RseNet
Residual Network یکی از شبکههای عمیق معروف است. این شبکه در سال 2015 معرفی شد. دلیل موفقیت شبکهی رزنت (ResNet) این است که به ما امکان آموزش شبکههای عصبی بسیار عمیق با بیش از ۱۵۰ لایه را داد. قبل از رزنت (ResNet) شبکههای عصبی بسیار عمیق، به دلیل مشکل محوشدگی گرادیان (Vanishing Gradient)، دچار مشکل میشدند.
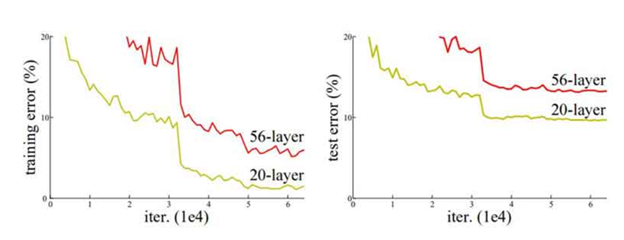
همانطور که در شکل فوق مشخص است، درصد خطا برای هر دو دادهی آزمایش و آموزش برای یک معماری 56 لایه بیشتر از یک شبکه 20 لایه است. این نشان میدهد که اضافه کردن لایههای بیشتر در شبکه همیشه به معنای بهتر شدن عملکرد آن نیست بلکه ممکن است عملکرد آن را تخریب کند. علت اینکه با عمیقتر شدن شبکه، عملکرد آن ضعیف میشود را میتوان در عوامل متعددی جستجو کرد مانند تابع بهینه سازی، وزن دهی اولیه شبکه و مهمتر از همه مسئلهی gradient vanishing.
طی سالها محققان به ایجاد شبکههای عصبی عمیقتر (افزودن لایههای بیشتر) برای حل و بهبود کارهای پیچیدهای مانند طبقه بندی و شناسایی تصاویر تمایل پیدا کردهاند، اما همانطور که دیدیم، با افزودن لایههای بیشتری به شبکهی عصبی، آموزش آنها دشوار میشود و دقت عملکرد شبکه شروع به کاهش میکند. اینجاست که ResNet به کمکمان میآید و به حل این مشکل کمک میکند.
اتصالات میانبر در ResNet
اتصالات میانبر (Skip Connections) یا اتصالات اضافی (Residual Connections) راهحلی بود که شبکه رزنت (ResNet) برای حل مشکل شبکههای عمیق ارائه کرد. در شکل زیر یک بلاک اضافی (Residual Block) را مشاهده میکنیم. همانطور که در تصویر مشخص است، فرق این شبکه با شبکههای معمولی این است که یک اتصال میانبر دارد که از یک یا چند لایه عبور میکند و آنها را در نظر نمیگیرد؛ درواقع بهنوعی میانبر میزند و یک لایه را به لایهي دورتر متصل میکند.
لایههایی که پشت هم قرار میدهیم ذاتا وظیفه ایجاد یک تابع غیرخطی را دارند و ایجاد یک نگاشت خطی از آنها بسیار مشکل است . بلوکهای سازندهای تحت عنوان Residual Block معرفی شدند که توانایی ایجاد یک نگاشت خطی در خروجی را دارند. به تصویر زیر دقت کنید. تابع F(x) مثل همیشه در حال ایجاد ویژگی غیرخطی است. در اینجا با اضافه کردن یک Skip Connection به خروجی لایه دوم که وظیفه دارد F(x) را با x جمع کند، میتوان به یک نتیجه بهتر رسید. دقت شود تابع فعالیت ReLU پس از جمع اعمال خواهد شد.
پس با این ساختار جدید بهینهساز شبکه توانایی این را دارد که در صورت نیاز F(x) را برابر صفر کند و صرفا ورودی بلاک را به تابع فعالیت وارد کند. با این حساب اگر لایههای بیشتری به مدل اضافه شود 2 حالت پیش میآید:
1. این لایهها ویژگی جدید به مدل اضافه نمیکنند و F(x) آنها برابر صفر در نظر گرفته میشود تا باعث کاهش دقت شبکه نشوند.
2. این لایهها ویژگی جدیدی از دیتا پیدا کرده و بهینهساز نگاشت F(x) را ایجاد کرده تا با نگاشت همانی جمع کند و به لایههای دیگر تزریق کند.

معماری ResNet
ResNet، مخفف شبکه باقیمانده، یک نوع معماری شبکه عصبی عمیق است و از یک شبکهی ۳۴ لایهای ساده استفاده میکند که از معماری VGGNet الهام گرفته شده و به این شبکهی اتصالات میانبر اضافه شده است. این شکل نمایی از معماری ResNet را نشان میدهد.
معماریهای ResNet به طور معمول از بسیاری از بلوکهای باقیمانده که روی هم قرار داده شدهاند تشکیل شدهاند. مقاله اصلی ResNet چند نسخه از ResNet با تعداد لایههای مختلف (مانند ResNet-18، ResNet-34، ResNet-50 و غیره) را معرفی کرد و اینها به طور گسترده در وظایف مختلف بینایی کامپیوتری مانند طبقهبندی تصویر، تشخیص اشیاء و تقسیم بندی استفاده شدهاند.
ResNet به عنوان یک معماری محبوب و تأثیرگذار در زمینه یادگیری عمیق به دلیل قابلیت آموزش شبکههای بسیار عمیق به طور مؤثر و دستیافتن به عملکرد برتر در وظایف مختلف شناخته شده است.
پس از اولین معماری مبتنی بر CNN (AlexNet) که برنده مسابقه ImageNet 2012 شد، هر معماری برنده بعدی از لایه های بیشتری در یک شبکه عصبی عمیق استفاده می کند تا میزان خطا را کاهش دهد. این برای تعداد لایههای کمتری کار میکند، اما وقتی تعداد لایهها را افزایش میدهیم، یک مشکل رایج در یادگیری عمیق مرتبط با آن وجود دارد که گرادیان ناپدید/انفجار نامیده میشود. این باعث می شود که گرادیان 0 یا خیلی بزرگ شود. بنابراین وقتی تعداد لایه ها را افزایش می دهیم، میزان خطای آموزش و آزمون نیز افزایش می یابد.
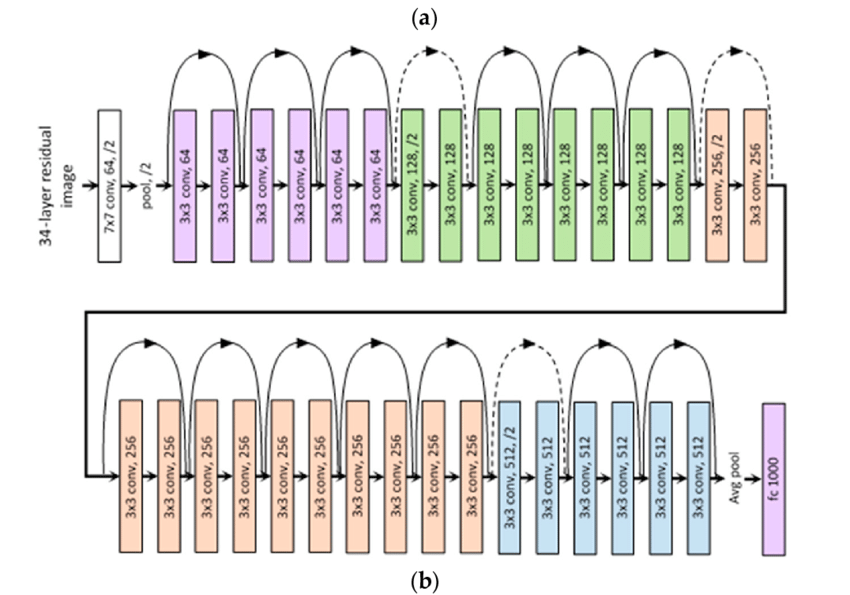
شبکه ResNet نسخههای ۵۰، ۱۰۱ و ۱۵۲ لایه نیز دارد. هر قدر شبکه عمیقتر میشود، پیچیدگی زمانی نیز افزایش مییابد. برای حل این مشکل راهحلی ارائه شد که در بخش بعد میبینیم.
طراحی گلوگاه (Bottleneck Design)
همانطور که در بخش قبل توضیح دادیم، در صورت اضافهشدن لایههای بیشتر به شبکه، پیچیدگی زمانی افزایش مییابد که برای حل آن یک گلوگاه (Bottleneck) طراحی شده است.
در بلاکهای رزنت ما دو فرم داریم که بصورت زیر هست :

تفاوت آنها در استفاده از bottleneck هست که در بلاک سمت راستی استفاده شده برای کاهش سربار پردازشی و در بلاک سمت چپی استفاده نشده است. در معماری های خیلی عمیق برای کاهش سربار پردازشی از این شیوه استفاده میشود .
راهحل به این شکل بود که به اول و آخر هر لایه کانولوشن یک لایهی کانولوشن ۱×۱ اضافه شد. تکنیک کانولوشن ۱×۱ در شبکهی گوگلنت (GoogleNet) استفاده شده است و نشان میدهد کانولوشنهای ۱×۱ میتوانند تعداد پارامترهای شبکه را کاهش دهند و درعینحال کارایی آن را کاهش ندهند. با طراحی این گلوگاه رزنت ۳۴ لایه به ۵۰، ۱۱۰ و ۱۵۲ نیز افزایش یافت.
سوالات:
1. چرا مشکل محوشدگی گرادیان (Vanishing Gradient) با افزایش تعداد لایهها در شبکههای عصبی عمیق به وجود میآید؟
الف) به دلیل کمبود دادههای آموزش
ب) به دلیل اضافه شدن لایههای بیشتر
ج) به دلیل تابع بهینه سازی
د) به دلیل تغییرات در وزن دهی اولیه شبکه
2. چرا اضافه کردن لایههای بیشتر به شبکههای عصبی ممکن است عملکرد آنها را تخریب کند؟
الف) به دلیل کاهش پیچیدگی زمانی
ب) به دلیل افزایش پارامترها
ج) به دلیل تغییرات در تابع هزینه
د) به دلیل تغییرات در وزندهی اولیه شبکه
3. چرا تکنیک کانولوشن ۱×۱ در شبکههای عصبی استفاده میشود؟
الف) برای افزایش پارامترها
ب) برای کاهش پارامترها
ج) برای افزایش پیچیدگی زمانی
د) برای افزایش مشکل محوشدگی گرادیان
4. چرا گلوگاه (Bottleneck) در شبکههای عصبی طراحی میشود؟
الف) برای افزایش پارامترها
ب) برای کاهش پارامترها
ج) برای افزایش پیچیدگی زمانی
د) برای حل مشکل محوشدگی گرادیان
5. چرا تکنیک کانولوشن ۱×۱ در رزنت (ResNet) استفاده میشود؟
الف) برای افزایش پارامترها
ب) برای کاهش پارامترها
ج) برای افزایش پیچیدگی زمانی
د) برای حل مشکل محوشدگی گرادیان
#ResNet
