One by one convolution
می دانیم کانولوشن یک فیلتری دارد که در ماتریس حرکت داده می شد و هر پیکسل را با همسایه های آن بر اساس وزن ها ترکیب می کرد و در خروجی قرار می داد.
حالا اگر کرنل ما یک در یک باشد چه می شود؟
شبیه ضرب ماتریس در عدد ثابت می شود و دیگر در بدست آوردن فیچرهای پیچیده تر به ما کمک نمی کند. ( یعنی نتیجه به صورت خطی می شود ولی ما برای بدست آوردن فیچرهای پیچیده تر به ترکیب غیر خطی پیکسل ها نیاز داریم. )
ولی ما وقتی از این فیلتر استفاده می کنیم یک عمق به اندازه عمق تصویر به فیلتر می دهیم و می گوییم که تمام فیچرهای درون آن یک نقطه را می خواهیم با هم ترکیب کنیم. (برای مثال وقتی در یک نقطه هم خط 45 درجه و هم خط منفی 45 درجه دیدم می شود ضربدر )
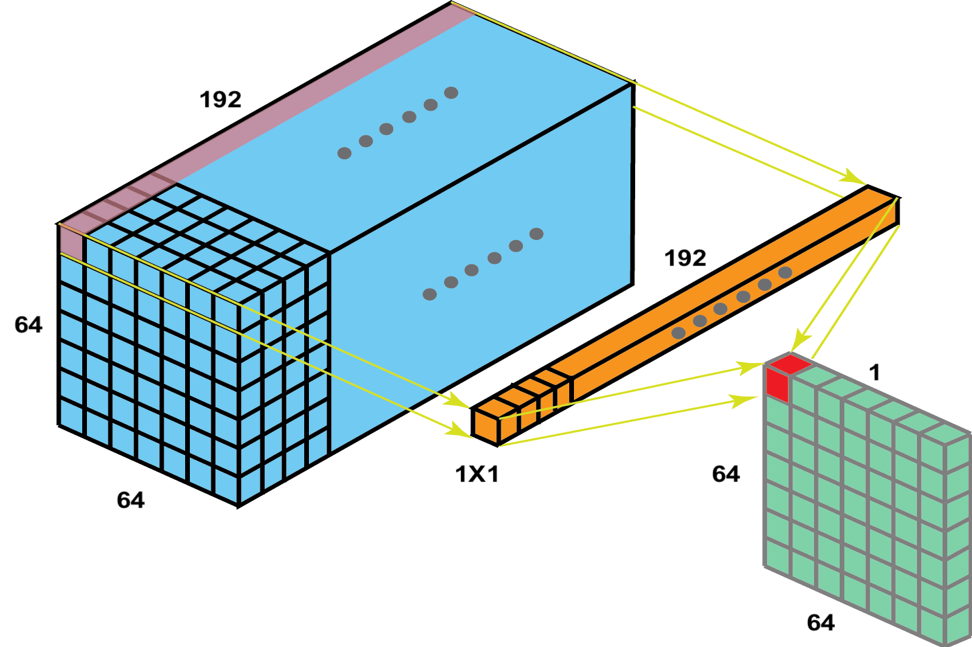
در نتیجه اگر بخواهیم deep information بزنیم و از فیلتر های عمق دار استفاده می کنیم. ولی اگر بخواهیم فقط عمق را قاطی کنیم از 1×CONV 1 استفاده می کنیم.
همچنین اگر خواستیم عمق را کم کنیم از کانولوشن یک در یک استفاده می کنیم.
اولین مقاله که از کانولوشن یک در یک استفاده کرده Inception است.
Inception (googlenet)
اسم inception را از روی فیلم inception برداشته اند که ایده اصلی این نوع شبکه را از روی آن برداشته شده و هدف اصلی آن ها عمیق تر شدن در شبکه است.
 ایده کلی مقاله :
ایده کلی مقاله :
اگر از لایه ای بخواهیم به لایه دیگری برویم که به صورت same کانولوشن بزنیم باز هم ابعداد همان می ماند و فقط عمق تغییر می کند.
فیلترهای ما می تواند ابعاد متفاوتی داشته باشند ولی در inception می گویید لازم نیست که تصمیم بگیریم ابعاد فیلتر را چند انتخاب کنیم و از همه فیلترهای یک در یک، سه در سه و پنج در پنج استفاده می کنیم و تمام نتایج را پشت هم قرار می دهیم و همین طور یه pooling هم میزنیم (pooling ابعاد را کوچک تر میکنه ولی ما با یک ضرب ماتریسی ساده ما مقادیر رندوم و خطی که خود شبکه مقادیر آن را بهینه می کنه ابعاد را به همان اندازه اولیه برمی گردانیم.)
ما با این روش اجازه می دهیم که خود شبکه ضریب هر کانولوشن رو پیدا کند و با توجه به اهمیت آن، به آن ها ضریب بدهد.
در نهایت ما یک تصویر 28 در 28 داریم که 256 کانال دارد که 64 تای آن از کانولوشن یک در یک، 128 تای آن کانولوشن سه در سه، 32 تای آن از کانولوشن پنج در پنج و 32 تای آن برای max pool است. این میزان ها با توجه به نظر خود ما هست که از نظر ما فیلتر با کدام ابعاد می تواند مفید تر باشد.

ما مجموع این فیلتر ها و پولینگ را می توانیم به صورت یک ماژول درنظر بگیریم و دیگه داخل آن را نبینیم و فقط بگوییم یک inception module بزن.
حتی ما می توانیم مدل خود را پیچیده تر یا چند لایه کنیم مانند مثال پایین که دو لایه دارد:
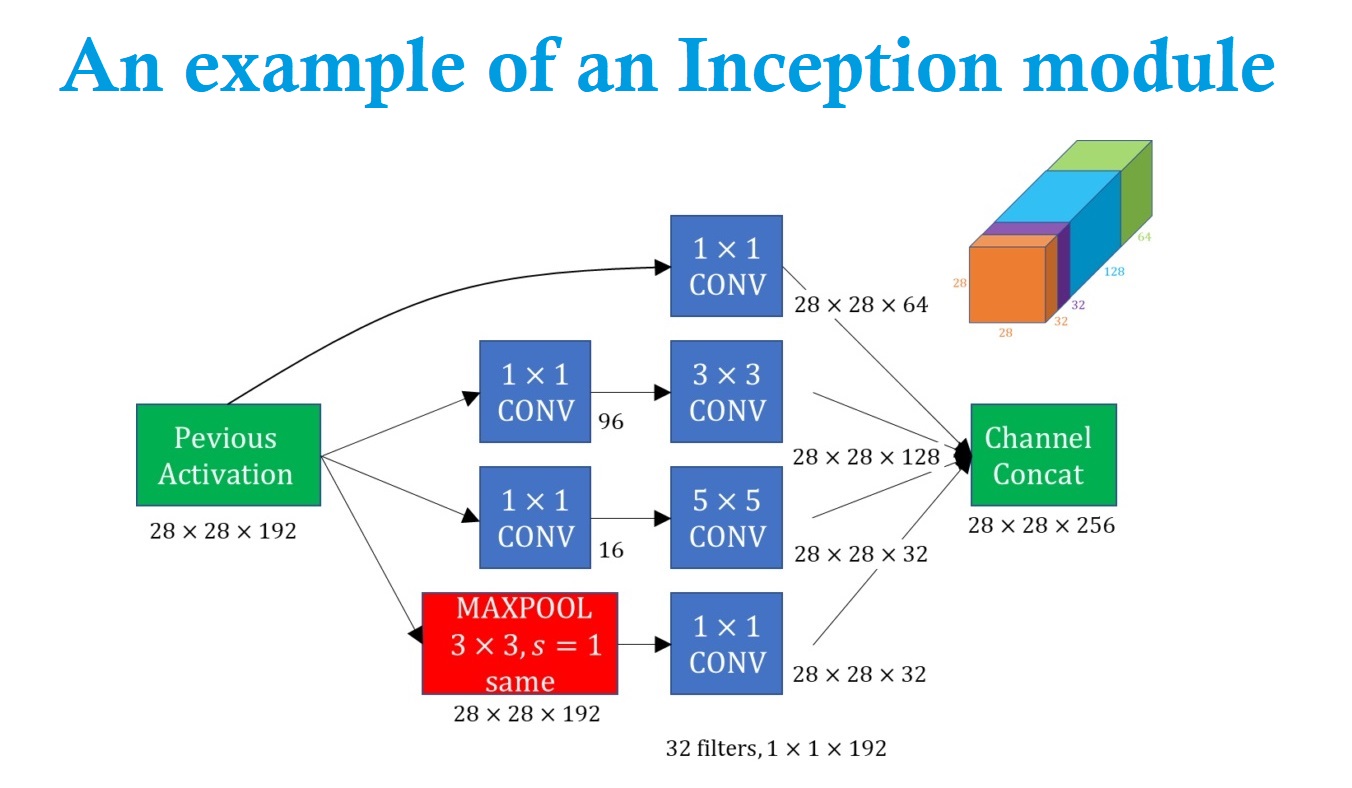
ما در این حالت شبکه را عمیق تر می کنیم زیرا یک ماژول اضافه می کنیم ولی دو لایه اضافه می شود. از Vanishing Gradient هم نمیترسیم زیرا از چند مسیر این بروزرسانی ضرایب انجام می شود.
در نهایت معماری آن ها مانند شکل زیر می شود :

اگر روی تصویر زوم کنیم مشاهده می کنیم که هر بخش از شبکه یک inception module است.
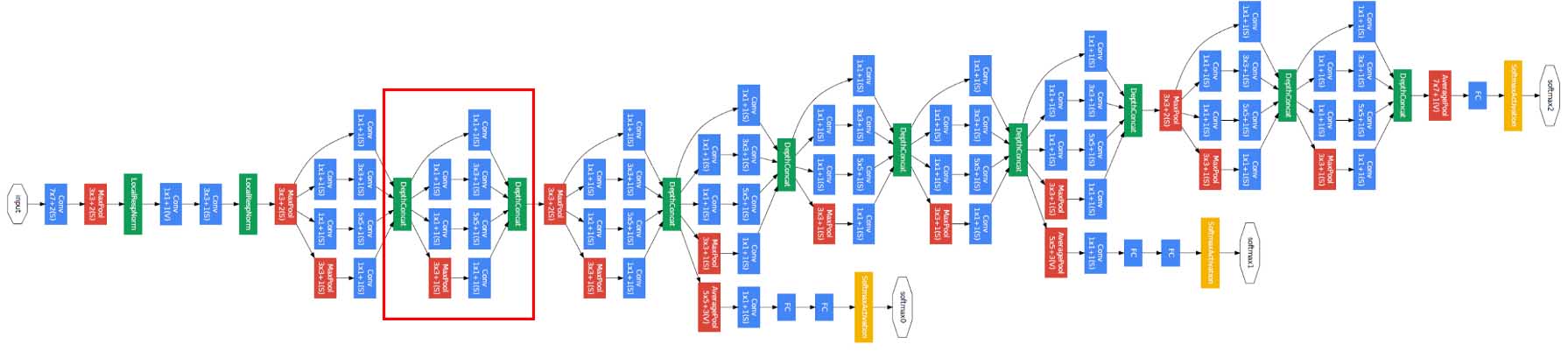
در هر بخش تصویر از زوم کنیم یک inception module می بینیم و مشاهده می کنیم که در وسط شبکه یک سری شاخه گرفته شده و یک سری softmax گذاشته شده ولی نتایج بدست آمده از این softmax ها برای ما اهمیت ندارد فقط به شبکه کمک می کند که شبکه عصبی بهتری ساخته شود یک جور به شبکه می فهماند که چه چیز هایی برای train لازم دارد. (البته یک ایده دیگر این بود که اگر دقت در اواسط شبکه اندازه نتیجه نهایی بود می توانیم از همان شبکه نصفه استفاده کنیم و باقی را دور بیاندازیم. ولی زیاد از این روش استقبال نشد.)
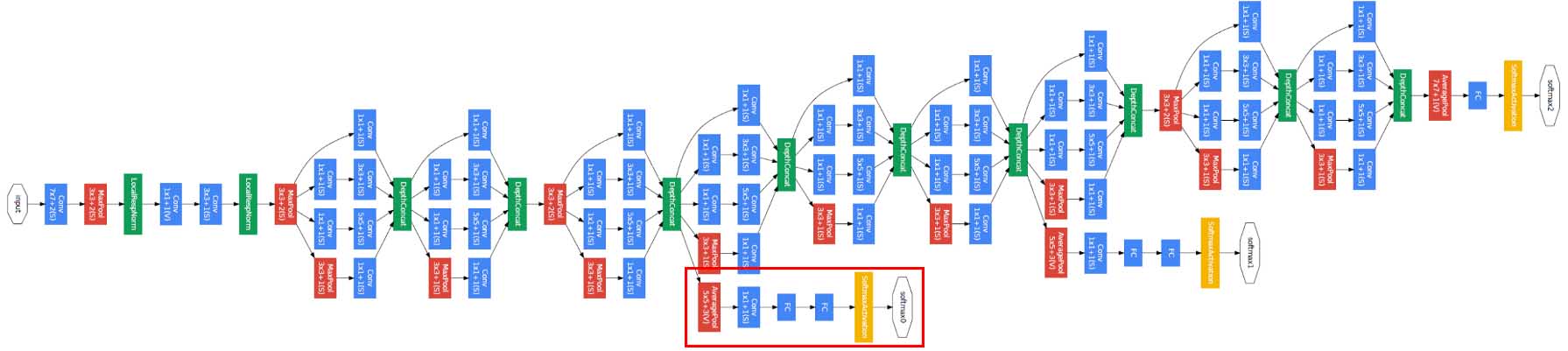
تعداد پارامتر ها در این نوع شبکه بشدت کاهش پیدا کرده با پنج میلیون پارامتر و دلیل آن هم حذف full connected است. ولی محاسبات آن بیشتر شده و خطا را نیز بسیار کم کرده است.
حالا می خواهیم بررسی کنیم که full connected ها چگونه حذف شده و لایه های آخر به چه صورت است :
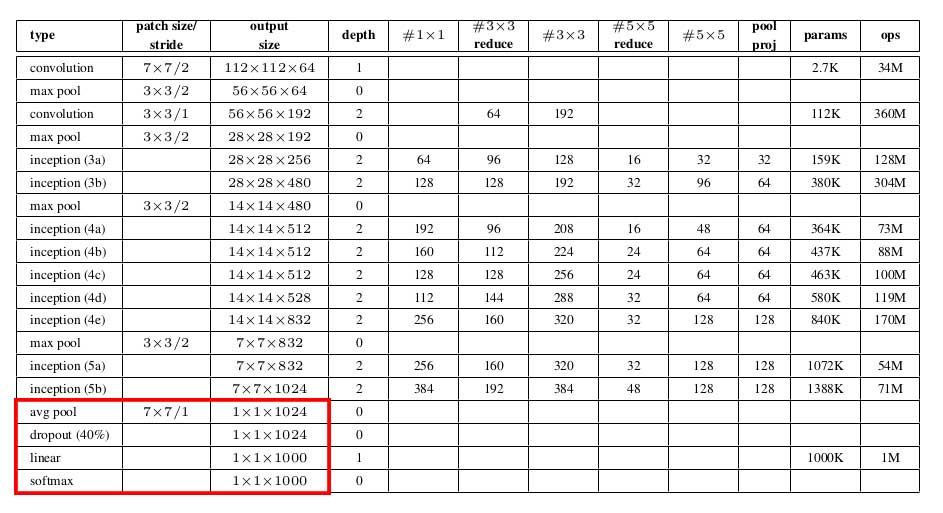
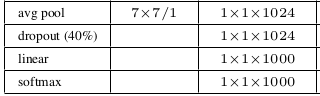
در آخر بعد یک inception module یک تصویر 7 در 7 در 1024 داریم که با یک pooling 7 in 7 که برای میانگین گیری است آن را به 1 در 1 در 1024 تبدیل کنیم و کل دیتا را میانگین بگیریم، که به آن global average pooling می گوییم بعد به تعداد کلاس ها فیلتر یک در یک می زنیم که برای مثال اینجا تعداد کلاس ها 1000 تا است در نتیجه 1000 کانولوشن یک در یک می زنیم و در آخر نیز یک softmax خواهیم داشت.
سوالات
ایده اصلی شبکه inception چه هست ؟
- عمیق تر کردن لایه ها
- اضافه کردن به تعداد نورون ها در هر لایه
- استفاده از کانولوشن same
- استفاده از full connected
در آخر به جای استفاده از full connected ها به ترتیب از چپ به راست از چه لایه هایی استفاده می کنیم ؟
- avg pool , linear
- convolution , avg pool
- convolution , linear
- linear , convolution
دلیل یک سری شاخه گرفته شده و یک سری softmax گذاشته شده در شبکه inception چیست ؟
- منحرف کردن شبکه از مسیر اصلی
- یک جور به شبکه می فهماند که چه چیز هایی برای train لازم دارد
- پیدا کردن میانبر برای شبکه
- دیدن نتایج در وسط شبکه
کدام یک درست است ؟
- ما می توانیم از شبکه های چند لایه برای ماژول استفاده کنیم.
- به دلیل اینکه تعداد لایه ها در شبکه inception زیاد است احتمال Vanishing Gradient هم زیاد است.
- لایه های آخر شبکه inception ، full connected است.
- 1×CONV 1 در شبکه inception استفاده نمی شود چون خطی است.
کدام یک درست است ؟
- تعداد پارامتر ها در شبکه inception کاهش پیدا کرده، ولی محاسبات آن کمتر شده
- تعداد پارامتر ها در شبکه inception افزایش پیدا کرده، ولی محاسبات آن کمتر شده
- تعداد پارامتر ها در شبکه inception افزایش پیدا کرده، ولی محاسبات آن بیشتر شده
- تعداد پارامتر ها در شبکه inception کاهش پیدا کرده، ولی محاسبات آن بیشتر شده
