label smoothing

label smoothing
label smoothing یک تکنیک اصلاحی است که به طور معمول در یادگیری ماشین، به ویژه در آموزش شبکههای عصبی برای تسک های طبقهبندی مورد استفاده قرار میگیرد. هدف اصلی از لیبل اسموتینگ جلوگیری از افزایش اطمینان زیاد مدل و اعتماد بیش از حد به دادههای آموزش است، که ممکن است منجر به اورفیتینگ شود. در تسک های سنتی طبقهبندی که پیشتر انجام میدادیم ، برچسبهای دادههای آموزش معمولاً به صورت انکد وان-هات (one-hot encoded) استفاده میشوند، به این معنا که برای هر نمونه، تنها یک کلاس به احتمال 1 اختصاص مییابد و سایر کلاسها به احتمال 0 در نظر گرفته میشوند . label smoothing مقداری از عدم اطمینان را با انتقال بخشی از احتمالات کلاس واقعی به سایر کلاسها به مدل میافزاید.یعنی به جای اختصاص احتمال 1 به کلاس واقعی و 0 به سایر کلاسها، label smoothing ممکن است به عنوان مثال به کلاس واقعی احتمال 0.9 اختصاص دهد و مابقی 0.1 را در سایر کلاسها توزیع کند. لیبلهای اسموت شده کمک میکنند تا مدل از پراکندگی زیاد اطمینان که ممکن است منجر به اورفیتینگ شود، جلوگیری کند. این به ویژه در شرایطی کارآمد است که دادههای آموزش ممکن است حاوی برچسبهای نویزی یا نادرست باشند. این تکنیک بهبود عملکرد کلی و کاهش اورفیتینگ در وظایف مختلف یادگیری ماشین، به ویژه در حوزه یادگیری عمیق، اثبات شده است. به عنوان مثال ، به شکل زیر دقت کنید : اگر با استفاده از انکودینگ وان - هات (one-hot encoded) لیبل گذاری کنیم ؛ لیبل ها به شکل زیر خواهند شد ، به این منزله که عدد مشاهده شده در تصویر متعلق به کلاس هفتم ( یعنی عدد 7 ) است.
اگر با استفاده از انکودینگ وان - هات (one-hot encoded) لیبل گذاری کنیم ؛ لیبل ها به شکل زیر خواهند شد ، به این منزله که عدد مشاهده شده در تصویر متعلق به کلاس هفتم ( یعنی عدد 7 ) است.
[ 0.0 ، 0.0 ، 1.0 ، 0.0 ، 0.0 ، 0.0 ، 0.0 ، 0.0 ، 0.0 ، 0.0 ]
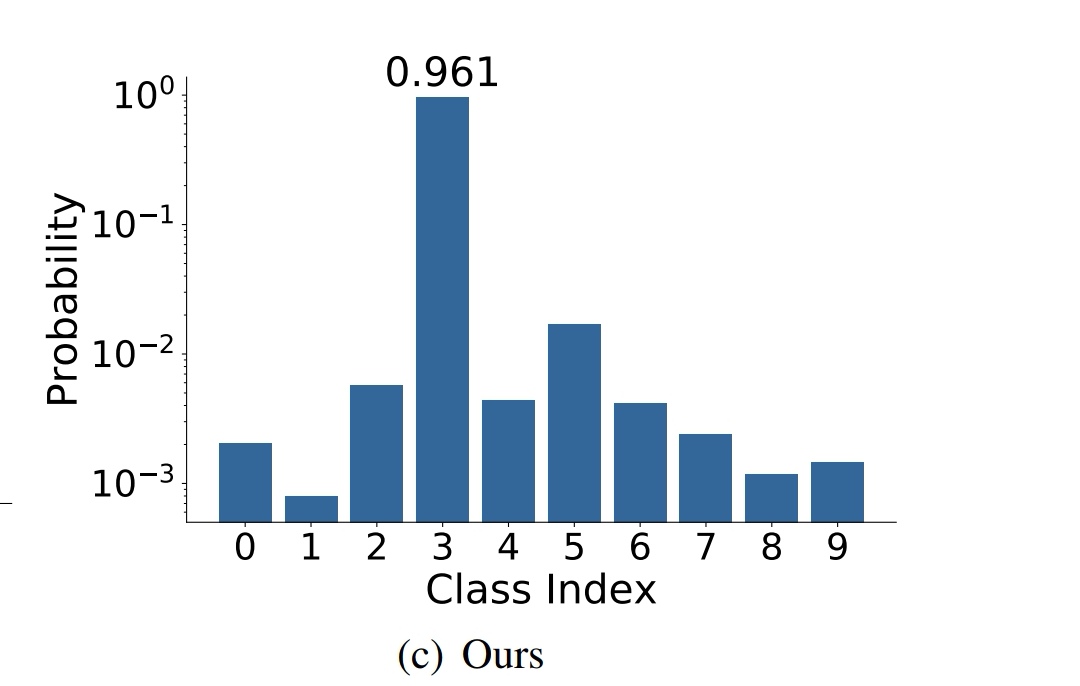
اما اگر بخواهیم تخصیص لیبل ها را بر اساس label smooth انجام دهیم ، بردار لیبل ها به شکل زیر خواهد بود:[ 0.01 0.01 0.91 0.01 0.01 0.01 0.01 0.01 0.01 0.01 ]
فرمول تولید لیبل های اسموت شده :
Smoothed Label = (1 - ϵ ) * True Label + ϵ / (Number of Classes) * ( 1 for other classes)
در اینجا: - (ϵ) یک پارامتر (معمولاً بین 0.1 و 0.2) است که مشخص میکند چقدر اطمینان به مدل اضافه شود. - true label : برچسب واقعی است که به طور اصلی به یک کلاس اختصاص مییابد. - 1for other clasees : به احتمال مساوی برای سایر کلاسها اشاره دارد. با اعمال این فرمول، مقدار احتمال به کلاس واقعی کاهش مییابد و مقداری از احتمال به سایر کلاسها توزیع میشود. این کمیتی از عدم اطمینان به مدل افزوده و از احتمالات دادههای آموزش برخوردار میشود.روش های اسموت کردن :
1- از طریق تعریف یک تابع ، مثل تابع زیر لیبل ها را smooth میکنیم :
:def smooth_labels(labels, factor=0.1)
# smooth the labels
labels *= (1 - factor)
labels += (factor / labels.shape[1])
# returned the smoothed labels
return labels
ارگومان های ورودی این تابع ، بردار لیبل( وان-هات شده) و یک متغیر فاکتور است که لیبل ها را بر اساس آن اسموت میکنیم.
2- استفاده از TensorFlow/Keras
در این روش نیازی به تعریف یک تابع جدید نیست و با استفاده از دستورات از پیش آماده شده ی TensorFlow/Keras، برپسب ها را اسموت میکنیم ؛ فقط کافی است از کلاس زیر با پارامتر label-smothiong استفاده کنیم :CategoricalCrossentropy(label_smoothing=0.1)
نتایج استفاده از label smoothing
نتایج استفاده از label smoothing با tensorflow و keras که به دقت 90 درصد رسیده و ولیدیشن لاس به شکل قابل توجهی کمتر از لاس مربوط به دیتا های اموزشی است. جهت مشاهده ی کد های مربوط به این مثال اینجا کلیک کنید.
مثال
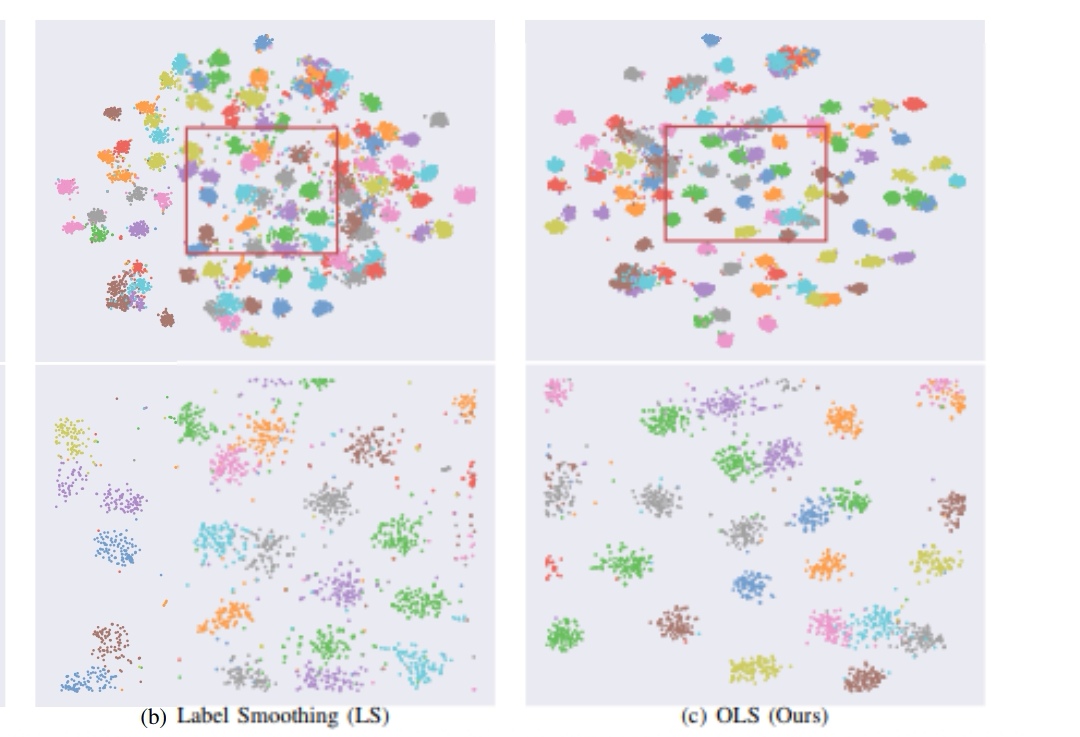
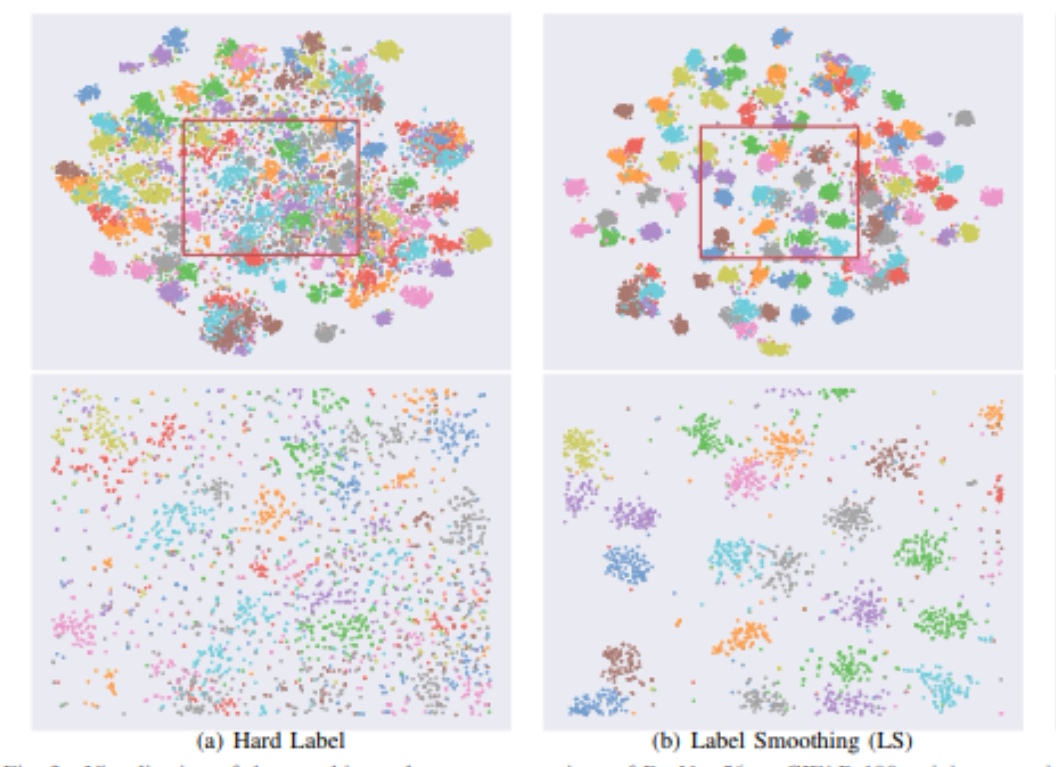
از دیتاست CIFAR-10 استفاده میکنیم و پیاده سازی شبکه با برچسب های smooth و بدون آن، یعنی به شکل one-hot شده را بررسی میکنیم. دیتاست CIFAR-10 توسط موسسه تحقیقات پیشرفته کانادا (CIFAR) منتشر شد و بخشی از محبوبیت خود را از همکاری جفری هینتون و دستیاران او به دست آورده است. دیتاست CIFAR-10 دربرگیرنده ۶۰۰۰۰ تصویر رنگی ۳۲x32px در ده طبقه گوناگون است و برای آموزش و آزمایش انواع مدل تشخیص اشیاء استفاده میشود. تفاوت برچسب one-hot شده و smooth شده در تصویر زیر مشخص شده است.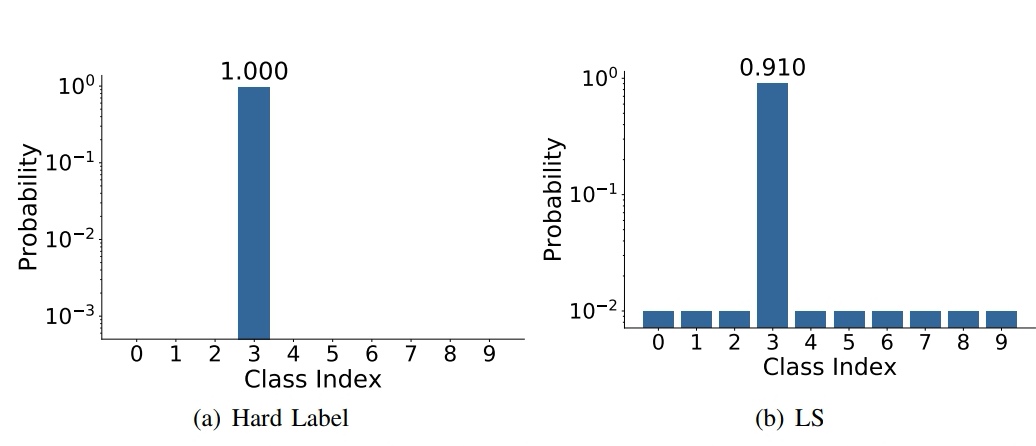 تصویر زیر نتیجهی پیاده سازی با برچسب های smooth شده و برچسب های one-hot شده را نشان میدهد :
تصویر زیر نتیجهی پیاده سازی با برچسب های smooth شده و برچسب های one-hot شده را نشان میدهد :
مقاله
Delving Deep into Label Smoothing
Chang-Bin Zhang, Peng-Tao Jian, Qibin Hou, Yunchao Wei, Qi Han, Zhen Li, and Ming-Ming Cheng روش دیگری که برای برجسب زدن در این مقاله پیشنهاد شده، روش online label smoothing است که بوسیله ی ایجاد تغییرات در محاسبه ی برچسب هر کلاس، به دقت بیشتری در تمییز کلاس ها رسیده است.