مقدمات تصویر و طبقه بندی نزدیک ترین همسایه

/*! elementor - v3.17.0 - 08-11-2023 */ .elementor-heading-title{padding:0;margin:0;line-height:1}.elementor-widget-heading .elementor-heading-title[class*=elementor-size-]>a{color:inherit;font-size:inherit;line-height:inherit}.elementor-widget-heading .elementor-heading-title.elementor-size-small{font-size:15px}.elementor-widget-heading .elementor-heading-title.elementor-size-medium{font-size:19px}.elementor-widget-heading .elementor-heading-title.elementor-size-large{font-size:29px}.elementor-widget-heading .elementor-heading-title.elementor-size-xl{font-size:39px}.elementor-widget-heading .elementor-heading-title.elementor-size-xxl{font-size:59px}
تصویر چیست؟
یک تصویر نمایش بصری چیزی است، در حالی که یک تصویر دیجیتال یک نمایش دودویی از داده های بصری است. تصویر دیجیتال یک تصویر است که با استفاده از داده های عددی و رایانه ها ایجاد شده است. یک تصویر دیجیتال از تعدادی تکه های کوچک رنگی تشکیل شده است. این نقاط پیکسل نامیده می شوند. هنگامی که پیکسل ها بر روی مانیتور نمایش داده می شوند، به قدری کوچک هستند که تاثیر جمعی روی چشم انسان یک الگوی پیوسته از رنگ هاست. کامپیوتر ها رنگ یک پیکسل را با استفاده از ترفندی که مدت ها برای هنرمندان شناخته شده بود نشان می دهند: ترکیب رنگ های اصلی و برای هر رنگ عددی بین 0 و 255- لود تصویر از دیسک و ذخیره داده های عددی مربوط به تصویر با استفاده از کتابخانه های مورد نیاز
import numpy as npdata = np.array(plt.imread('./images/sign.jpg'))
- ویرایش داده تصویری
data[:, :, 1] = 0
data[:, :, 2] = 0
plt.imshow(data)
plt.show()
/*! elementor - v3.17.0 - 08-11-2023 */ .elementor-widget-image{text-align:center}.elementor-widget-image a{display:inline-block}.elementor-widget-image a img[src$=".svg"]{width:48px}.elementor-widget-image img{vertical-align:middle;display:inline-block}
- تصاویر سطح خاکستری
img = plt.imread('./images/t-shirt.jpg')
tshirt = rgb2gray(img)
tshirt[200:400, 300:400]=0
plt.imshow(tshirt, cmap = plt.get_cmap('gray'))
plt.show()

معرفی مجموعه داده هدی و استفاده از الگوریتم های یادگیری ماشین
مجموعه ارقام دستنویس هدی که اولین مجموعهی بزرگ ارقام دستنویس فارسی است، مشتمل بر ۱۰۲۳۵۳ نمونه دستنوشته سیاه سفید است. این مجموعه طی انجام یک پروژهی کارشناسی ارشد درباره بازشناسی فرمهای دستنویس تهیه شده است. داده های این مجموعه از حدود ۱۲۰۰۰ فرم ثبت نام آزمون سراسری کارشناسی ارشد سال ۱۳۸۴ و آزمون کاردانی پیوستهی دانشگاه جامع علمی کاربردی سال ۱۳۸۳ استخراج شده است. این مجموعه داده در قالب فایل mat متلب منتشر شده است. در پایتون میتوانیم آن را با کتابخانه scipy لود کنیم. dataset = io.loadmat('./dataset/Data_hoda_full.mat') در این مجموعه داده 60000 داده تصادفی وجود دارد. برای آزمایشاتمان 1000 دادهی اول را برای آموزش و 200 دادهی بعدی را برای آزمون انتخاب میکنیم. **داده های آزمون نباید قبلا در داده های آموزشی دیده شده باشند.** #test and training set X_train_orginal = np.squeeze(dataset['Data'][:1000]) y_train = np.squeeze(dataset['labels'][:1000]) X_test_original = np.squeeze(dataset['Data'][1000:1200]) y_test = np.squeeze(dataset['labels'][1000:1200]) تغییر اندازه تصاویر مجموعه داده اندازه تصاویر مجموعه داده متفاوت است. تمام تصاویر را به یک اندازه مشخص (5*5) تغییر اندازه میدهیم. X_train_5by_5 = [cv2.resize(img, dsize=(5, 5)) for img in X_train_orginal] X_test_5by_5 = [cv2.resize(img, dsize=(5, 5)) for img in X_test_original] image = X_train_5by5[1] plt.imshow(image, cmap='gray') plt.show() تغییر شکل مجموعه داده
تغییر شکل مجموعه داده
X_train = np.reshape(X_train_5by5, [-1,25]) X_test = np.reshape(X_test_5by_5, [-1,25])X_train.shape
(1000, 25)
طبقه بندی نزدیکترین همسایه و K نزدیکترین همسایه
الگوریتم K-Nearest Neighbors (KNN) یک الگوریتم یادگیری ماشینی است که برای مسائل دستهبندی و پیشبینی استفاده میشود. این الگوریتم به ازای هر نقطه از دادهها، K نزدیکترین نقاط دیگر را پیدا میکند و با توجه به برچسب آنها، برچسب نقطه مورد نظر را پیشبینی میکند. لود کتابخانههای مورد استفادهfrom sklearn.neighbors import KNeighborsClassifier import matplotlib.pyplot as plt import numpy as np from dataset import load_hodaایجاد طبقه بند knn
neigh = KNeighborsClassifier(n_neighbors=3) neigh.fit(X_train, y_train)
sample = 24
X = [X_test[sample]]
predicted_class = neigh.predict(X)
print ("Sample {} is a {}, and you prediction is: {}.".format(sample, y_test[sample], predicted_class[0]))
Sample 24 is a 9, and you prediction is: 9.
print(neigh.predict_proba(X))
[[0. 0. 0. 0. 0. 0. 0.33333333 0. 0. 0.66666667]] با توجه به احتمالات بالا کلاس برنده کلاس هفت خواهد بود.
pred_classes = neigh.predict(X_test) pred_classes
array([7, 2, 3, 1, 5, 5, 4, 7, 3, 2, 0, 8, 8, 0, 3, 9, 3, 6, 7, 4, 0, 3,
6, 3, 9, 2, 7, 5, 2, 9, 7, 5, 5, 8, 9, 6, 5, 1, 4, 8, 8, 4, 2, 7,
1, 2, 7, 9, 0, 3, 7, 4, 7, 5, 2, 9, 8, 2, 9, 8, 8, 6, 6, 6, 7, 6,
2, 4, 1, 4, 4, 5, 9, 1, 8, 2, 0, 5, 6, 2, 4, 3, 2, 7, 7, 7, 7, 1,
8, 1, 7, 8, 7, 7, 8, 9, 3, 2, 3, 1, 0, 2, 9, 7, 3, 5, 5, 0, 0, 2,
6, 7, 9, 3, 9, 9, 8, 7, 9, 2, 5, 2, 5, 5, 9, 6, 9, 2, 0, 3, 7, 6,
5, 2, 9, 0, 4, 1, 8, 2, 2, 3, 0, 2, 9, 3, 8, 6, 7, 0, 9, 9, 0, 7,
6, 1, 4, 7, 9, 3, 7, 0, 7, 1, 9, 4, 7, 3, 4, 1, 5, 6, 7, 9, 1, 3,
5, 4, 5, 7, 4, 1, 3, 3, 1, 2, 5, 3, 8, 9, 6, 7, 7, 2, 3, 0, 1, 4,
9, 5], dtype=uint8)
ارزیابی
np.mean(pred_classes == y_test)
0.96
acc = neigh.score(X_test, y_test)
print ("Accuracy is %.2f %%" %(acc*100))
Accuracy is 96.00 %شما اگه به یک بیمارستان بروید و یک آزمایش بالینی انجام بدهید و نتایج این آزمایش را چندین نفر بررسی کنند، برای مثال یک نفر پزشک متخصص، یک نفر پزشک عمومی و یک نفر خدماتی. و مطمئنا هر کدام براساس دانشی که دارد تصمیم متفاوتی میتواند بگیرد. حال شما میخواهید بدانید که نتیجه آزمایش شما مثبت بود یا منفی؟ اگر بخواهید براساس نظر این سه نفر تصمیم بگیرید که نتیجه آزمایش مثبت بوده یا منفی، به نظر هر کدام از این افراد چه درجه اهمیتی میدهید؟ مطمئنا شما هم به این ترتیب به نظرات درجه اهمیت خواهید داد: پزشک متخصص(بالا)، پزشک عمومی( متوسط) و خدماتی(پایین)
در knn هم باید موقع تصمیم گیری از نظر همسایه ها براساس درجه اهمیتی که دارند استفاده کنیم. به عبارتی باید در ابتدا به تک تک k تا نزدیکترین همسایه براساس فاصلهای که به نمونه ی جدید دارند یک وزن بدهیم، هر چقدر نزدیکتر وزن بیشتر، و هر چقدر دورتر وزن کمتر!
به الگوریتمی که به صورت وزندار رای گیری انجام میدهد weighted knn یا به اختصار wknn می گوییم.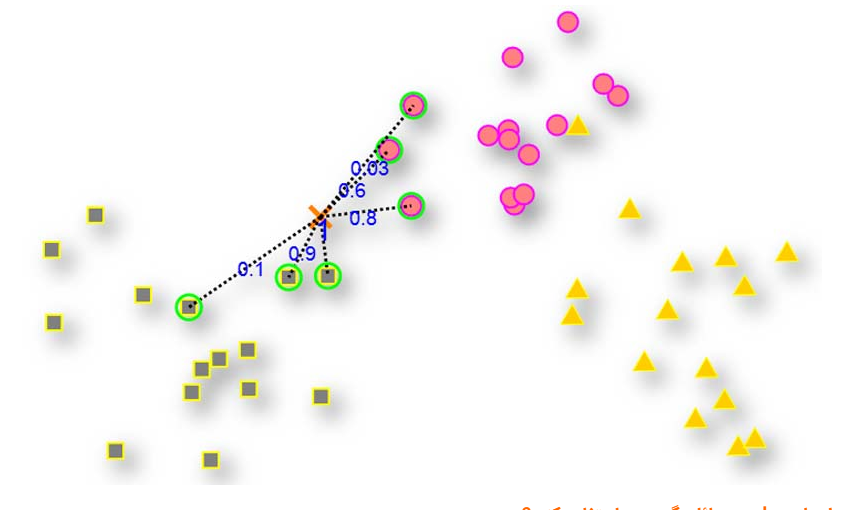 سوالات چند گزینه ای
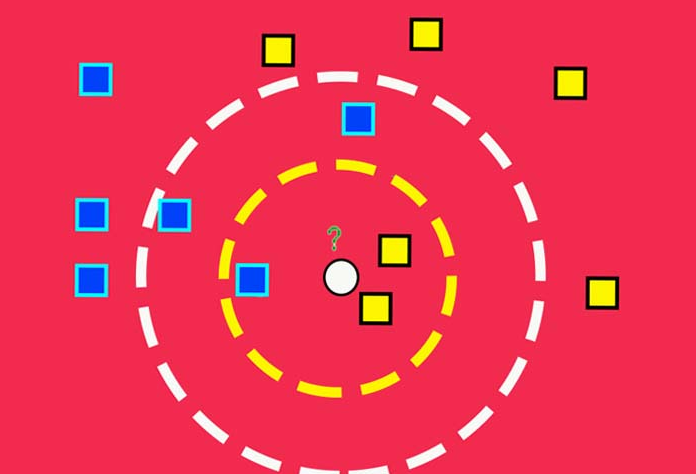
اگر بدانیم لیبل واقعی نمونه سفید آبی است مقدار k را چه چیزی در نظر بگیریم؟
الف) 3 ب) 5 ج)تفاوتی ندارد د)هیچ کدام نمی توانند لیبل واقعی را درست بیان کنند.
سوالات چند گزینه ای
اگر بدانیم لیبل واقعی نمونه سفید آبی است مقدار k را چه چیزی در نظر بگیریم؟
الف) 3 ب) 5 ج)تفاوتی ندارد د)هیچ کدام نمی توانند لیبل واقعی را درست بیان کنند.
 مهم ترین مشکل طبقه بند knn چیست؟
الف)از نظر همسایه ها به طور یکسان استفاده می کند
ب) نسبت به k بسیار است.
ج) هر دو مورد.
موقعیتی را در نظر بگیرید که تعداد داده های پرت بالاست، کدام یک را مناسب می دانید؟
الف) استفاده از k=1
ب) استفاده از k هایی با مقدار بالاتر
تاثیر وزن دهی به نزدیکی نقلط در محاسبه پیش بینی:
الف) وزن دهی یکسان به همه نقاط
ب) وزن دهی بر اساس فاصله
ج) بدون وزن دهی
چگونه می توان از مشکل بیش برازش در knn جلوگیری می کنید؟
الف) انتخاب مناسب k
ب) استفاده از وزن دهی مناسب
ج) هر دو گزینه
مهم ترین مشکل طبقه بند knn چیست؟
الف)از نظر همسایه ها به طور یکسان استفاده می کند
ب) نسبت به k بسیار است.
ج) هر دو مورد.
موقعیتی را در نظر بگیرید که تعداد داده های پرت بالاست، کدام یک را مناسب می دانید؟
الف) استفاده از k=1
ب) استفاده از k هایی با مقدار بالاتر
تاثیر وزن دهی به نزدیکی نقلط در محاسبه پیش بینی:
الف) وزن دهی یکسان به همه نقاط
ب) وزن دهی بر اساس فاصله
ج) بدون وزن دهی
چگونه می توان از مشکل بیش برازش در knn جلوگیری می کنید؟
الف) انتخاب مناسب k
ب) استفاده از وزن دهی مناسب
ج) هر دو گزینه