رگرسیون چیست و توضیح کد regression_with_knn

/*! elementor - v3.17.0 - 08-11-2023 */ .elementor-heading-title{padding:0;margin:0;line-height:1}.elementor-widget-heading .elementor-heading-title[class*=elementor-size-]>a{color:inherit;font-size:inherit;line-height:inherit}.elementor-widget-heading .elementor-heading-title.elementor-size-small{font-size:15px}.elementor-widget-heading .elementor-heading-title.elementor-size-medium{font-size:19px}.elementor-widget-heading .elementor-heading-title.elementor-size-large{font-size:29px}.elementor-widget-heading .elementor-heading-title.elementor-size-xl{font-size:39px}.elementor-widget-heading .elementor-heading-title.elementor-size-xxl{font-size:59px}
1_رگرسیون چیست؟
رگرسیون در هوش مصنوعی یک روش یادگیری نظارت شده است که برای پیشبینی مقادیر پیوسته از دادهها استفاده میشود. رگرسیون با یادگیری رابطه بین متغیرهای ورودی و خروجی، میتواند مدلهایی از روابط بین دادهها ایجاد کند و از آنها برای تحلیل یا پیشبینی دادههای جدید استفاده کند. رگرسیون انواع مختلفی دارد که بسته به نوع متغیرهای ورودی و خروجی میتوان از آنها استفاده کرد.
/*! elementor - v3.17.0 - 08-11-2023 */ .elementor-widget-image{text-align:center}.elementor-widget-image a{display:inline-block}.elementor-widget-image a img[src$=".svg"]{width:48px}.elementor-widget-image img{vertical-align:middle;display:inline-block}
2_انواع رایج رگرسیون
- رگرسیون خطی: این روش برای پیشبینی مقادیر پیوسته از یک متغیر وابسته بر اساس یک یا چند متغیر مستقل استفاده میشود. این روش با فرض اینکه رابطه بین متغیرها خطی است، یک خط صاف را برای توصیف دادهها ایجاد میکند. مثال: پیشبینی قیمت خانه بر اساس متراژ، تعداد اتاق و سال ساخت.
- رگرسیون منطقی: این روش برای پیشبینی مقادیر دودویی (صفر یا یک) از یک متغیر وابسته بر اساس یک یا چند متغیر مستقل استفاده میشود. این روش با استفاده از یک تابع منطقی، احتمال رخداد یک رویداد را محاسبه میکند. مثال: پیشبینی اینکه یک بیمار به بیماری قلبی مبتلا است یا نه بر اساس فشار خون، کلسترول و سن.
- رگرسیون غیرخطی: این روش برای پیشبینی مقادیر پیوسته از یک متغیر وابسته بر اساس یک یا چند متغیر مستقل استفاده میشود. این روش با فرض اینکه رابطه بین متغیرها غیرخطی است، یک منحنی را برای توصیف دادهها ایجاد میکند. مثال: پیشبینی میزان مصرف سوخت بر اساس سرعت، دما و شیب جاده
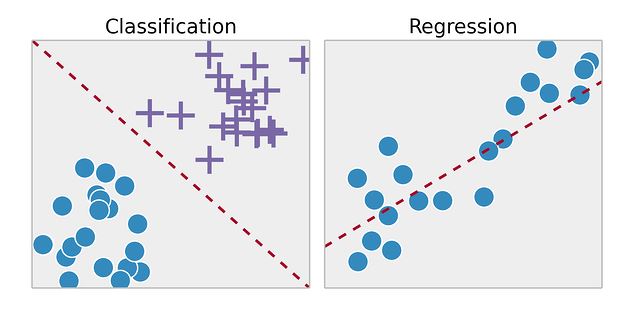
3_تفاوت بین مسائل طبقه بندی (classification)و رگرسیون
classification و رگرسیون دو نوع از یادگیری نظارت شده هستند که برای پیشبینی خروجی از دادههای ورودی استفاده میشوند. تفاوت اصلی بین آنها در نوع خروجی است. در classification، خروجی یک مقدار گسسته است که به یکی از دستههای مشخص شده تعلق دارد. مثال: پیشبینی اینکه یک ایمیل اسپم است یا نه. در رگرسیون، خروجی یک مقدار پیوسته است که میتواند هر عددی باشد. مثال: پیشبینی قیمت خانه بر اساس مشخصات آن.برای بیان سادهتر، میتوان گفت که classification یک مسئله دستهبندی است و رگرسیون یک مسئله تخمین است.
برای مطالعه بیشتر درباره تفاوت بین classification و رگرسیون، میتوانید از این منابع استفاده کنید:
- تفاوت بین طبقه بندی و رگرسیون
- الگوریتم های رگرسیون و طبقه بندی چه تفاوت هایی با هم دارند
- تفاوت رگرسیون با classification
4_توضیح کد regression_with_Knn

ابتدا در خصوص ماژول های مورد نیاز توضیح بدهیم در این کد از ماژول mglearn که توسط آقای مولر توسعه دادشده جهت درک الگوریتم از این ماژول استفاده کردیم و دو ماژول بعدی شامل matplotlib.pyplot و numpy هم که با آن آشنا هستید و نیاز به توضیح ندارد و دستور آخر در ورژن های قدیمی notebook استفاده می شد. برای این که برای نمایش تصاویر صفحه جدید باز نکند که الان در ورژن های جدید notebook نیازی به اضافه کردن این دستورنیست
k-neighbors regression
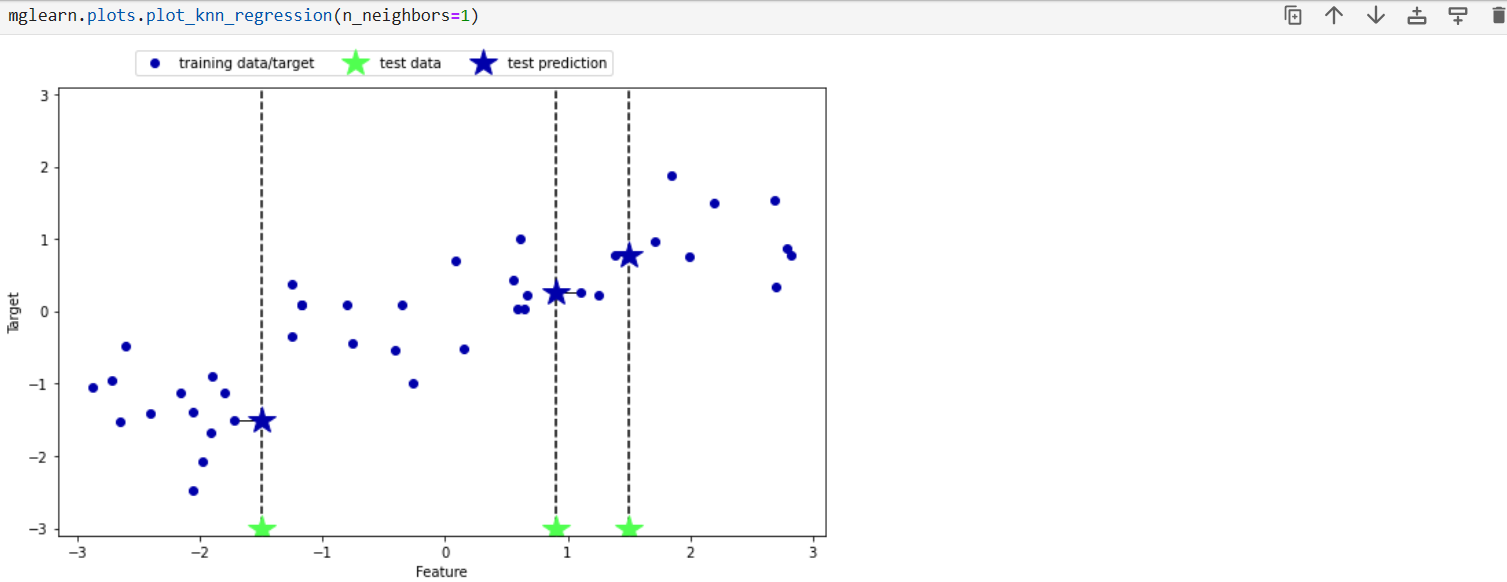
در اینجا همانطور که قبلا هم اشاره کردم با استفاده از mglearn به جای ساخت اسلاید از قابلیت این ماژول استفاده کرده و نتایح و نحوه کارکرد الگوریتم رگرسیون را می بینیم (برای اینکه بتوانیم مسائل را به صورت visualize ببینم و بهتر درک کنیم )در اینجا ما همان مسئله k نزیک ترین همسایه را برای مقادیر k برابر 1و2و3 برسی می کنیم در این شکل محور x(افقی) محور ویژگی ها است(features)که دراینجا یک ویژگی است اما در دنیای واقعی ما یک ویژگی نداریم بلکه n ویژگی داریم که باید بر اساس آن ما پیش بینی انجام بدهم (تخمین بزنم). و محورy محور targetاست که براساس ویژگی های مقدار target را تخمین می زنیم
ابتدا برای k برابر 1: همان طور که در تصویر مشاهده مکنید ستاره های سبز رنگ آن دیتای تست ما است که براساس داده های قبی که برنامه ما آموزش دیده بیاید و target آن را پیش بینی کند و دایرهای آبی رنگ هم دادهای قبلی که براساس آن ها آموزش دیده است.و ستاره های آبی رنگه هم پیش بینی که انجام داده است، همانطور که مشاهده می کنید مانند همان مثال knn که به صورت classification حل کردیم نزدیک ترین همسایه به خود را پیدا می کند.
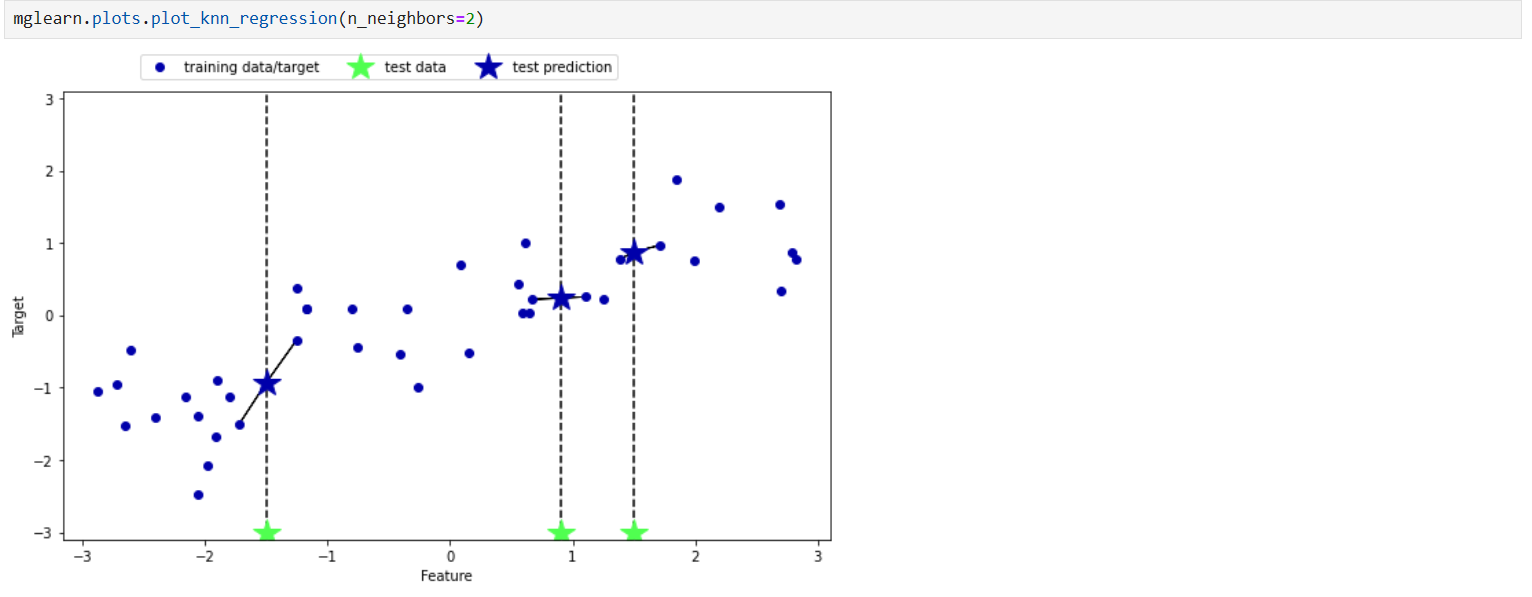
در این جا ما مثال را برای k=2 رسم کرده و بررسی می کنیم در اینجا دیگر نگاه نمی کند که به کدام نزدیک تر است اینجا ابتدا میانگین می گرد و سپس پیش بینی می کند به عبارتی معکوس فاصله داده ها دخالت دارند.و حساسیت آن به نویز نیز کمتر شده است.
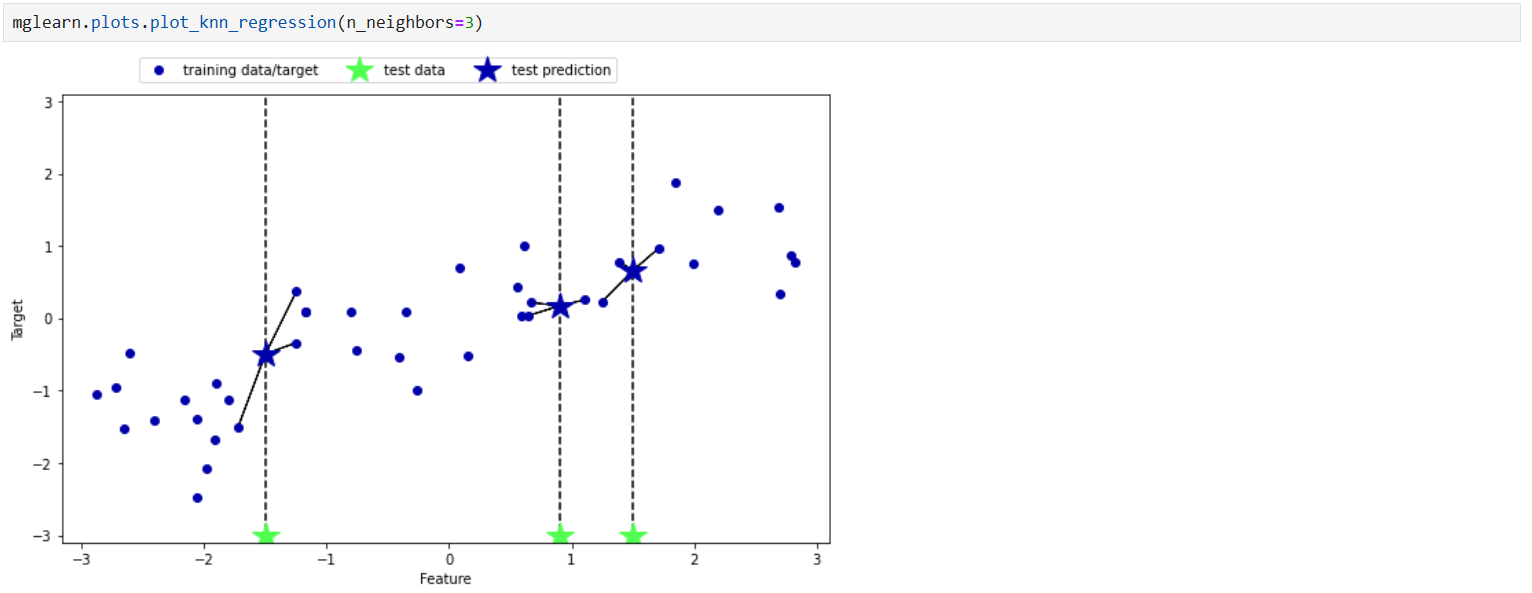
در این جا نیز با توجه به این که k=3 شده است اولا که حساسیت به نویز نسبت به دو مورد قبلی کمتر شده است و حال سه همسایه را برای پیش بینی در نظرگرفته و همچنین
میانگین آن هم نسبت به قبلی بیشتر شده چون سه همسایه دخیل هستن و همچنین این برای نشان دادن این است که تعیین مقدار k که یک هایپرپارامتر است با آزمایش و خطا
صورت می گیرد.

در این قسمت با استفاد از دستور mglearn.dataset.make_wave یک دیتاست ساختگی ساختیم همانطور که گفتیم هدف از mglearn یادگیری است و بعدا ما با مسائل واقعی تر کار میکنیم.وبرای این دیتاست ما 40 عدد Sample داریم و این دیتا ست را رسم مکنیم اگر دقت کنید که y های ما پیوسته است و در رسم هم یک حالت wavaفرمی دارد که به سمت بالا رفته با یک نویز بسیار زیاد.
الان که من داده هایم را ساختم زمان آن رسیده که آن را با الگوریتم های مختلف بررسی کنم.
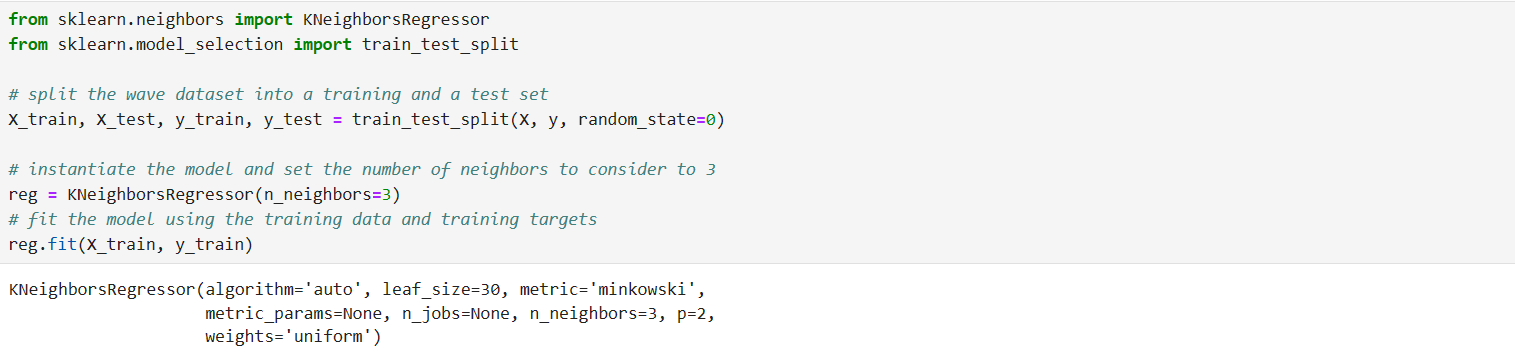
در اینجا ما از ماژول sklearn و به جای مدل classification آن از KNeighborRegressor استفاده کنیم. و همچنان هم از train_test_split را هم برای اینکه داده ها را به دوقسمت
train و test تقسیم کنم استفاده می کنم ود رنهایت می خواهم داده ها را بر اساس 3 همسایه آموزش بدهم و بعد هم بررسی کنم و در نهایت این داده های train را با دستورfit آموزش می دهم .

در این قسمت هم نوبت به ارزیابی مدل می رسد که میزان دقت داشته است به هم منظور از دستور predict استفاده کرده و داده های تست را به آن می دهیم که بر روی آن ها پیش بینی انجام بدهد و نتیجه پیش بینی راهم
نشان داده ایم و در آخر باید برسی کنیم که مدل ما تا چه انداز خوب بود ه است باید از آن یک score بگریم .
در sklearn الگوریتم های متعددی موجود است و برای هر یک از آنها نیز یک روش متفاوت برای انداز گیری است برخلاف مدل قبلی که تعداد پیشبینی های درست را شمارش کرده و به صورت درصد بیان می کرد
در اینجا از R^2 استفاده می شود که برای مطالعه بیشتر می توانید در مورد آن جستجو می کنیم و به هر حال هر اندازه که score ما به یک نزدیک تر باشد بهتر است و هرچه به صفر نزدیک باشد نتیجه بسیار بد است
که در اینجا طبق تصویر score=0.83 شده است که به نسبت خوب است.
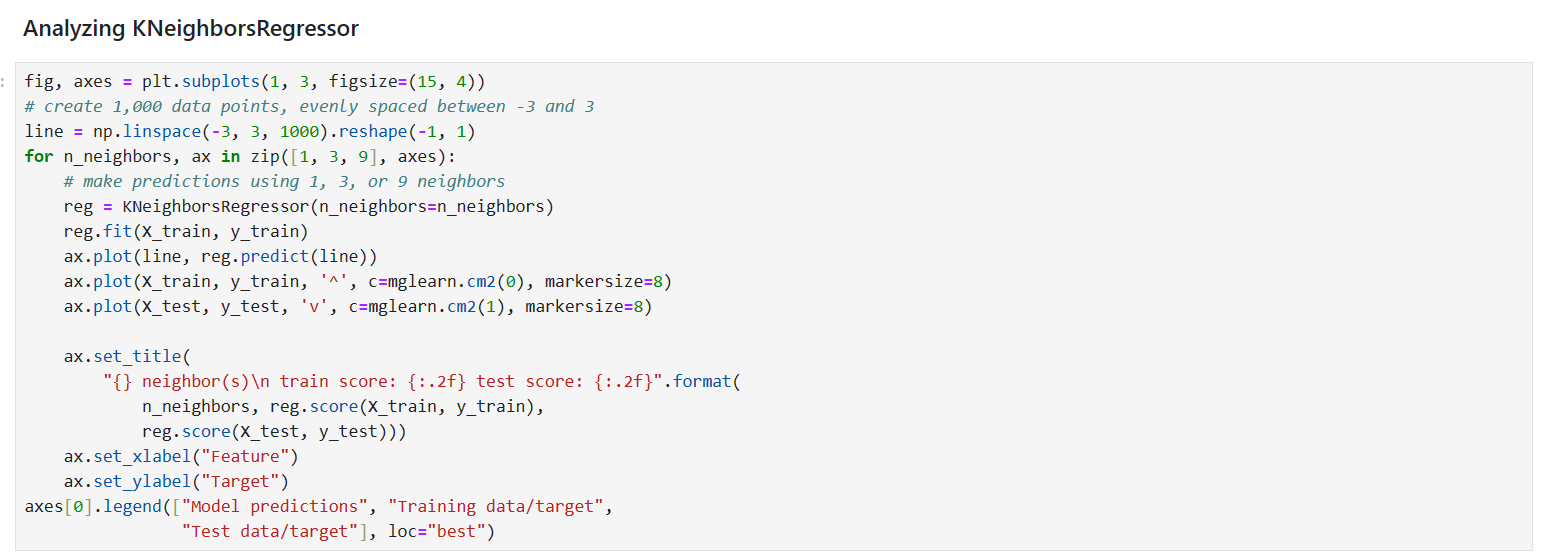
در اینجا یک آنالیز برروی مدل رگرسیون انجام داده ایم به این صورت که ما با استفاد از از subplot برای رسم 3 جدول یک سطرو سه ستون را اختصاص داده ایم. و سپس برای اینکه نشان دهم که رگرسیون پیوسته است
با دستور linespase من 1000 عدد ساخته ام که کوچکترین مقدار ممکن 3- و بیشترین مقدار ممکن 3 است. و سپس یک حلقه for زده ام و می خواهم سه مقدار 1و3و9 را به عنوان مقدار n_neighbor بدهم و سه جدول هم
که نتایج را نشان دهد رسم کنم برای اینکار از دستور zip استفاده کردم که دو لیست که در اینجا هم سایز هستن را به یک لیست tuple تبدیل کرده و روی هر دوی آن ها به صورت همزمان حرکت کند و بعد از آن هم برای رسم پیش بینی از plot استفاده کردم و محمور x من همان 1000 عدد است که ساختم و محور عمودی هم پیش بینی آن 1000 نقطه است. و بعد هم یک سری عنوان به آن جدول ها دادم و هم چنیین مقدار دقت در test و train را هم چاپ می کند.که در ادامه به توضیح مقدار k چه تاثیر در مقدار دقت test و train می گذارد.
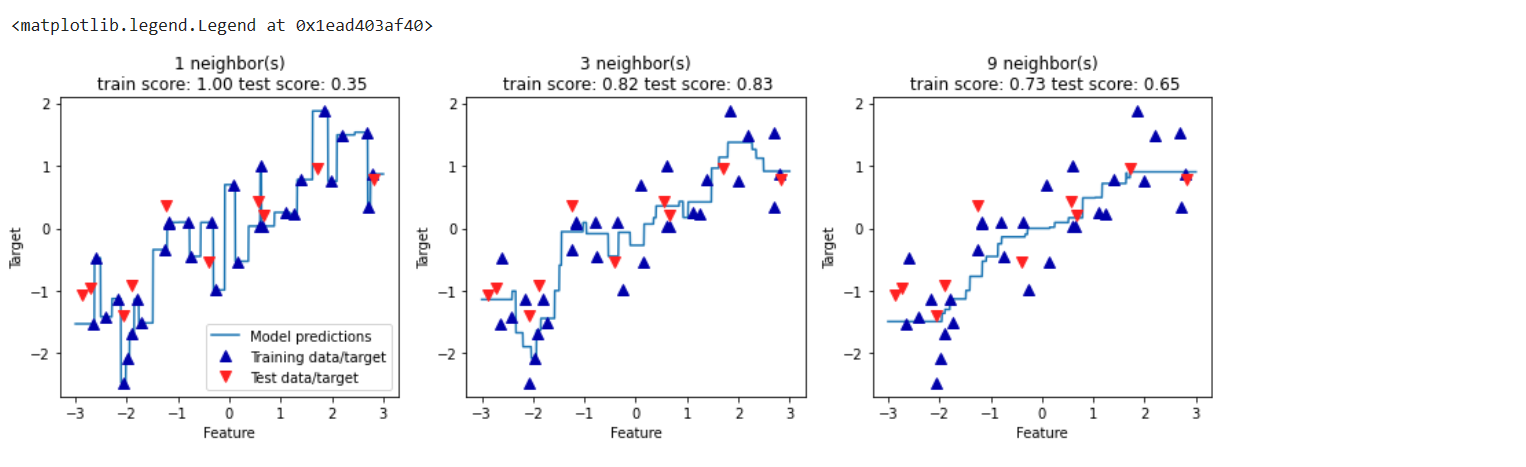
در ابتدا این خط model prediction که این گونه به داده وصل شده حکایت از پیوسته بود ن دارد.و همانطور که می بینید در تصویر سمت چپ که مقدار k=1 است روی داده های train
به شد خوب عمل کرده است و score آن هم برابر 1 شده است اما خاصیت عمومیت بخشی ندارد (قدرتgeneralizetion) ما هر داده از داده های train را به آن بدهیم خوب عمل می کد
اما در داده های جدید به خوبی عمل نمی کند همانطور که در تصویر هم مشاهد می کنید پیش بینی ما از داده های تست خیلی فاصله دارد و از Score=0.35 هم می شود فهمید که مدل خاصیت generalization ندارد. برای همین ما k را باید افزایش بدهیم .و در این مدل اصطلاحا میگویم که داده های train را حفظ کرده است.
اما در k=3 اوضاع خیلی بهتر شده درست است که دقت در trian=0.82 است اما دقت و score در test=0.83 شده است که خیلی خوب است هم پیش بینی به داده های test نزدیک شده و هم مدل داده ها train را حفظ نکرده و اوضا ع نسبت به قبلی که k=1 بود بهتر شده است.
اما الان که k=9 کردیم اوضاع هم در train و هم در test بد تر شده است چون که دارد به یک سری داده های نامرتبط هم حساسیت نشان می دهد و همین باعث شده نه بتواند خاصیت generalization داشته باشد و نه داده ها یtrain را حفظ کند این جا اوضاع نسبت به k=1 اوضا ع خیلی بد تر شده است.
نتبجه گیری کلی: ما نمی توانیم همواره بگوییم که افزایش k باعث افزایش دقت می شود ، همانطور که مشاهد شد اگر مقدار k خیلی کوچک باشد به سمت حفظ داده ها می رود و خاصیت generalization از دست می دهده و اگر هم خیلی زیاد شود به موارد ی نباید به آن ها توجه کرد توجه می کند و نه می تواند داده ها را حفظ کند و نه می تواند generalization داشته باشد. و هموار مقدار k یک هایپرپارامتر است و باید به اصطلاح آن را tune کرد.
سوالات
1) کدام یک از این مثالها مربوط به رگرسیون غیرخطی است؟
الف) پیشبینی قیمت خانه بر اساس متراژ، تعداد اتاق و سال ساخت
ب) پیشبینی اینکه یک بیمار به بیماری قلبی مبتلا است یا نه بر اساس فشار خون، کلسترول و سن
ج) پیشبینی میزان مصرف سوخت بر اساس سرعت، دما و شیب جاده
د) پیشبینی اینکه یک ایمیل اسپم است یا نه بر اساس محتوا، فرستنده و عنوان
2)چه تعداد از جملات زیر صحیح می باشد؟
_رگرسیون یک روش یادگیری نظارت شده نیست.
_رگرسیون غیرخطی با فرض این که رابطه بین متغیر ها هندسی است یک منحنی را برای توصیف داده ها ایجاد می کند.
_رگرسیون منطقی با استفاد از یک تابع منطقی-خطی احتمال رخداد یک رویداد را محاسبه می کند.
---------------------------------------------------------------------------------------------------------
الف)1 ب)2 ج)3 د)هیچ کدام
3)کدام یک از این مثالها بهترین نمونه از استفاده از رگرسیون و classification در یک مسئله هوش مصنوعی است؟
الف) پیشبینی قیمت خانه بر اساس متراژ، تعداد اتاق و سال ساخت با استفاده از رگرسیون خطی و دستهبندی خانهها به دستههای ارزان، متوسط و گران با استفاده از رگرسیون منطقی.
ب) پیشبینی اینکه یک بیمار به بیماری قلبی مبتلا است یا نه بر اساس فشار خون، کلسترول و سن با استفاده از رگرسیون منطقی و دستهبندی بیماران به دستههای کم خطر، متوسط خطر و بالا خطر با استفاده از رگرسیون خطی.
ج) پیشبینی میزان مصرف سوخت بر اساس سرعت، دما و شیب جاده با استفاده از رگرسیون غیرخطی و دستهبندی سوخت به دستههای بنزین، گازوئیل و الکتریکی با استفاده از رگرسیون منطقی.
د) پیشبینی اینکه یک ایمیل اسپم است یا نه بر اساس محتوا، فرستنده و عنوان با استفاده از رگرسیون منطقی و دستهبندی ایمیلها به دستههای شخصی، اداری و تجاری با استفاده از رگرسیون خطی.
4)با توجه به تصویر زیر کدام گزینه صحیح است؟
الف) درk=3 وk=1ما overfit داشتیم و در k=9 ما underfit داشتیم.
ب) در k=1 وk=9 ما به ترتیب underfit و overfit داشتیم و در k=3 شرایط خوب است.
ج) در k=3 همه چیز خوب است و در k=1 شاهد overfit بودیم و در k=9 شاهد underfit هستم.
د) در هر سه تصویرoverfiti رخ داده است.