Neural Networks

/*! elementor - v3.17.0 - 08-11-2023 */ .elementor-heading-title{padding:0;margin:0;line-height:1}.elementor-widget-heading .elementor-heading-title[class*=elementor-size-]>a{color:inherit;font-size:inherit;line-height:inherit}.elementor-widget-heading .elementor-heading-title.elementor-size-small{font-size:15px}.elementor-widget-heading .elementor-heading-title.elementor-size-medium{font-size:19px}.elementor-widget-heading .elementor-heading-title.elementor-size-large{font-size:29px}.elementor-widget-heading .elementor-heading-title.elementor-size-xl{font-size:39px}.elementor-widget-heading .elementor-heading-title.elementor-size-xxl{font-size:59px}
Neural Network
شکبه های عصبی از شبکه عصبی انسان الهام گرفته شده.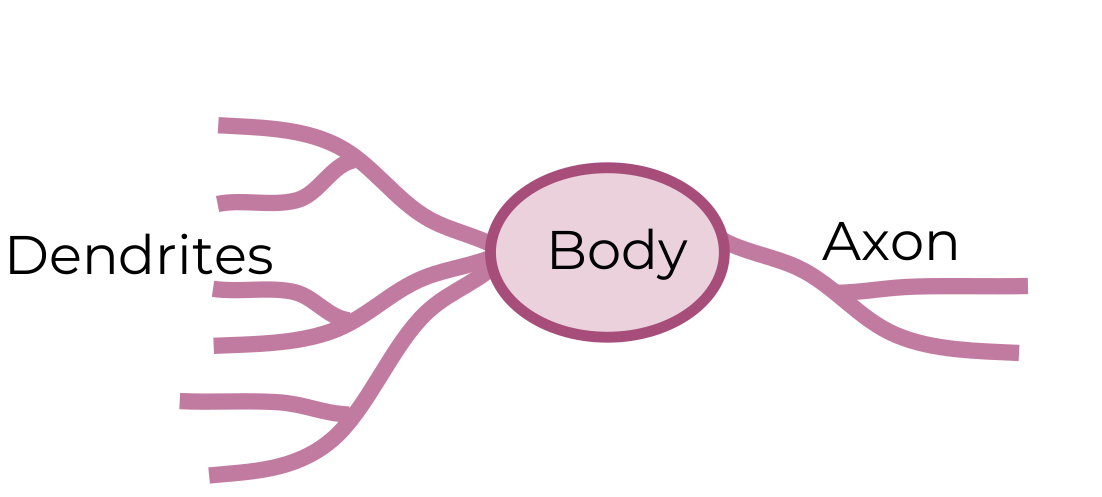 شکل بالا شکل ساده شده از شبکه عصبی انسان است که ورودی از طریق Dendrites وارد میشود و در Body بر روی ورودی عملیاتی انجام میدهد و در Axon خروجی میدهد.
در شکل زیر، شکل شبکه عصبی استفاده شده را نشان میدهد که شباهت زیادی با شبکه عصبی مغز انسان دارد
شکل بالا شکل ساده شده از شبکه عصبی انسان است که ورودی از طریق Dendrites وارد میشود و در Body بر روی ورودی عملیاتی انجام میدهد و در Axon خروجی میدهد.
در شکل زیر، شکل شبکه عصبی استفاده شده را نشان میدهد که شباهت زیادی با شبکه عصبی مغز انسان دارد
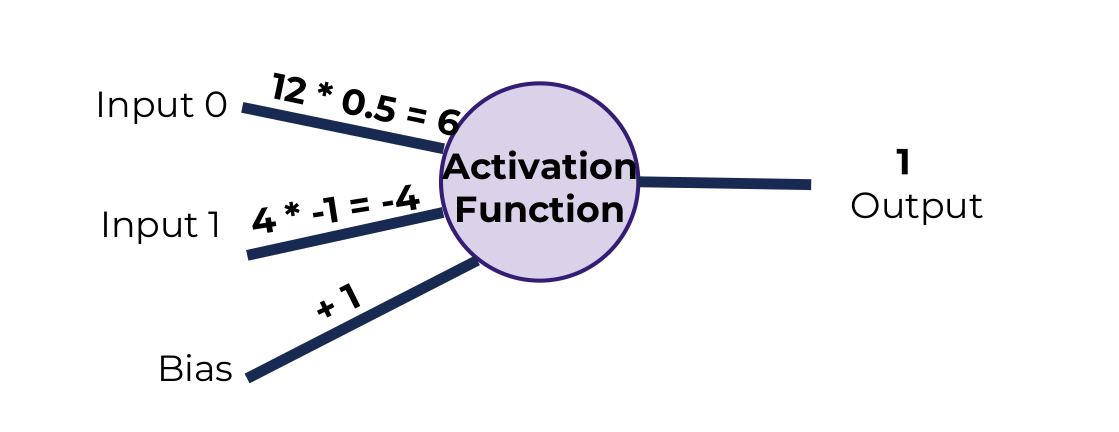 در این مثال دو ورودی وارد نورون شده. به هر ورودی یک ضریب اختصاص داده میشود و در نهایت با یک bias جمع میشود. رابطه زیر محاسبه یک نورون را نشان میدهد
در این مثال دو ورودی وارد نورون شده. به هر ورودی یک ضریب اختصاص داده میشود و در نهایت با یک bias جمع میشود. رابطه زیر محاسبه یک نورون را نشان میدهد
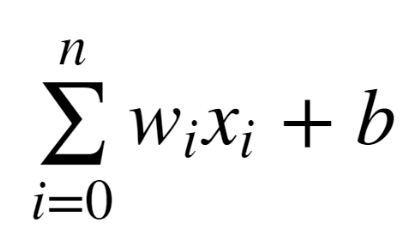 اگر bias وجود نداشته باشد، به ازای ورودی های صفر همیشه یک جواب داریم. پس bias را اضافه میکنیم تا به ازای ورودی های صفر جواب درست را بتوانیم بدست بیاوریم
اگر bias وجود نداشته باشد، به ازای ورودی های صفر همیشه یک جواب داریم. پس bias را اضافه میکنیم تا به ازای ورودی های صفر جواب درست را بتوانیم بدست بیاوریم
شبکه عصبی
شبکه های عصبی از چندین لایه بوجود می آید. هر لایه دارای چندین نورون است.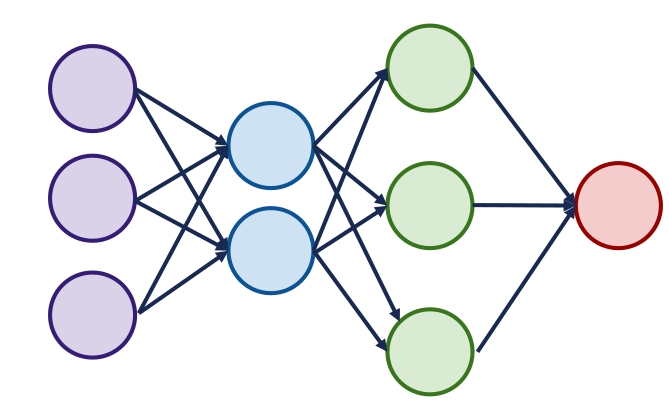 لایه اول نشان دهنده ورودی های شبکه عصبی و لایه آخر نشان دهنده خروجی شبکه عصبی است.
لایه های میانی نشان دهنده لایه های Hidden است. (دقت کنید که در این شبکه تمام نورون ها به یکدیگر متصل هستند).
لایه اول نشان دهنده ورودی های شبکه عصبی و لایه آخر نشان دهنده خروجی شبکه عصبی است.
لایه های میانی نشان دهنده لایه های Hidden است. (دقت کنید که در این شبکه تمام نورون ها به یکدیگر متصل هستند).
Activation Functions
تابع های فعالیت در پرسپترون ها محاسبه میشود. هدف این توابع این است که توابع خطی را به غیر خطی تبدیل کنیم (زیرا مسائل پیچیده را نمیتوان از طریق توابع خطی حل کرد). و دقت کنید که ترکیب توابع خطی همواره خطی است یعنی با توابع خطی در پرسپترون ها، هر چقدر هم لایه داشته باشیم، شبکه یک خط را یاد میگیرد. یکی از توابع غیر خطی و ساده ای که میتوان استفاده کرد این است که اگر جواب خطی کمتر از صفر شد 0 برگرداند و اگر بیشتر شد 1 برگرداند. ولی تغییرات کوچک در این تابع بسیار ساده منعکس نمیشود. شکل زیر نشان رنگ آبی نشان دهنده این تابع است و رنگ قرمز نشان دهنده تابع Sigmoid که تابع بهتری نسبت به آبی است و تغییرات کوچک را نیز نشان میدهد.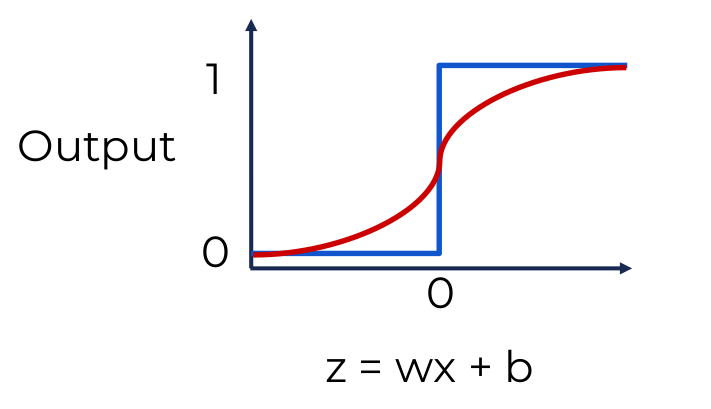 تابع Sigmoid به صورت ریاضیاتی به صورت زیر است
تابع Sigmoid به صورت ریاضیاتی به صورت زیر است
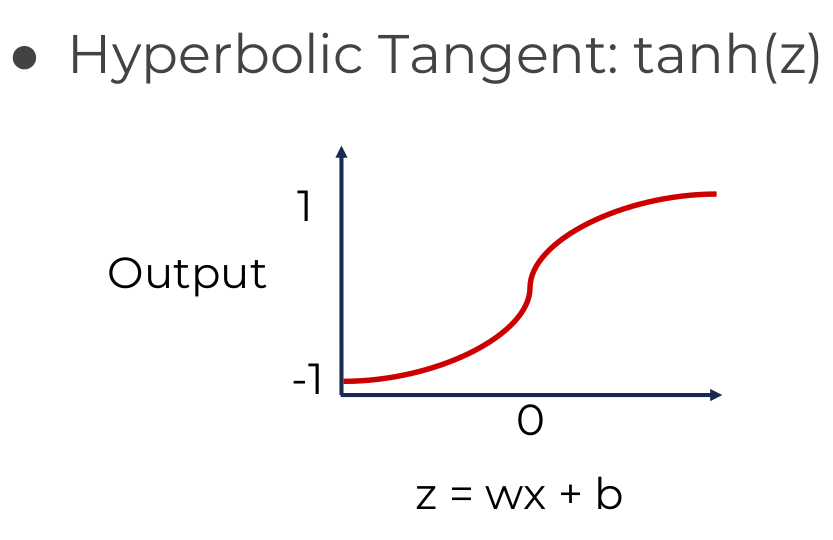
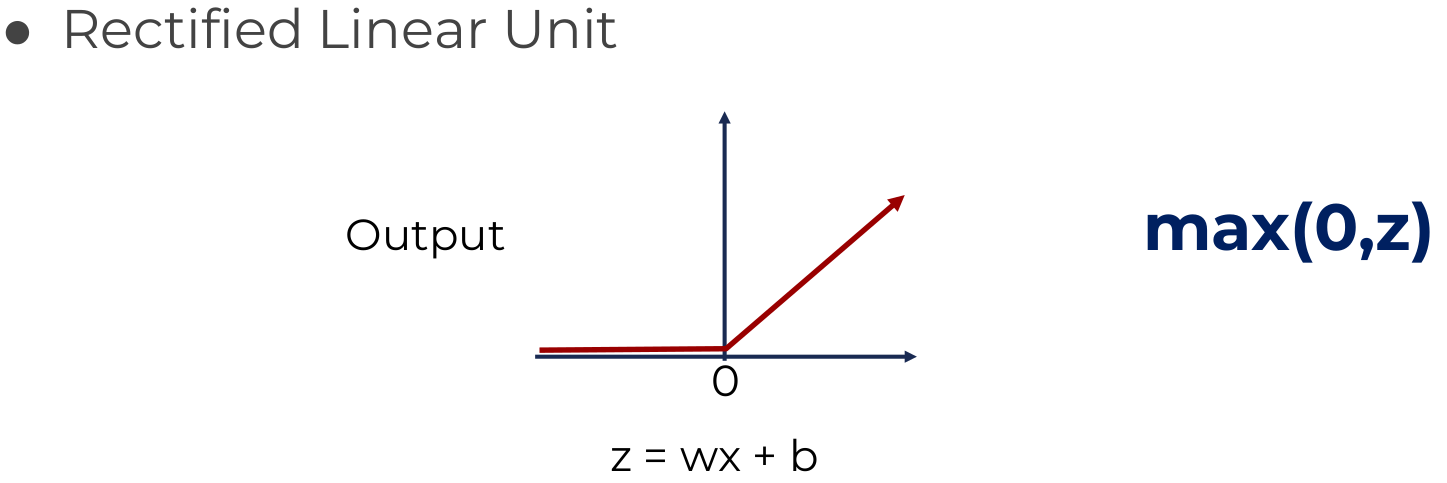
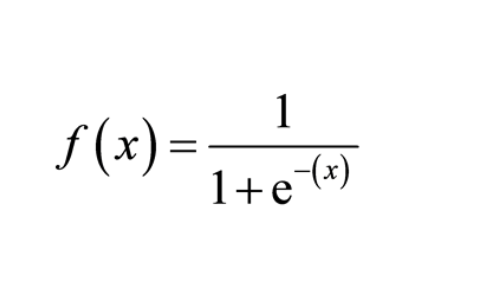 بسته به نیاز میتوان توابع فعالیت متفاوتی را استفاده کرد. توابع زیر مثالی از توابع فعالیت معروف هستند
بسته به نیاز میتوان توابع فعالیت متفاوتی را استفاده کرد. توابع زیر مثالی از توابع فعالیت معروف هستند
Cost Functions
تابع های هزینه نشان میدهند که مدل چه اندازه دقیق است و با استفاده از آن میتوان پارامترها را بروزرسانی کرد تا هزینه کمتری داشته باشید. در شکل بالا پیش بینی شبکه عصبی در لایه خروجی را نشان میدهد (احتمال اینکه خروجی مربوط به یک کلاس باشد) و جواب درست که Dog است. مسئله ای که پیش می آید این است که هزینه را چطور باید حساب کنیم.
دقت کنید که `Y نشان دهنده جواب درست و Y نشان دهنده پیش بینی است.
میتوان برای تابع هزینه میانگین اختلاف قدرمطلق جواب درست و پیش بینی را درنظر بگیریم.
یا برای اینکه خطاهای بزرگتر را برجسته کنیم میانگین مربع اختلاف آنها را به عنوان هزینه معرفی کنیم. ولی این تابع فرایند آموزش را کند میکند.
در شکل بالا پیش بینی شبکه عصبی در لایه خروجی را نشان میدهد (احتمال اینکه خروجی مربوط به یک کلاس باشد) و جواب درست که Dog است. مسئله ای که پیش می آید این است که هزینه را چطور باید حساب کنیم.
دقت کنید که `Y نشان دهنده جواب درست و Y نشان دهنده پیش بینی است.
میتوان برای تابع هزینه میانگین اختلاف قدرمطلق جواب درست و پیش بینی را درنظر بگیریم.
یا برای اینکه خطاهای بزرگتر را برجسته کنیم میانگین مربع اختلاف آنها را به عنوان هزینه معرفی کنیم. ولی این تابع فرایند آموزش را کند میکند.
Cross Entropy
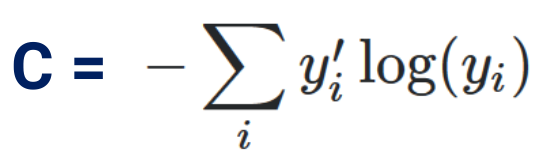 این تابع هزینه نسبت به MSE روند آموزش را تسریع میبخشد. و هرچه تفاوت زیادتر باشد شبکه سریع تر یاد میگیرد.
این تابع هزینه نسبت به MSE روند آموزش را تسریع میبخشد. و هرچه تفاوت زیادتر باشد شبکه سریع تر یاد میگیرد.
 در مثال بالا جواب درست کلاس ششم است پس هزینه آن برابر
در مثال بالا جواب درست کلاس ششم است پس هزینه آن برابر
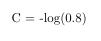
Gradient Descent and Backpropagation
الگوریتم گرادیان کاهشی، الگوریتم بهینه سازی برای یک تابع است. این الگوریتم برای پیدا کردن کمینه محلی استفاده میشود. رابطه زیر مقدار W را بروز میکند تا C بهینه شود.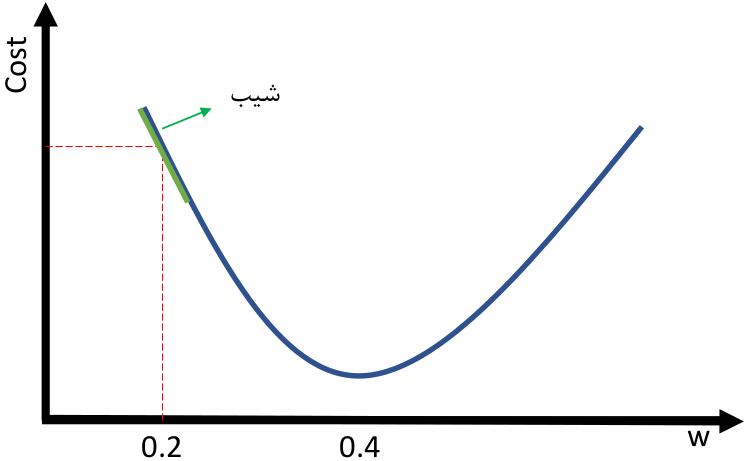 اگر w برابر 0.2 باشد و مقدار bهمواره صفر باشد، شیب خط منفی است. طبق رابطه بالا میتوانیم ببینیم که با زیاد کردن مقدار W به مقدار بهینه میرسیم و چون مقدار شیب منفی است با کم کردن آن از W مقدار W زیاد میشود.
اگر w برابر 0.2 باشد و مقدار bهمواره صفر باشد، شیب خط منفی است. طبق رابطه بالا میتوانیم ببینیم که با زیاد کردن مقدار W به مقدار بهینه میرسیم و چون مقدار شیب منفی است با کم کردن آن از W مقدار W زیاد میشود.
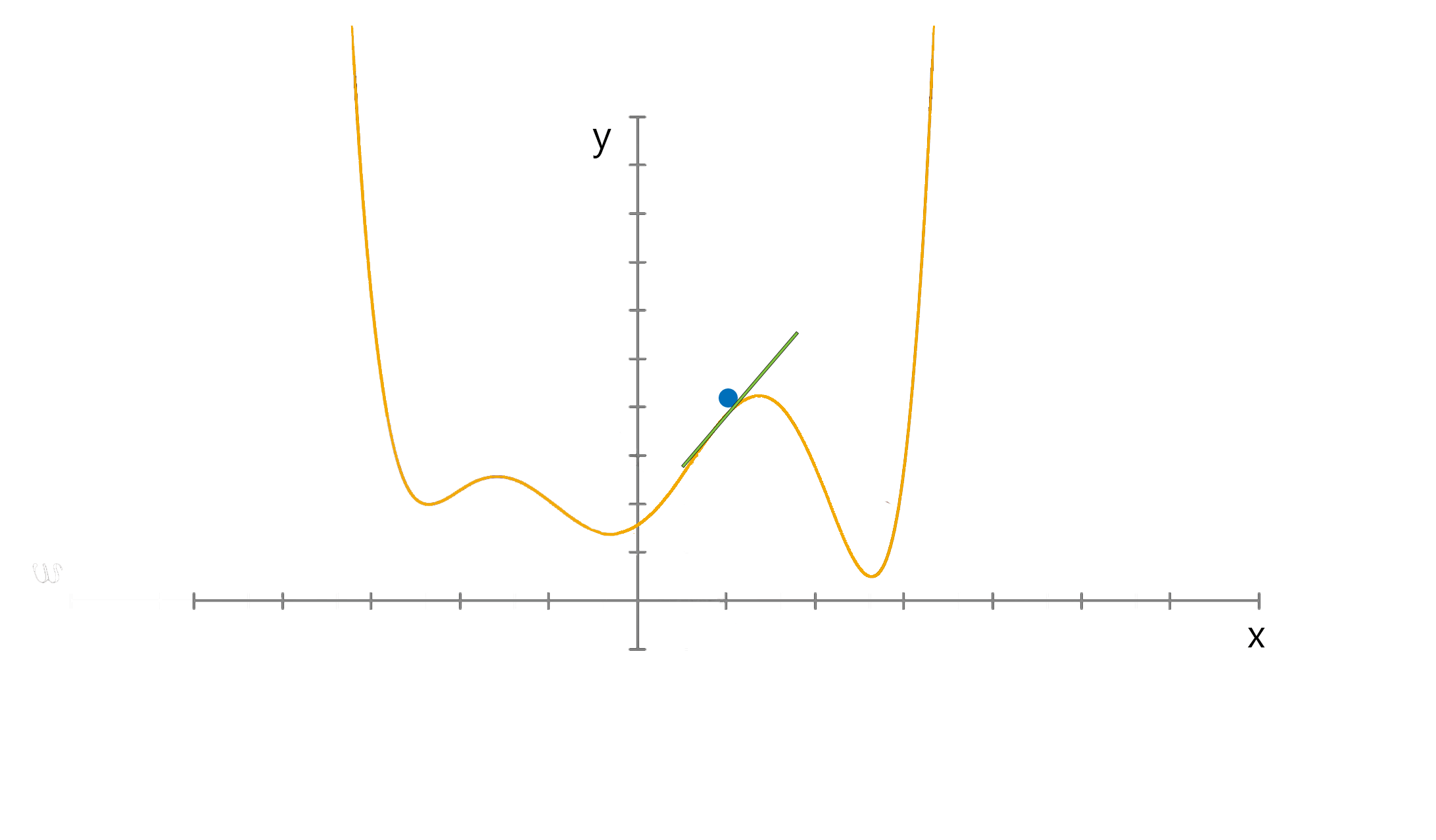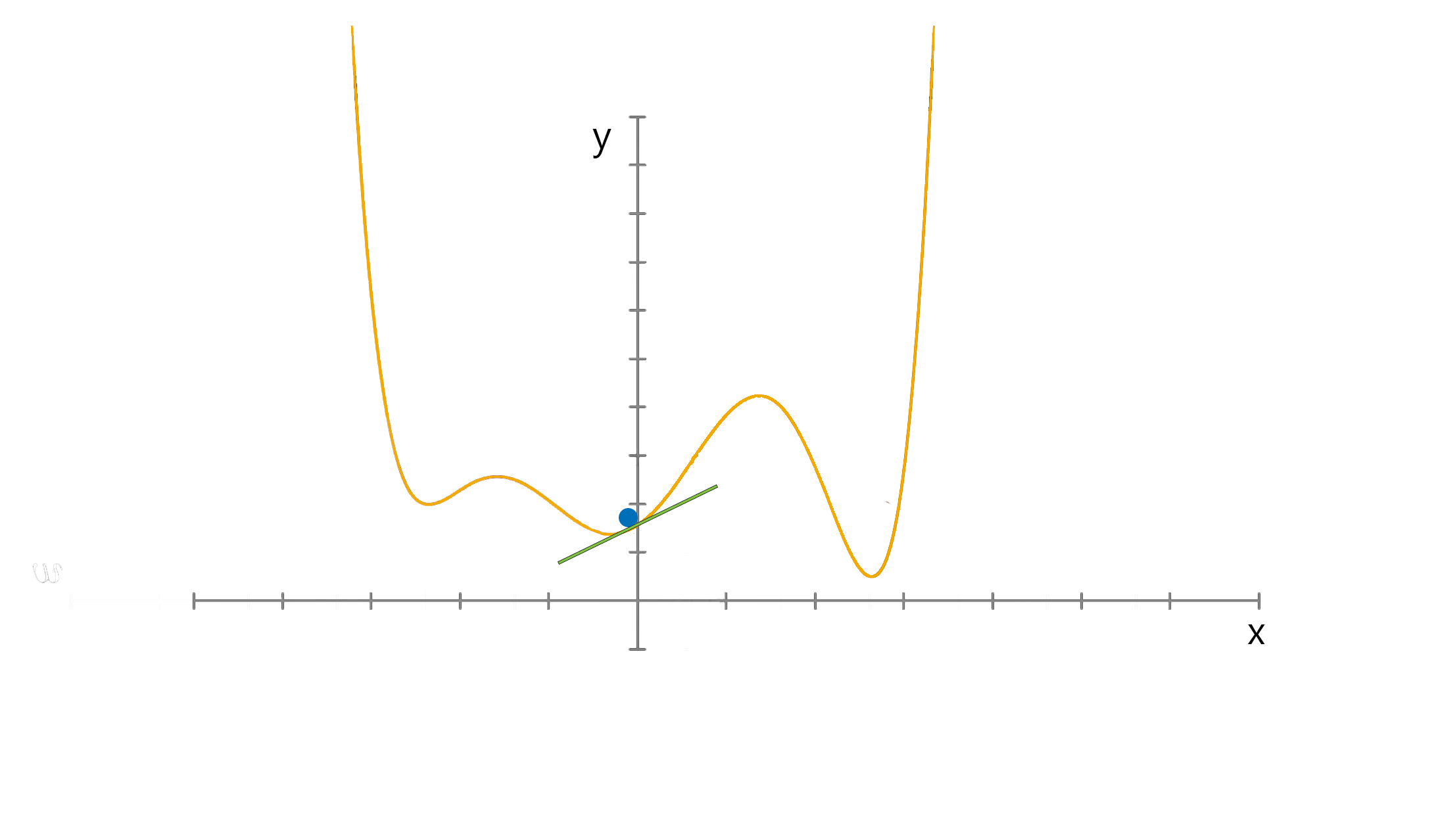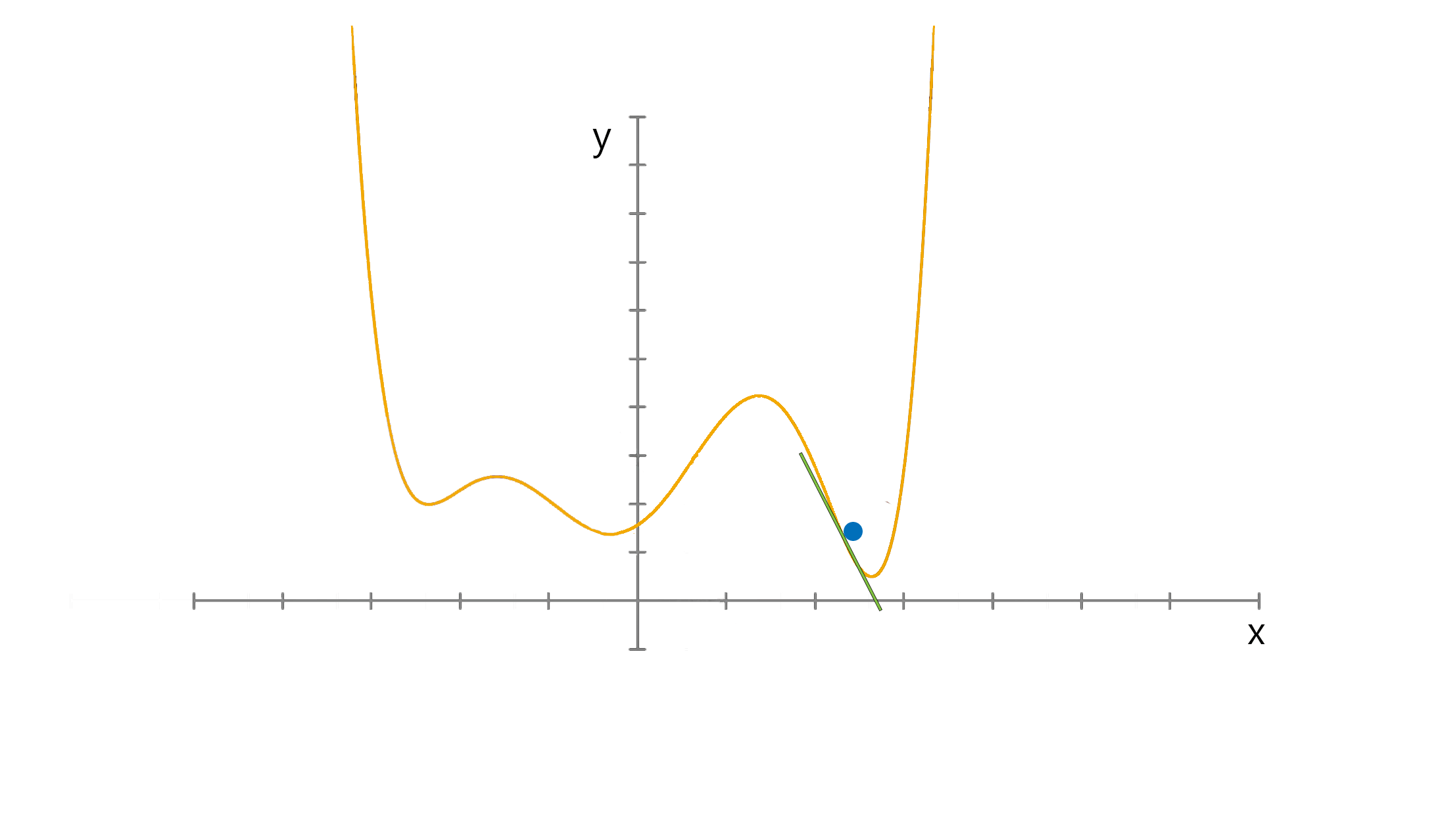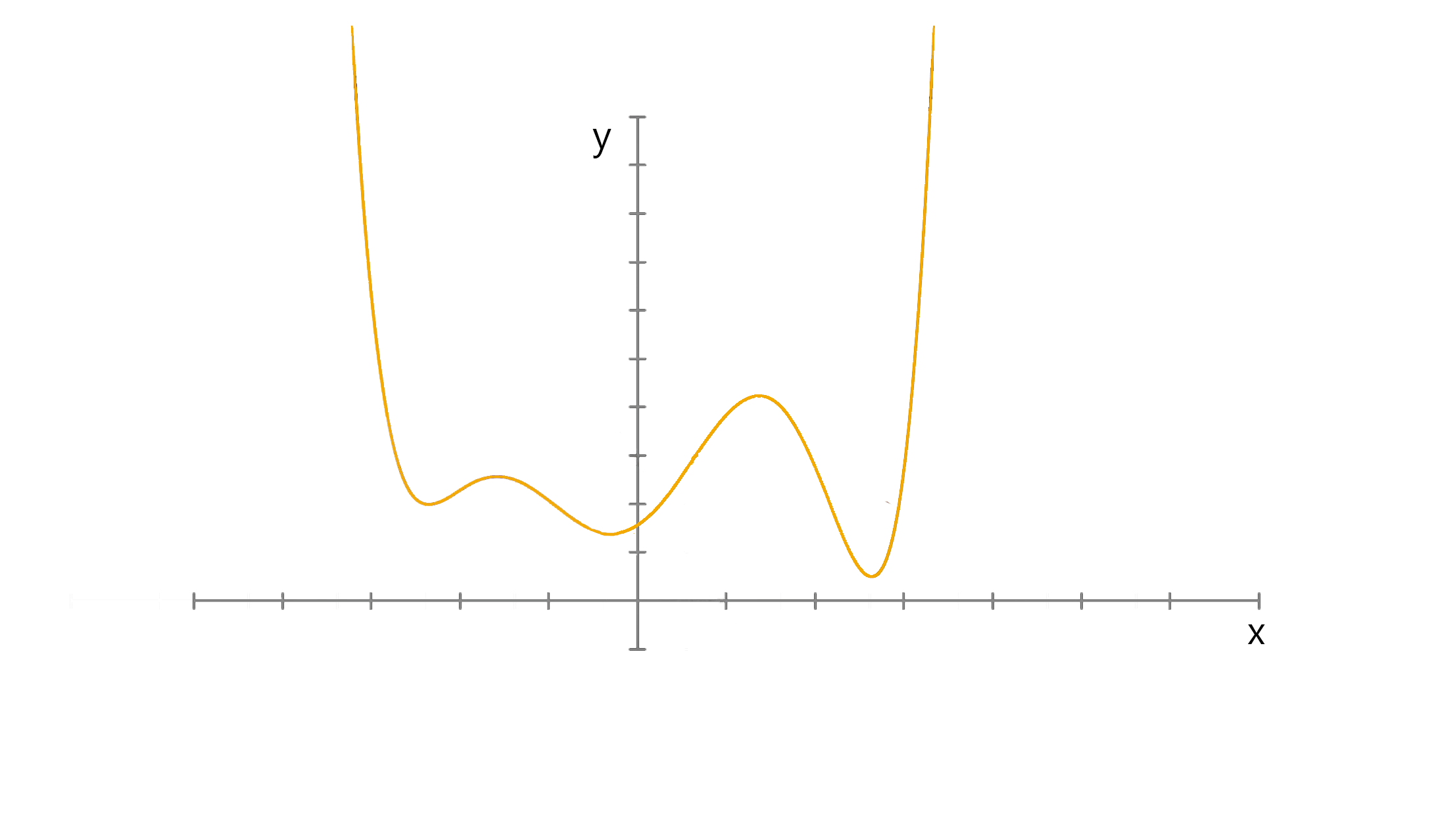 شکل بالا به خوبی الگوریتم را نشان میدهد.
Backpropagation مانند Gradient Descent عمل میکند اما چون شبکه عصبی دارای چندین لایه است باید از Chain Rule برای محاسبه گرادیان ها استفاده شود. یعنی برای بدست آوردن گرادیان یک لایه باید گرادیان لایه بالاتر آن را بدست آوردیم و با استفاده از آن گرادیان را حساب کنیم.
شکل بالا به خوبی الگوریتم را نشان میدهد.
Backpropagation مانند Gradient Descent عمل میکند اما چون شبکه عصبی دارای چندین لایه است باید از Chain Rule برای محاسبه گرادیان ها استفاده شود. یعنی برای بدست آوردن گرادیان یک لایه باید گرادیان لایه بالاتر آن را بدست آوردیم و با استفاده از آن گرادیان را حساب کنیم.
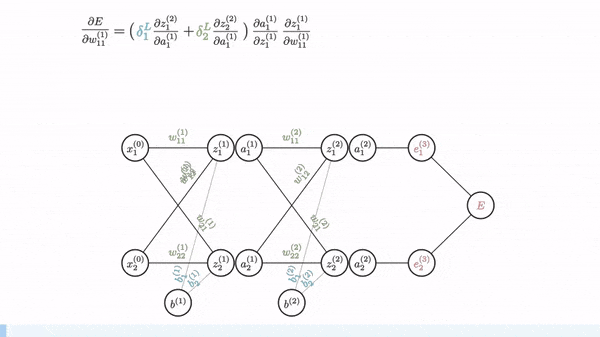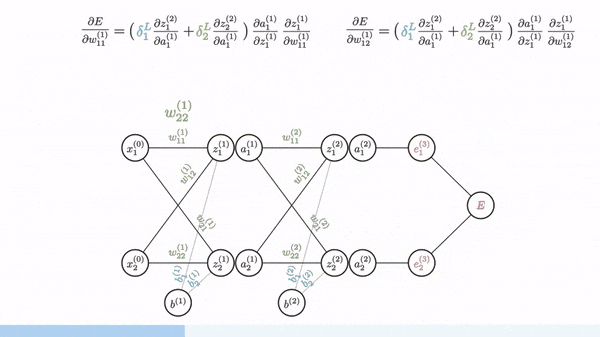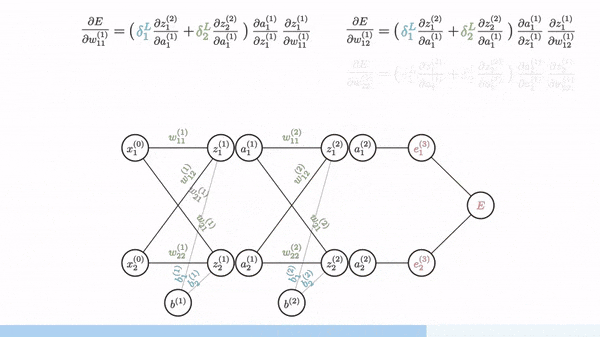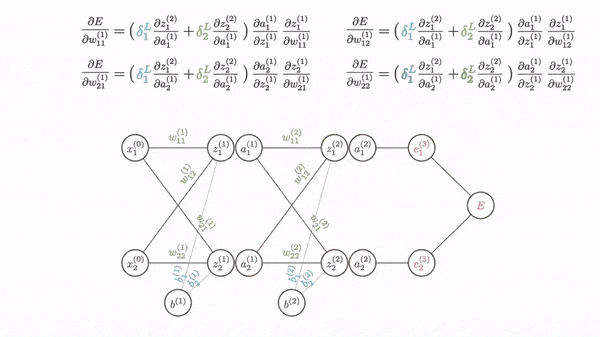
Vanishing Gradients
اگر به توابع sigmoid یا tanh توجه کنید وقتی حد آنها به سمت بینهایت (مثبت و منفی) میرود شیب آن نزدیک به صفر میشود و در بین آن شیب بیشتری وجود دارد. وقتی شبکه عصبی عمیق میشود گرادیان های کوچک و نزدیک به صفر در لایه های بالاتر با گرادیان های کوچک در لایه های پایین تر ضرب میشود (Chain rule) و گرادیان بسیار کوچکی به لایه های اولیه میرسد به همین دلیل مقدار بهینه بدست نمی آید. اما اگر به RELU دقت کنید شیب ۱ دارد (برای مقادیر بیشتر از صفر) و صفر برای مقادیر کمتر از صفر، به همین دلیل ما مقدار گرادیان نزدیک به صفر نداریم و این تابع فعالیت مشکل Vanishing Gradient را حل میکند.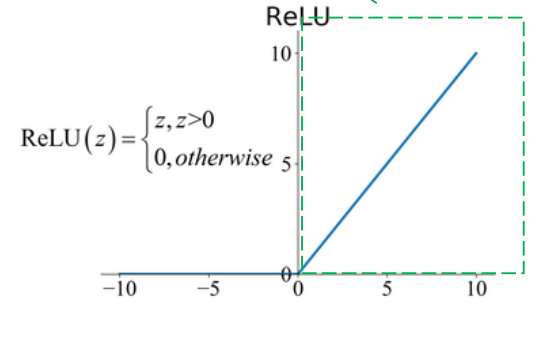
Learning Rate
گفتیم که Gradient Descent مقدار W را بروز میکند تا C بهینه شود و این کار را به صورت کم کردن شیب خط از W انجام میدادیم. ولی این کم کردن ممکن است باعث شود که W از مقدار بهینه رد شود و حتی Diverge شود. برای اینکه قدم های کوتاه تر برداریم تا به مقدار بهینه برسیم میتوانیم ضریبی برای شیب خط تعیین کنیم. رابطه زیر نشان میدهد:- میتوانیم ابتدا Learning Rate را زیاد درنظر بگیریم تا سریع به اطراف مقدار بهینه برسیم و بعد قدم ها را کوتاه تر کنیم
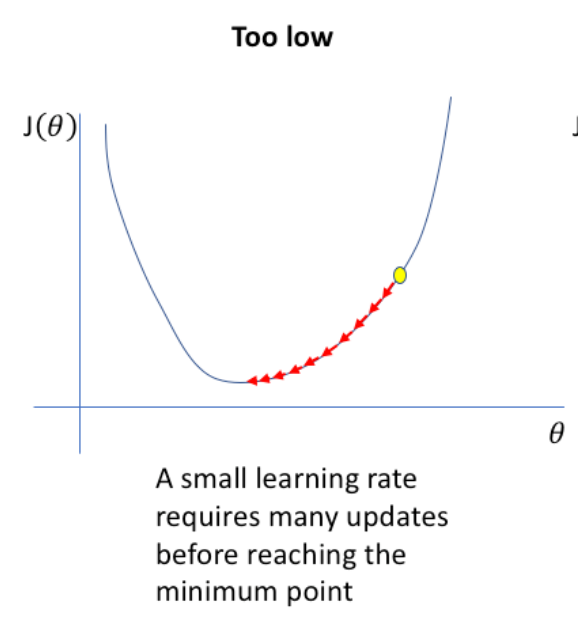 و اگر مقدار Learning Rate را زیاد درنظر بگیریم ممکن است مقدار Cost نه تنها کم نشود بلکه زیاد هم بشود (Divergence)
و اگر مقدار Learning Rate را زیاد درنظر بگیریم ممکن است مقدار Cost نه تنها کم نشود بلکه زیاد هم بشود (Divergence)
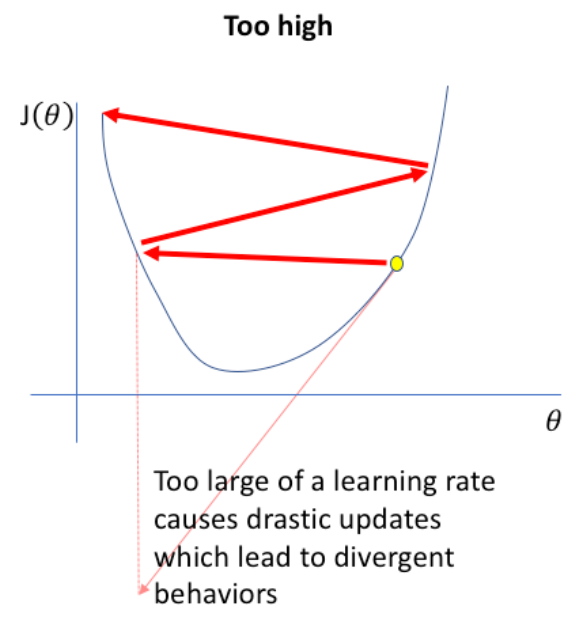 سوال۱) یک شبکه عصبی با شش لایه و تمامی لایه ها تابع فعالیت Sigmoid دارند را درنظر بگیرید. هنگام ترین با این مشکل مواجه میشویم که Cost کم نمیشود. راه حل چیست؟
الف) تعداد داده ها را زیاد کنیم
ب) تابع فعالیت را در لایه های Hidden به ReLU تغییر دهیم
ج) میتوانیم از Augmentation استفاده کنیم یا Dropout به لایه ها اضافه کنیم
د) شبکه پیچیده تر با لایه های بیشتر احتمالا میتواند بهتر عمل کند و Cost را کمتر کند
جواب گزینه (ب) است: در اینجا ما مشکل Vanishing Gradient داریم و ReLU این مشکل را حل میکند
سوال ۲) هنگام ترین یک شبکه عصبی مشاهده میشود که Cost بیشتر میشود. ممکن است چه دلیلی داشته باشد؟
الف) ممکن است Learning Rate بسیار کم باشد و باعث مشکل Vanishing Gradient شود
ب) ممکن است Learning Rate زیاد باشد و باعث شود W و b زیاد تغییر کنند و Overshoot شوند
ج) ممکن است از softmax در لایه های میانی استفاده شده باشد و Vanishing Gradient داشته باشیم
د) ممکن است تعداد لایه ها آنقدر کم باشد که مشکل Exploding Gradients داشته باشم
گزینه (ب) درست است: گفتیم که اگر مقدار Learning Rate زیاد باشد باعث Divergence میشود. گزینه (د) نیز میتوانست درست باشد اگر میگفت تعداد لایه ها آنقدر زیاد باشد.
سوال ۳) کدام گزینه درست است؟
الف) در الگوریتم Gradient Descent مقدار پارامترها برابر مقدار پارامترها به اضافه مشتق آن در Learning Rate
ب) الگوریتم Gradient Descent الگوریتم بهینه سازی است و منجر به Global minimum میشود
ج) الگوریتم Gradient Descent ممکن است به مقدار کمینه محلی برسد
د) در Gradient Descent از Chain Rule استفاده میکنیم
گزینه (ج) درست است: گفتیم که Gradient Descent الگوریتمی برای پیدا کردن مقدار مینیمم محلی برای یک تابع استفاده میشود
سوال ۴) اگر دو کلاس داشته باشیم و یکی از داده های کلاس اول را به شبکه عصبی بدهیم و خروجی آن به ترتیب کلاس 0.3 و 0.7 باشد مقدار Cross Entropy را بدست آورید
الف) 0.522
ب) 0.154
ج) 0.7
د) 0.3
گزینه (الف) درست است: منفی لگاریتم 0.3 برابر 0.522 است
سوال 5: چرا tanh باعث Vanishing Gradient میشود؟
الف) چونکه tanh تابع ساده ای دارد
ب) مشتق tanh همواره نزدیک به صفر است
ج) مقادیر tanh همواره نزدیک به صفر است
د) مشتق tanh گاها نزدیک به صفراست
گزینه (د) درست است: مشتق tanh در حد بینهایت به صفر میل میکند ولی در نزدیکی ۰ مقدار زیادی دارد.
سوال۱) یک شبکه عصبی با شش لایه و تمامی لایه ها تابع فعالیت Sigmoid دارند را درنظر بگیرید. هنگام ترین با این مشکل مواجه میشویم که Cost کم نمیشود. راه حل چیست؟
الف) تعداد داده ها را زیاد کنیم
ب) تابع فعالیت را در لایه های Hidden به ReLU تغییر دهیم
ج) میتوانیم از Augmentation استفاده کنیم یا Dropout به لایه ها اضافه کنیم
د) شبکه پیچیده تر با لایه های بیشتر احتمالا میتواند بهتر عمل کند و Cost را کمتر کند
جواب گزینه (ب) است: در اینجا ما مشکل Vanishing Gradient داریم و ReLU این مشکل را حل میکند
سوال ۲) هنگام ترین یک شبکه عصبی مشاهده میشود که Cost بیشتر میشود. ممکن است چه دلیلی داشته باشد؟
الف) ممکن است Learning Rate بسیار کم باشد و باعث مشکل Vanishing Gradient شود
ب) ممکن است Learning Rate زیاد باشد و باعث شود W و b زیاد تغییر کنند و Overshoot شوند
ج) ممکن است از softmax در لایه های میانی استفاده شده باشد و Vanishing Gradient داشته باشیم
د) ممکن است تعداد لایه ها آنقدر کم باشد که مشکل Exploding Gradients داشته باشم
گزینه (ب) درست است: گفتیم که اگر مقدار Learning Rate زیاد باشد باعث Divergence میشود. گزینه (د) نیز میتوانست درست باشد اگر میگفت تعداد لایه ها آنقدر زیاد باشد.
سوال ۳) کدام گزینه درست است؟
الف) در الگوریتم Gradient Descent مقدار پارامترها برابر مقدار پارامترها به اضافه مشتق آن در Learning Rate
ب) الگوریتم Gradient Descent الگوریتم بهینه سازی است و منجر به Global minimum میشود
ج) الگوریتم Gradient Descent ممکن است به مقدار کمینه محلی برسد
د) در Gradient Descent از Chain Rule استفاده میکنیم
گزینه (ج) درست است: گفتیم که Gradient Descent الگوریتمی برای پیدا کردن مقدار مینیمم محلی برای یک تابع استفاده میشود
سوال ۴) اگر دو کلاس داشته باشیم و یکی از داده های کلاس اول را به شبکه عصبی بدهیم و خروجی آن به ترتیب کلاس 0.3 و 0.7 باشد مقدار Cross Entropy را بدست آورید
الف) 0.522
ب) 0.154
ج) 0.7
د) 0.3
گزینه (الف) درست است: منفی لگاریتم 0.3 برابر 0.522 است
سوال 5: چرا tanh باعث Vanishing Gradient میشود؟
الف) چونکه tanh تابع ساده ای دارد
ب) مشتق tanh همواره نزدیک به صفر است
ج) مقادیر tanh همواره نزدیک به صفر است
د) مشتق tanh گاها نزدیک به صفراست
گزینه (د) درست است: مشتق tanh در حد بینهایت به صفر میل میکند ولی در نزدیکی ۰ مقدار زیادی دارد.