [4.7 3.2 1.3 0.2] [4.6 3.1 1.5 0.2] [5. 3.6 1.4 0.2]]همانطور که انتظار میرود باید برچسبهای داده شده به نمونه دادههای ما نیز از جنس numpy array باشند و تعداشان نیز 150 تا باشد.
print("Type of target:", type(iris_dataset['target']))
print("Shape of target:", iris_dataset['target'].shape)Output:Type of target: <class 'numpy.ndarray'> Shape of target: (150,)همهی 150 تا برچسب را در نتیجه کد زیر می بینیم که طبق اعداد 0 و 1 و 2 مشخص میشود که یعنی سه کلاس داریم و مدل ما یکی از این سه عدد را به ازای ویژگیهای نمونه گل جدید خروجی خواهد داد.
print("Target:n", iris_dataset['target'])Output:Target: [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2]خب برای فهمیدن ادامهی کد نیاز است موضوع مهمی را توضیح دهیم.
سوال:
به نظر شما اگر همهی مجموعه داده را به مدل بدهیم که آموزش ببیند چطور میتوانیم عملکرد مدل را ارزیابی کنیم؟
اگر دوباره از دادههایی که آموزش دیده برای ارزیابی عملکرد استفاده کنیم، چه نتیجهای میبینیم؟
اگر از دادههای آموزشی برای ارزیابی استفاده کنیم، معمولا مدل به خوبی عمل خواهد کرد اما این نتیجه قابل اعتماد نیست. چرا که مدل در زمان آموزش به دادهها عادت کرده یا بهطوری آنها را حفظ کرده و با احتمال بالا بر روی آنها بیش از حد خوب عمل خواهد کرد که به دور از واقعیت است. برای اطمینان از عملکرد واقعی مدل، باید مجموعه داده را به دستهی دادههای آموزش و دادههای تست تقسیم کنیم. تا بتوانیم با استفاده از دادههای تست که مدل ما آنها را ندیده است، مدلمان را ارزیابی کنیم. که برای تحقق این امر از تابع زیر که در کتابخانه sklearn قرار دارد، استفاده خواهیم کرد:from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
iris_dataset['data'], iris_dataset['target'], random_state=0)حالا باید تعداد دادههای آموزش و دادههای تست را بدانیم:print("X_train shape:", X_train.shape)
print("y_train shape:", y_train.shape)Output:X_train shape: (112, 4) y_train shape: (112,)
print("X_test shape:", X_test.shape)
print("y_test shape:", y_test.shape)Output:X_test shape: (38, 4) y_test shape: (38,)حالا قبل از اینکه مدل را ایجاد کنیم بهتر است به مجموعه داد خود عمیقتر نگاه کنیم: این نمودارها پراکندگی کلاسها را براساس هر ویژگی نسبت به ویژگی دیگر بیان میکند.
# create dataframe from data in X_train
# label the columns using the strings in iris_dataset.feature_names
iris_dataframe = pd.DataFrame(X_train, columns=iris_dataset.feature_names)
# create a scatter matrix from the dataframe, color by y_train
pd.plotting.scatter_matrix(iris_dataframe, c=y_train, figsize=(15, 15), marker='o', hist_kwds={'bins': 20},
s=60, alpha=.8, cmap=mglearn.cm3)Output: حالا باید مدل خود را ایجاد کنیم. از مدل KNeighborsClassifier استفاده میکنیم که در کتابخانه sklearn وجود دارد. اسم مدل را knn میگذاریم:
حالا باید مدل خود را ایجاد کنیم. از مدل KNeighborsClassifier استفاده میکنیم که در کتابخانه sklearn وجود دارد. اسم مدل را knn میگذاریم: from sklearn.neighbors import KNeighborsClassifier knn = KNeighborsClassifier(n_neighbors=1)در مرحلهی بعد باید یادگیری مدل را شروع کنیم توسط تایع fit انجام میشود.
knn.fit(X_train, y_train)حالا که مدل ما یادگیری خود را تمام کرده، به آن یک دادهی جدید میدهیم که تا به الان ندیده است:باید دقت کنیم که تعداد ویژگی ها و ترتیب مقادیر آنها را درست وارد کنیم.
X_new = np.array([[5, 2.9, 1, 0.2]])
print("X_new.shape:", X_new.shape)Output:X_new.shape: (1, 4)حالا توسط فراخوانی تابع knn.predict پیش بینی را انجام میدهیم:که طبق نتیجه گل مورد نظر با ویژگی های داده شده مطلق به کلاس 0 است که نوع گل setosa میباشد.
prediction = knn.predict(X_new)
print("Prediction:", prediction)
print("Predicted target name:", iris_dataset['target_names'][prediction])Output:Prediction: [0] Predicted target name: ['setosa']کار به اینجا ختم نمیشود باید عملکرد مدل را ارزیابی کنیم و درصد دقت را بیان کنیم.ابتدا مقادیر دادههای آزمون را پیش بینی میکنیم:
y_pred = knn.predict(X_test)
print("Test set predictions:n", y_pred)Output:Test set predictions: [2 1 0 2 0 2 0 1 1 1 2 1 1 1 1 0 1 1 0 0 2 1 0 0 2 0 0 1 1 0 2 1 0 2 2 1 0 2]سپس میتوانیم به دو روش دقت را ارزیابی کنیم.روش اول این است که ابتدا باید مجموعه داده آزمون را پیش بینی کنیم و مقادیر پیش بینی شده را با مقادیر واقعی آنها مقایسه کنیم و تعداد باری که درست بوده است را بر تعداد دادههای آزمون تقسیم کنیم یا به نوعی میانگین میگیریم.که طبق نتیجه، به دقت 97 درصد میرسیم.
print("Test set score: {:.2f}".format(np.mean(y_pred == y_test)))
Output:Test set score: 0.97
روش دوم این است که از تابع آمادهی knn.score استفاده کنیم و دادههای آزمون را به همراه برچسبهایشان به این تابع بدهیم که ارزیابی را انجام دهد که باز هم به همان دقت 97 درصد خواهیم رسید.
print("Test set score: {:.2f}".format(knn.score(X_test, y_test)))
Output:Test set score: 0.97خلاصهی مهمی از این کد را در بخش زیر آورده ایم:
Summary and Outlook
X_train, X_test, y_train, y_test = train_test_split(
iris_dataset['data'], iris_dataset['target'], random_state=0)
knn = KNeighborsClassifier(n_neighbors=1)
knn.fit(X_train, y_train)
print("Test set score: {:.2f}".format(knn.score(X_test, y_test)))Output:Test set score: 0.97
به سوالات زیر پاسخ دهید.
1 - مزایای استفاده از مجموعه داده آزمون در ارزیابی عملکرد مدل KNN چیست؟
الف) به ما اجازه میدهد عملکرد واقعی مدل را بدون تأثیر دادن به دادههای آموزشی ارزیابی کنیم
ب) این دادهها عموماً پوشش کاملتری از فضای ویژگی را ارائه میدهند
ج) امکان اعتبارسنجی مدل در مقابل دادههای جدید را فراهم میکنند
د) تمرین کردن مدل را از پیش میگیرند و زمان بیشتری برای آموزش مدل فراهم میکنند.
2- چه تابعیت در کتابخانهی Scikit-Learn برای ایجاد مجموعههای داده آموزش و آزمون به صورت تصادفی وجود دارد؟
الف) train_test_split ب) create_data_split ج) random_data_split د) split_data
3- الگوریتم KNN برای کدامیک از مسائل زیر مناسب نیست؟
الف) تشخیص اسکناسهای تقلبی ب) پیشبینی قیمتهای مسکن
ج) تشخیص ایمیلهای اسپم د) طبقهبندی تصاویر
4- چگونه میتوان معیار عملکرد مدل KNN را ارزیابی کرد؟
الف) با استفاده از تابع predict
ب) با استفاده از تابع score
ج) با استفاده از تابع fit
د) با استفاده از تابع evaluate
5- الگوریتم KNN برای چه نوع مسائلی مورد استفاده قرار میگیرد؟
الف) رگرسیون ب) خوشهبندی ج) طبقه بندی د) نرمافزارهای مالی
پاسخ سوالات:1 - الف2- الف3- د4- ب5 - ج