المنتور #391

/*! elementor - v3.17.0 - 08-11-2023 */ .elementor-heading-title{padding:0;margin:0;line-height:1}.elementor-widget-heading .elementor-heading-title[class*=elementor-size-]>a{color:inherit;font-size:inherit;line-height:inherit}.elementor-widget-heading .elementor-heading-title.elementor-size-small{font-size:15px}.elementor-widget-heading .elementor-heading-title.elementor-size-medium{font-size:19px}.elementor-widget-heading .elementor-heading-title.elementor-size-large{font-size:29px}.elementor-widget-heading .elementor-heading-title.elementor-size-xl{font-size:39px}.elementor-widget-heading .elementor-heading-title.elementor-size-xxl{font-size:59px}
در این پست قراره در مورد آموزش شبکه های کانولوشنی وشمردن پارامتر های اون صحبت کنیم
/*! elementor - v3.17.0 - 08-11-2023 */ .elementor-widget-image{text-align:center}.elementor-widget-image a{display:inline-block}.elementor-widget-image a img[src$=".svg"]{width:48px}.elementor-widget-image img{vertical-align:middle;display:inline-block}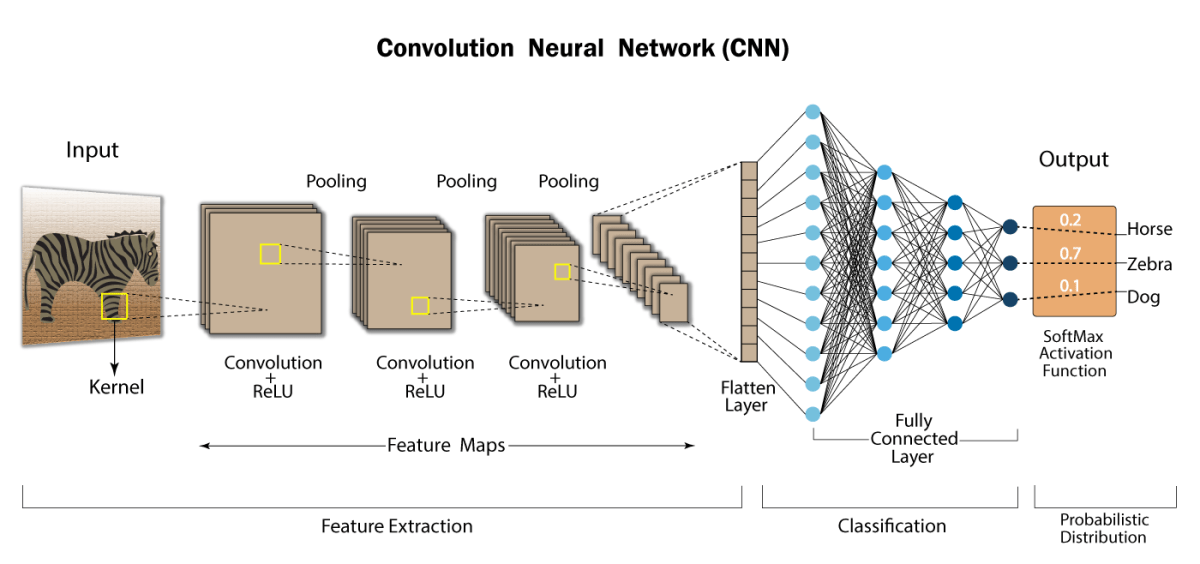
شبکههای عصبی با استفاده از یک فرآیند به نام آموزش، یاد میگیرند. در طول آموزش، شبکهها با مجموعهای از دادههای نمونه آموزش داده میشوند. این دادهها شامل ورودیها و خروجیهای مورد انتظار است. شبکه از این دادهها برای یادگیری نحوه تولید خروجیهای مورد انتظار برای ورودیهای جدید استفاده میکند.
حالا وارد بخش عملی یعنی کد می شویم :
در این مسئله از دیتاست سگ و گربه استفاده می کنیم . این دیتاست شامل 25000 تصویر سگ و گربه هست که به طور مساوی تقسیم شده اند . این دیتاست را می توانید از لینک زیر دانلود کنید:
https://www.kaggle.com/c/dogs-vs-cats
import tensorflow as tf
# تعریف مدل CNN
model = tf.keras.Sequential()
در این خط، یک مدل Sequential از کتابخانه TensorFlow تعریف می کنیم. یک مدل Sequential از مجموعه ای از لایه ها تشکیل شده است که به ترتیب روی داده ها اعمال می شوند.
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(150, 150, 3)))
در این خط، یک لایه کانولوشن با 32 فیلتر 3*3 با تابع فعال سازی relu اضافه می کنیم. پارامتر input_shape اندازه ورودی تصویر را مشخص می کند. در این مثال، تصاویر 150x150x3 هستند.
model.add(layers.MaxPooling2D((2, 2)))
در این خط، یک لایه ماکزیموم پولینگ با اندازه 2*2اضافه می کنیم. این لایه ابعاد تصویر را کاهش می دهد و تعداد پارامترهای مدل را کاهش می دهد.
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
در این خطوط، پنج لایه کانولوشن دیگر اضافه می کنیم. هر لایه تعداد فیلترهای بیشتری نسبت به لایه قبلی دارد.
model.add(layers.Flatten())
در این خط، یک لایه Flatten اضافه می کنیم. این لایه ابعاد تصویر را به یک بعد کاهش می دهد.
model.add(layers.Dense(512, activation='relu'))
در این خط، یک لایه متراکم با 512 نورون با تابع فعال سازی relu اضافه می کنیم.
model.add(layers.Dense(1, activation='sigmoid'))
در این خط، یک لایه متراکم با یک نورون با تابع فعال سازی sigmoid اضافه می کنیم. این لایه خروجی مدل را تولید می کند.
# آموزش مدل
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
در این خط، مدل را با استفاده از تابع هزینه binary_crossentropy و معیار accuracy آموزش می دهیم.
# تقسیم داده ها به مجموعه های آموزشی و آزمایشی
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.dogs_vs_cats.load_data()
در این خط، داده های دیتاست سگ و گربه را به مجموعه های آموزشی و آزمایشی تقسیم می کنیم.
# آموزش مدل
model.fit(x_train, y_train, epochs=10)
در این خط، مدل را برای 10 تکرار روی مجموعه آموزشی آموزش می دهیم.
# ارزیابی مدل
model.evaluate(x_test, y_test)
اگر بعد از ساخت مدل دستور model.summary() را بزنیم اطلاعاتی به ما نمایش داده می شود.
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 148, 148, 32) 896
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 74, 74, 32) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 72, 72, 64) 18496
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 36, 36, 64) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 34, 34, 128) 73856
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 17, 17, 128) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 15, 15, 128) 147584
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 7, 7, 128) 0
_________________________________________________________________
flatten (Flatten) (None, 6272) 0
_________________________________________________________________
dense (Dense) (None, 512) 3211776
_________________________________________________________________
dense_1 (Dense) (None, 1) 513
=================================================================
Total params: 3,453,121
Trainable params: 3,453,121
Non-trainable params: 0
مشاهده می کنیم که حدود 3.5میلیون پارامتر وجو دارد. حالا این پارامتر ها را چگونه خودمان به دست بیاریم؟
برای محاسبه تعداد پارامترهای هر لایه، میتوانید از فرمولهای زیر استفاده کنید:
برای لایههای کانولوشنال:
تعداد پارامترها = (اندازه_هسته * عمق_ورودی + 1) * تعداد_فیلترها
برای لایههای لایههای پرسپترون (Dense):
تعداد پارامترها = (تعداد_واحدها_لایه_قبلی + 1) * تعداد_واحدها_لایه_فعلی
در این فرمولها:
- اندازه_هسته: اندازه هسته یا فیلتر
- عمق_ورودی: تعداد کانالهای ورودی
- تعداد_فیلترها: تعداد فیلترها یا نورونهای خروجی
- تعداد_واحدها_لایه_قبلی: تعداد واحدهای لایه قبلی
- تعداد_واحدها_لایه_فعلی: تعداد واحدهای لایه فعلی
با استفاده از این فرمولها، میتوانید تعداد پارامترهای هر لایه را محاسبه کنید.
برای لایههای کانولوشنال:
تعداد پارامترها = (اندازه_هسته * عمق_ورودی + 1) * تعداد_فیلترها
برای لایههای لایههای پرسپترون (Dense):
تعداد پارامترها = (تعداد_واحدها_لایه_قبلی + 1) * تعداد_واحدها_لایه_فعلی
حالا بیایید تعداد پارامترهای هر لایه مدل مان را محاسبه کنیم:
- برای اولین لایه Conv2D:
تعداد پارامترها = (3 * 3 * 3 + 1) * 32 = 896
- برای لایه MaxPooling2D:
این لایه پارامتر قابل آموزش ندارد، بنابراین تعداد پارامترها صفر است.
- برای دومین لایه Conv2D:
تعداد پارامترها = (3 * 3 * 32 + 1) * 64 = 18496
- برای لایه MaxPooling2D:
این لایه نیز پارامتر قابل آموزش ندارد، بنابراین تعداد پارامترها صفر است.
- برای سومین لایه Conv2D:
تعداد پارامترها = (3 * 3 * 64 + 1) * 128 = 73856
- برای لایه MaxPooling2D:
این لایه نیز پارامتر قابل آموزش ندارد، بنابراین تعداد پارامترها صفر است.
- برای چهارمین لایه Conv2D:
تعداد پارامترها = (3 * 3 * 128 + 1) * 128 = 157584
- برای لایه MaxPooling2D:
این لایه نیز پارامتر قابل آموزش ندارد، بنابراین تعداد پارامترها صفر است.
- برای لایه Flatten:
این لایه نیز پارامتر قابل آموزش ندارد، بنابراین تعداد پارامترها صفر است.
- برای لایه Dense:
تعداد پارامترها = (6272 + 1) * 512 = 3211776
- برای لایه Dense:
تعداد پارامترها = (512 + 1) * 1 = 513
حالا میتوانیم مجموع تعداد پارامترهای کل مدل را محاسبه کنیم:
مجموع تعداد پارامترها = 896 + 0 + 18496 + 0 + 73856 + 0 + 147584 + 0 + 0 + 3211776 + 513 = 3453121
بنابراین، تعداد کل پارامترهای مدل شما 3,453,121 است.
سوال : پارامتر های زیاد یا کم چه تاثیری در خروجی مدل شبکه عصبی کانولوشنی دارند ؟
پارامترهای زیاد یا کم در مدل های شبکه عصبی کانولوشنی نیز می تواند تأثیر زیادی بر خروجی مدل داشته باشد.
پارامترهای زیاد
پارامترهای زیاد به مدل اجازه می دهد تا تفاوت های ظریف در داده های آموزشی را یاد بگیرد. این می تواند منجر به خروجی دقیق تر مدل شود. با این حال، پارامترهای زیاد همچنین می تواند منجر به افزایش نوسان در خروجی مدل شود. این می تواند باعث افزایش احتمال وقوع overfitting شود.
پارامترهای کم
پارامترهای کم به مدل اجازه می دهد تا تفاوت های ظریف در داده های آموزشی را یاد نگیرد. این می تواند منجر به خروجی نامشخص تر مدل شود. با این حال، پارامترهای کم همچنین می تواند منجر به کاهش نوسان در خروجی مدل شود. این می تواند باعث کاهش احتمال وقوع overfitting شود.
خروجی مدل
خروجی مدل شبکه عصبی کانولوشنی به اندازه و پیچیدگی داده های آموزشی و هدف از مدل بستگی دارد. در حالت کلی، مدل های شبکه عصبی کانولوشنی با پارامترهای زیاد برای داده های آموزشی بزرگ و پیچیده و مدل های شبکه عصبی کانولوشنی با پارامترهای کم برای داده های آموزشی کوچک و ساده مناسب هستند.
در اینجا چند نکته برای بهبود خروجی مدل شبکه عصبی کانولوشنی آورده شده است:
- از یک آزمایش متقابل استفاده کنید تا تأثیر تعداد پارامترهای مختلف را بر خروجی مدل ارزیابی کنید.
- از یک معماری شبکه عصبی کانولوشنی استفاده کنید که برای داده های آموزشی شما مناسب باشد.
- از یک تابع هزینه استفاده کنید که برای هدف از مدل شما مناسب باشد.
مثال
برای مثال، فرض کنید می خواهیم یک مدل شبکه عصبی کانولوشنی برای تشخیص چهره انسان ایجاد کنیم. اگر داده های آموزشی ما شامل تصاویر چهره های انسان از زوایای مختلف باشد، ممکن است نیاز داشته باشیم یک مدل شبکه عصبی کانولوشنی با پارامترهای زیاد ایجاد کنیم تا بتواند تفاوت های ظریف در چهره انسان را یاد بگیرد. با این حال، اگر داده های آموزشی ما شامل تصاویر چهره های انسان از زاویه جلو باشد، ممکن است نیاز داشته باشیم یک مدل شبکه عصبی کانولوشنی با پارامترهای کم ایجاد کنیم تا از overfitting جلوگیری کنیم.
در نهایت، انتخاب تعداد پارامترهای مناسب برای یک مدل شبکه عصبی کانولوشنی به داده های آموزشی و هدف از مدل بستگی دارد.
علاوه بر موارد ذکر شده در بالا، پارامترهای زیاد یا کم در مدل های شبکه عصبی کانولوشنی می تواند تأثیر زیادی بر سرعت آموزش و مقدار حافظه مورد نیاز مدل نیز داشته باشد.
پارامترهای زیاد می تواند منجر به افزایش زمان آموزش و افزایش مقدار حافظه مورد نیاز مدل شود. این می تواند باعث کاهش کارایی مدل شود.
پارامترهای کم می تواند منجر به کاهش زمان آموزش و کاهش مقدار حافظه مورد نیاز مدل شود. این می تواند باعث افزایش کارایی مدل شود.
بنابراین، هنگام انتخاب تعداد پارامترهای مناسب برای یک مدل شبکه عصبی کانولوشنی، باید به همه عوامل ذکر شده توجه داشت.

امیدوارم این پست براتون مفید باشه.
سوالات
تعداد پارامترهای لایه Conv2D با 32 فیلتر 3x3 و ورودی 150x150x3 چقدر است؟
(الف) 896
(ب) 18496
(ج) 3211776
(د) 513
پاسخ:
(الف) 896
کدام عبارت درباره تاثیر پارامترهای زیاد در مدل های شبکه عصبی کانولوشنی صحیح است؟
(الف) پارامترهای زیاد می تواند منجر به افزایش دقت مدل و افزایش احتمال overfitting شود.
(ب) پارامترهای زیاد می تواند منجر به کاهش دقت مدل و کاهش احتمال overfitting شود.
(ج) پارامترهای زیاد هیچ تاثیری بر دقت و احتمال overfitting مدل ندارد. (د) پارامترهای زیاد فقط باعث افزایش زمان آموزش مدل می شود.
پاسخ:
(الف) پارامترهای زیاد می تواند منجر به افزایش دقت مدل و افزایش احتمال overfitting شود.
کدام عامل در انتخاب تعداد پارامترهای مناسب برای یک مدل شبکه عصبی کانولوشنی نقشی ندارد؟
(الف) اندازه و پیچیدگی داده های آموزشی
(ب) هدف از مدل
(ج) نوع کامپیوتر مورد استفاده
(د) میزان حافظه موجود
پاسخ:
(ج) نوع کامپیوتر مورد استفاده
برای بهبود خروجی مدل شبکه عصبی کانولوشنی کدام اقدام غیرضروری است؟
(الف) استفاده از یک آزمایش متقابل برای ارزیابی تاثیر تعداد پارامترهای مختلف
(ب) استفاده از یک معماری شبکه عصبی کانولوشنی مناسب برای داده های آموزشی
(ج) افزایش تعداد پارامترهای مدل بدون در نظر گرفتن سایر عوامل
(د) استفاده از تکنیک های regularization
پاسخ:
(ج) افزایش تعداد پارامترهای مدل بدون در نظر گرفتن سایر عوامل
در چه صورت باید از مدل های شبکه عصبی کانولوشنی با پارامترهای کم استفاده کرد؟
(الف) زمانی که داده های آموزشی بزرگ و پیچیده هستند.
(ب) زمانی که هدف از مدل دقت بالا است.
(ج) زمانی که سرعت آموزش و کارایی مدل از اهمیت بالایی برخوردار است.
(د) زمانی که حافظه کامپیوتر محدود است.
پاسخ:
(ج) زمانی که سرعت آموزش و کارایی مدل از اهمیت بالایی برخوردار است.