مقدمات شبکه های عصبی کانولوشنالی و واحد های کانولوشن و پولینگ و سلسله مراتبشون

یادآوری:
چرا باید ازconvolutional neural networksاستفاده کنیم :
- تعداد پارامترها به مقدار قابل توجهی کاهش میابد.
- نگاه کلی نگرانه ندارد؛مفاهیمی از نظیر special informationرا برایمان استخراج میکند.
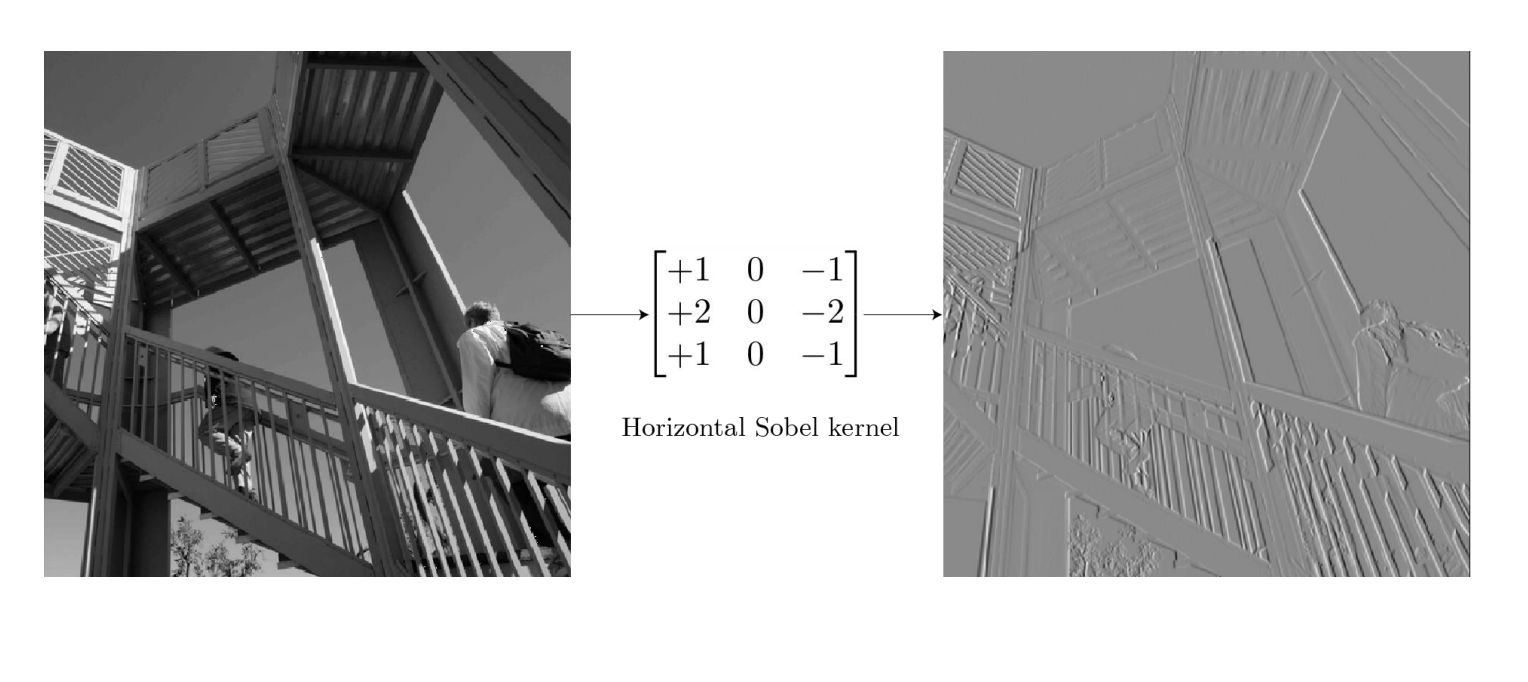 نکته :
نکته :
- فیلتر کانولوشن باید از جایی شروع بشه که هیچ قسمتی از آن بیرون از عکس نزند، به طور کلی یعنی فقط عکس را دربربگیرد.
- مشخص کردن سایز فیلتر کانولوشن دست خودمان است.
- فیلترها بر اساس مقداری که بهشون میدیم کارهای مشخصی انجام می دهند.
(لایه های تماما متصل)Dense layers: به دنبال global patterns
نکته ی دیگری که باید به آن توجه کرد این است که در اینجا مفهومی به نام weight sharing داریم، یعنی مقدار فیلتر تغییر نمیکند و اون وزنها روی کل تصویر ما قرار میگیرد.(روی کل دیتای ماshareمی شود.) hierarchies of patterns یا سلسله مراتبی از فیچرها : نگاه لایه لایه بجای نگاه کلی نگرانه ، در لایه های اول به دنبال چیزهای ساده میگردیم در حد یک خط یا یک لبه درواقع پترن های ساده را می یابیم.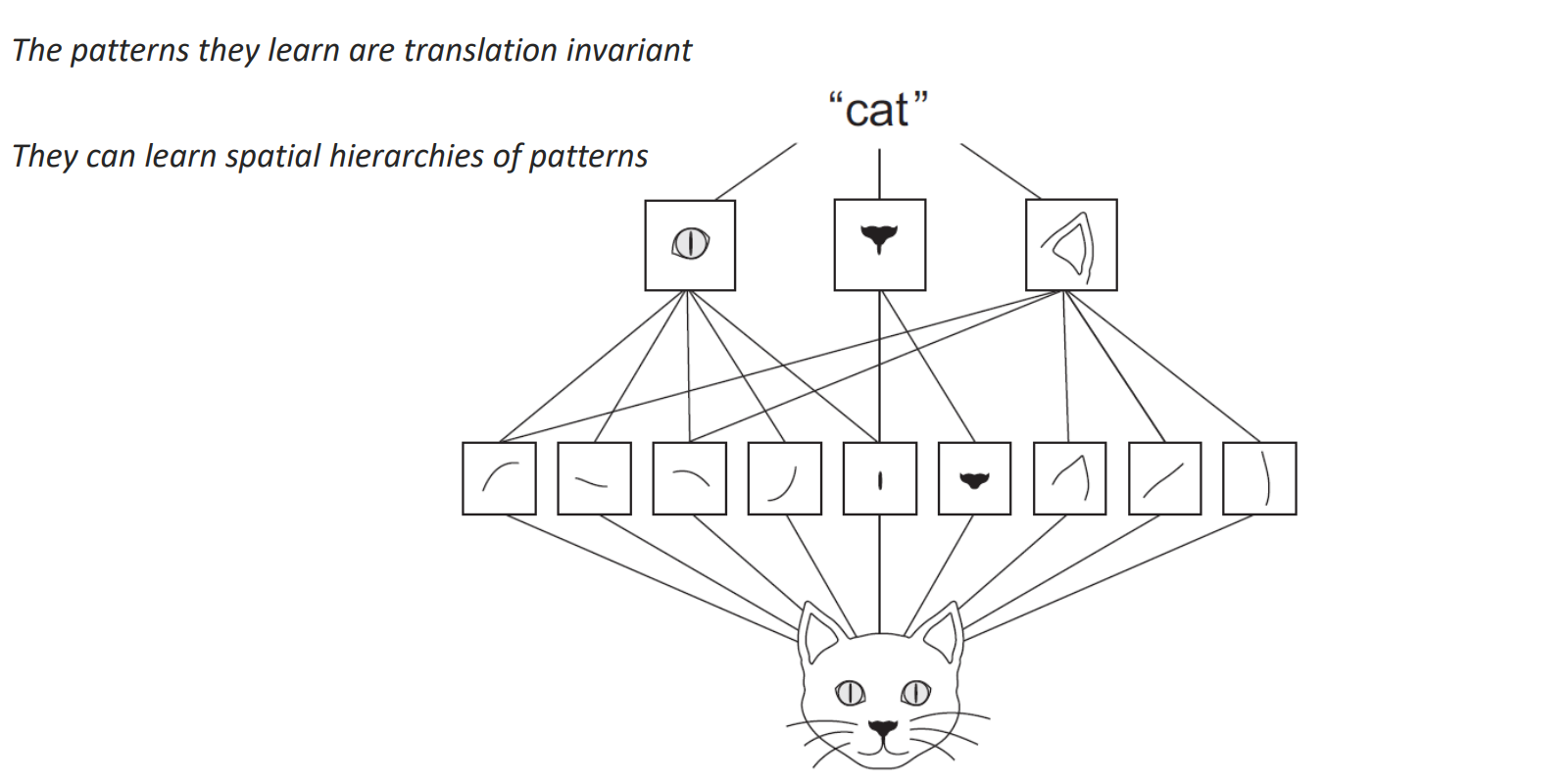 به ازای runکردن هرفیلتر یک کانال خوهیم داشت؛ به تعداد فیلترهامون کانال خوهیم داشت درنهایت(از تصویر اصلی کوچک تر است).لایه ی بعدی این کانال هارا به عنوان ورودی می بیند نه دیتای اولیه را، لایه ی بعدی به صورت عمقی روی کل این کانال ها قرار می گیرد.
درواقع در این روش : 1- حل به صورت سلسله مراتبی 2- نگاه local
این دو مفهوم translation invarianceرا به وجود می آورند؛ به این مفهوم که نسبت به جا به جایی مقاوم است یا به طور ساده تر باید گفت که جا به جایی های کوچک برای ان اهمیت ندارد.
به طور خلاصه : هرفیلتر یک pattern پیدا میکند مثلا اگر ما عکس یک گربه را به یک شبکه کانولوشنی بدهیم خروجی لایه ی اول می تواند چند کانال باشد که هرکدام یک pattern دیده اند مثلا یک خط صاف ، یک خط کج ، زاویه و....
لایه های بعد تر که روی کانال ها انجام می شود درواقع یک عددی را برمیگردانند به این معنی که pattern مورد نظر را دیده اند.
همه ی لایه ها کانولوشن است در شبکه های عصبی کانولوشنی اما ،لایه ی اول کانولوشن روی تصویراست و برای ما قابل درک است اما لایه های بعدی برای ما غیرقابل درک است به همین دلیل هم هست که کانولوشن را به بلک باکس تشبیه می کنند.
استفاده از لایه های کانولوشن مشکلات خودش را دارد که در ادامه به آنها و راهکاربرطرف کردن آنها می پردازیم.
به ازای runکردن هرفیلتر یک کانال خوهیم داشت؛ به تعداد فیلترهامون کانال خوهیم داشت درنهایت(از تصویر اصلی کوچک تر است).لایه ی بعدی این کانال هارا به عنوان ورودی می بیند نه دیتای اولیه را، لایه ی بعدی به صورت عمقی روی کل این کانال ها قرار می گیرد.
درواقع در این روش : 1- حل به صورت سلسله مراتبی 2- نگاه local
این دو مفهوم translation invarianceرا به وجود می آورند؛ به این مفهوم که نسبت به جا به جایی مقاوم است یا به طور ساده تر باید گفت که جا به جایی های کوچک برای ان اهمیت ندارد.
به طور خلاصه : هرفیلتر یک pattern پیدا میکند مثلا اگر ما عکس یک گربه را به یک شبکه کانولوشنی بدهیم خروجی لایه ی اول می تواند چند کانال باشد که هرکدام یک pattern دیده اند مثلا یک خط صاف ، یک خط کج ، زاویه و....
لایه های بعد تر که روی کانال ها انجام می شود درواقع یک عددی را برمیگردانند به این معنی که pattern مورد نظر را دیده اند.
همه ی لایه ها کانولوشن است در شبکه های عصبی کانولوشنی اما ،لایه ی اول کانولوشن روی تصویراست و برای ما قابل درک است اما لایه های بعدی برای ما غیرقابل درک است به همین دلیل هم هست که کانولوشن را به بلک باکس تشبیه می کنند.
استفاده از لایه های کانولوشن مشکلات خودش را دارد که در ادامه به آنها و راهکاربرطرف کردن آنها می پردازیم.
مشکلات کانولوشن :
- لبه ها به اندازه پیکسل های درونی در کانولوشن شرکت نمی کنند.(پیکسل های میانی(خونه های وسط)بیشتر تاثیر می گذارند.
- خروجی کوچک می شود.(ناخواسته عکس را کوچک می کند و شبکه عصبی ما می تواند تعداد محدودی لایه داشته باشد.)
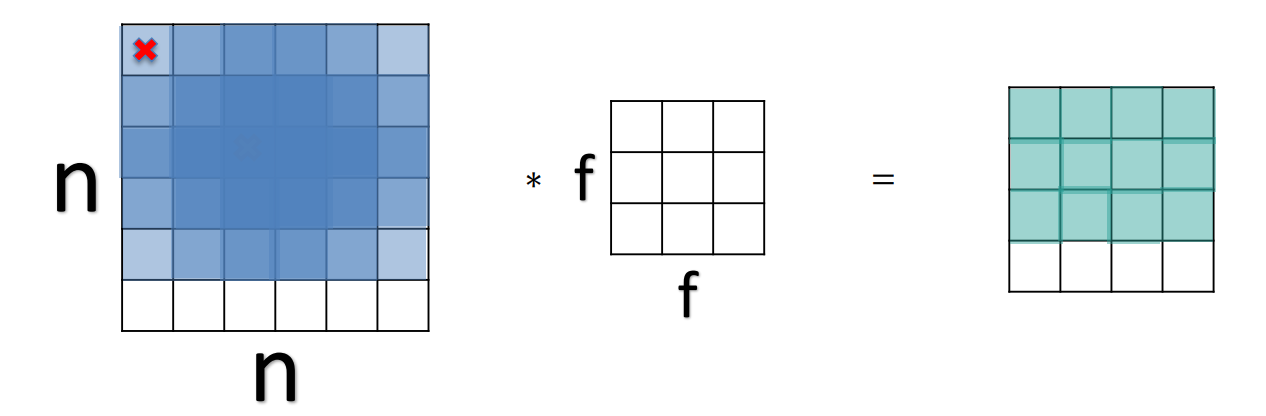 سایز نهایی تصویر بعد از قرار گرفتن فیلتر روی عکس از فرمول زیر بدست می آید :
سایز نهایی تصویر بعد از قرار گرفتن فیلتر روی عکس از فرمول زیر بدست می آید :
n-f+1 (n : سایز اولیه ی تصویرf, : سایز فیلتر)
- نکته: کوچک تر بودن فیلتر باعث میشود توجه به جزئیات بیشتر شود.
راهکار : استفاده از padding
بعضی مواقع نوع padding استفاده شده برای ما اهمیت زیادی دارد چون استفاده از padding نامناسب میتواند عکس را خراب کند؛ اما در classification وسواس به خرج نمی دهیم و معمولا از zero padding استفاده می کنیم.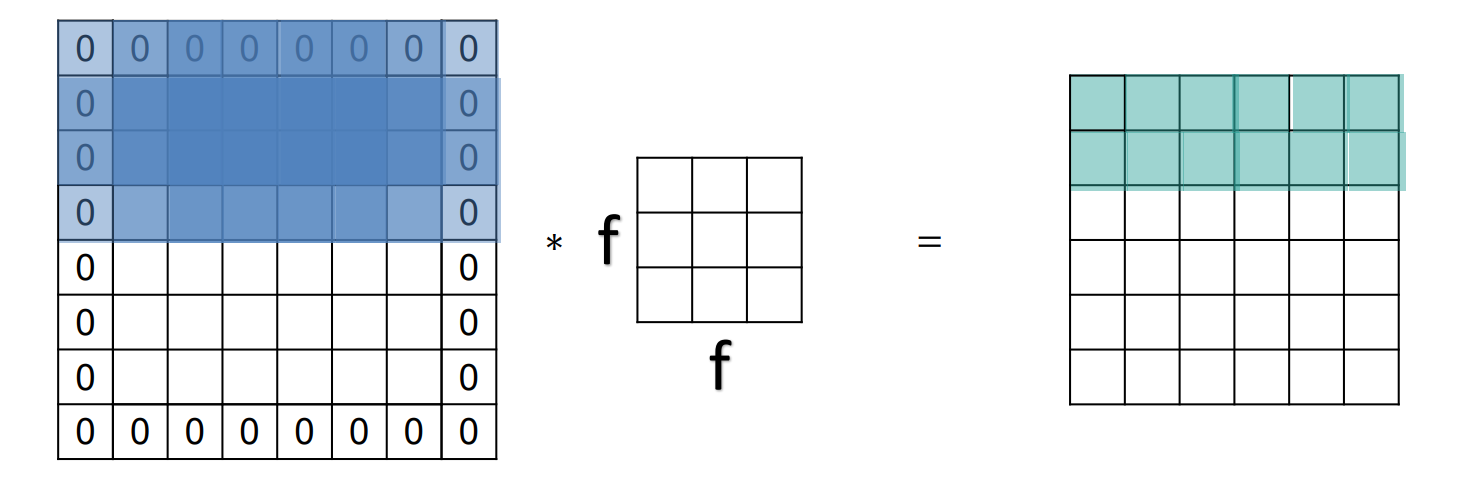
- نکته : بعد از اعمال فیلتر بر روی عکس padding دار سایز خروجی نهایی همان سایز ورودی قبل از اعمال فیلتر و بدون padding است.
P = (f-1)/2
بعضی از فریم ورک ها نظیر TensorFlow و Keras خودشون سایز padding موردنیاز را برای حساب می کنند. درواقع به اینصورت که یا باید padding بدهیم آنقدری که سایز عکس تغییر نکند ، یا مانند قبل padding ندهیم تا سایز عکس تغییر کند.عملگرهای کانولوشن مرتبط با padding :
- Valid : padding نده تا عکس کوچک بشود.
- Same : به اندازه مورد نیاز padding بده تا تصویر کوچک نشود.
Stride در کانولوشن :
به معنی گام است در لغت ، به این مفهوم که گام حرکت و پرش فیلتر روی تصویر را مشخص میکند. باعث می شود مقداری از داده های ما از دست برود.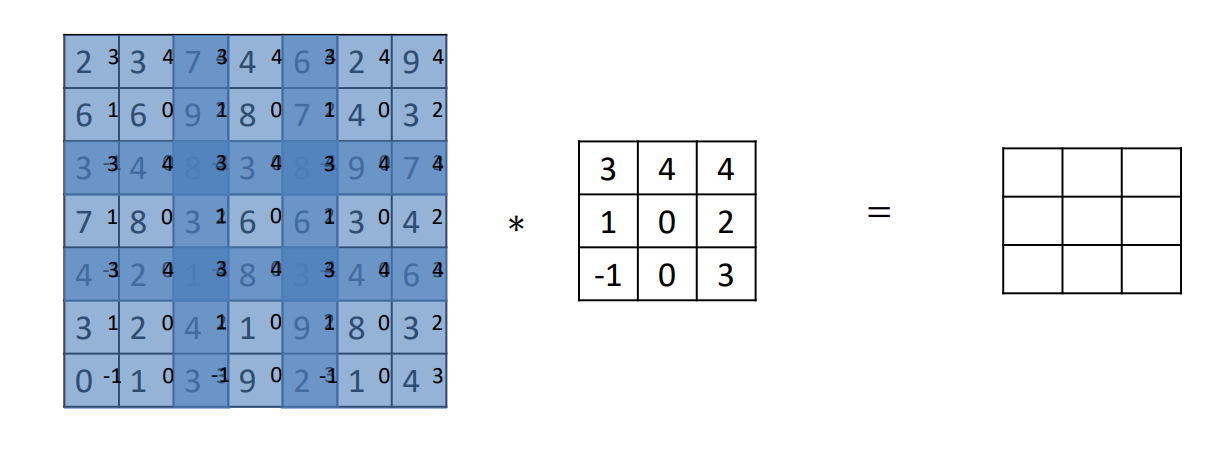
هرچه stride کمتر باشد :
- بارمحاسبات کمتر
- عکس کوچک می شود
انواع stride :
- با همپوشانی
- بدون همپوشانی (روی مرز ها قرار نمیگرد)
مطالعه آزاد : how vectorize kernel
کانولوشن روی عکس های رنگی (RGB):
به ازای هر کانال رنگی یک فیلتر خواهیم داشت؛برای R یک فیلتر،برای G یک فیلتر،برایB یک فیلتر و درمجموع سه فیلتر و سه سایز خوهیم داشت؛که در نهایت سهactivation map خواهیم داشت.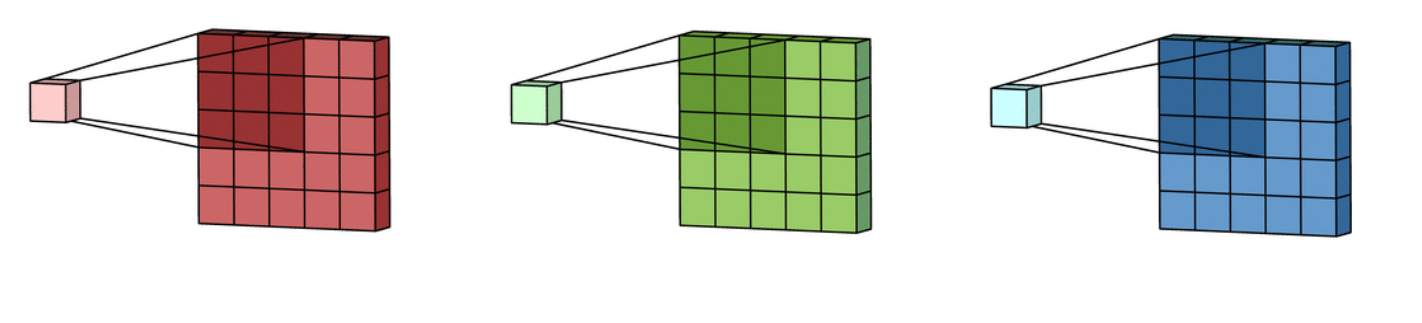 نکته:
نکته:
- عمق فیلترمان باید به اندازه عمق عکس ورودی باشد(کانال های رنگی آن)
- تعداد فیلترها یک هایپر پارامتر است.
- عمق فیلتر = عمق عکس ورودی
- عمق یا تعداد کانال های خروجی = تعداد فیلترها
- عمق فیلتر=5
- خروجی=6*6(اگر بیش از یک فیلتر بزنیم=6*6*n)
- نکته : هرچه فیلترمان بهتر و قوی تر باشد عدد برگردانده شده توسط فیلتر بزرگتر خواهد بود.
یک شبکه عصبی به ترتیب شامل:
- Convolution layer
- Pooling layer
- Full connected
- نکته : اگر میخواهیم از لایه ی pooling استفاده کنیم حتما باید بعد ازلایه convolution قرار بگیرد.
Pooling layer:
به مفهوم ادغام کردن داده هایمان است. به نوعی میتوان گفت که یک عدد به نمایندگی کل خروجی کانولوشن بر میکرداند.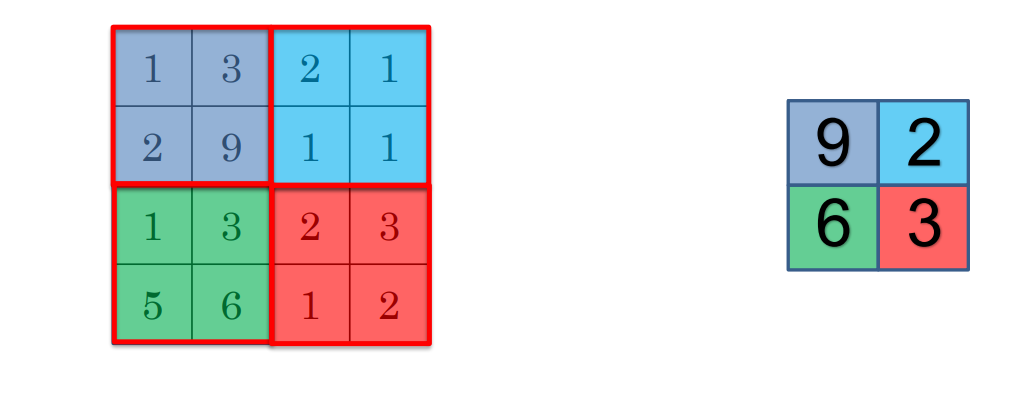
لایه pooling انواع مختلفی دارد از جمله : max pooling, min pooling
- max pooling: بزرگترین عدد خروجی را برمی گرداند.
- min pooling : میانگین همه خونه ها رو حساب می کند و یک عدد را برمیگرداند.
چرا max poolingمنطقی تر است؟
برای مثال فرض کنید که ما میخواهیم فیلترمان خط45 درجه را تشخیص بدهد پس اگر این pattern فقط در یک چای تصویرهم دیده شده باشد برای کفایت می کند،بنابراین استفاده از max poolingمنطقی تر است. نکته:- به ازای هر لایهconvolution یک لایهpooling خواهیم داشت و بیشتر از آن معنی ندارد.
- لایه pooling عمق را تغییر نمی دهد،روی همه کانال ها انجام می شود.
 سوال ها:
سوال ها:
- سوال 1: چرا باید از شبکههای عصبی کانولوشنی استفاده کنیم؟
-
- کاهش تعداد پارامترها: با استفاده از فیلترهای کانولوشن، تعداد پارامترهای مورد نیاز برای شبکه به مقدار قابل توجهی کاهش مییابد.
- استخراج اطلاعات خاص (special information):این به معنای توانایی در شناسایی الگوها و اطلاعات محلی در دادهها میباشد.
- عملگر کانولوشن: این عملگر به وسیله حرکت یک فیلتر روی یک تصویر، اطلاعات جدیدی را استخراج میکند.
- سوال 2: چگونه عملگر کانولوشن کار میکند؟ عملگر کانولوشن به این شکل است که یک فیلتر را روی یک تصویر حرکت داده و یک تصویر جدید (نیز با نام feature map یا activation map) به دست میآورد. این فیلتر به طور معمول از ابعاد کوچکتری نسبت به تصویر اصلی استفاده میشود و از آنجا که وزنهای فیلتر رندوم هستند، در مراحل بعدی با استفاده از الگوریتمهای backpropagation و gradient descent، وزنها بهروزرسانی میشوند تا بهترین وزنها برای شبکه بهدست آید.
- سوال 3: در مورد اندازه و مشخصات فیلتر کانولوشن چه گونه تعیین میشوند؟ اندازه و مشخصات فیلتر کانولوشن به دلخواه توسط کاربر تعیین میشوند. این انتخابها شامل انتخاب اندازه (مثل 3x3 یا 5x5) و تعداد فیلترها میشود. در شبکههای عصبی کانولوشنی، این فیلترها با وزنهای رندوم مقداردهی میشوند، و سپس با استفاده از الگوریتمهای بهینهسازی مانند backpropagation و gradient descent، وزنها بهروزرسانی میشوند.
- سوال 4: چگونه لایههای کانولوشنی از نظر local pattern با لایههای تماماً متصل (Dense layers) تفاوت دارند؟ لایههای کانولوشنی به دنبال local pattern یا الگوهای محلی در دادهها هستند، در حالی که لایههای تماماً متصل (Dense layers) به دنبال global patterns یا الگوهای کلی در دادهها میگردند. لایههای کانولوشنی بهصورت سلسلهمراتبی از فیچرها (الگوها) را استخراج میکنند و همچنین دارای مفهوم weight sharing هستند که به اشتراکگذاری وزنها بین نقاط مختلف تصویر اشاره دارد. این ویژگیها باعث میشود که شبکههای عصبی کانولوشنی مقاوم به تغییرات مکانی (translation invariance) باشند و اهمیت نسبت به جا به جایی (shift) در دادهها کاهش یابد.
- سوال 5: مشکلاتی که در استفاده از لایههای کانولوشنی مطرح میشود چه هستند؟ و چگونه میتوان این مشکلات را حل کرد؟
در استفاده از لایههای کانولوشنی، مشکلات زیر ممکن است پیش آید:
- عدم همپوشانی لبهها: لبهها به اندازه پیکسلهای درونی در کانولوشن شرکت نمیکنند، به عبارت دیگر پیکسلهای میانی (خانههای وسط) بیشتر تأثیر گذارند.
- خروجی کوچک: اعمال فیلتر بر روی عکس باعث کوچکتر شدن ابعاد تصویر میشود و ممکن است منجر به از دست رفتن اطلاعات مهم شود.
- استفاده از padding: افزودن پیکسلهای صفر (یا مقدارهای مشخص) به اطراف تصویر قبل از اعمال فیلتر، باعث میشود که ابعاد تصویر حفظ شود و از از دست رفتن اطلاعات در لبهها جلوگیری شود.
- تنظیم اندازه فیلتر: انتخاب اندازه مناسب برای فیلترها به میزان کمک کند. فیلترهای کوچکتر معمولاً توجه به جزئیات را افزایش میدهند.
- استفاده از stride مناسب: تنظیم گام حرکت فیلتر (stride) به نحوی که مشکل کاهش ابعاد تصویر را حل کند و در عین حال از اطلاعات مهم در لبهها حفظ شود.