GAP : Global Average Pooling


مقدمه : pooling و انواع رایج آن
در CNNs، لایههای pooling معمولاً برای کاهش ابعاد فضایی نقشههای ویژگی ورودی و به حداقل رساندن پیچیدگی محاسباتی و تعداد پارامترهای شبکه استفاده میشوند. متداولترین روشهای pooling شامل max pooling است که حداکثر مقدار در هر ناحیه pooling را میگیرد، و average pooling که میانگین مقدار را محاسبه میکند.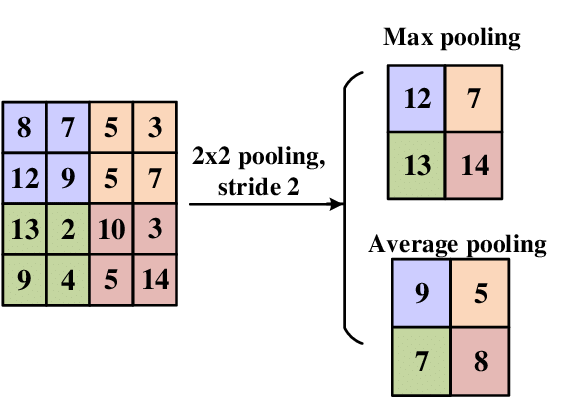
Global Average Pooling چیست؟
Global Average Pooling یا GAP یک عملیات ادغام است که معمولاً در شبکههای عصبی کانولوشنی (CNNs) استفاده میشود. این به منظور جایگزین کردن لایههای کاملاً متصل (fully connected layers) در معماریهای کلاسیک CNN طراحی شده است. ایده اصلی در Global Average Pooling این است که در آخرین لایه کانولوشنی میانگین هر نقشه ویژگی (feature map) را بگیرد وبرای هر نقشه ویژگی یک مقدار به دست میآید.کد اول : آشنایی با کارکرد Pooling
import numpy as np from tensorflow.keras.layers import MaxPooling2D, AveragePooling2D, GlobalAveragePooling2D my_img = np.array([[4.,7,3,1], [1,5,2,3], [6,3,9,2], [1,6,3,7]]) input_img = my_img[np.newaxis,:,:,np.newaxis] max_pool = MaxPooling2D(pool_size=(2, 2))(input_img) max_pool = max_pool.numpy() print(max_pool.shape) print(max_pool) avg_pool = AveragePooling2D(pool_size=(2, 2))(input_img) avg_pool = avg_pool.numpy() print(avg_pool.shape) print(avg_pool) GAP = GlobalAveragePooling2D()(input_img) GAP = GAP.numpy() print(GAP.shape) print(GAP) print(my_img.mean())
کاربرد GAP
Global Average Pooling معمولاً برای جایگزینی لایههای flatten و dense به کار میروند. مدلها معمولاً با لایههای کانولوشن به پایان میرسند و سپس لایه GAP اجرا میشود و هر نقشه ویژگی را به یک عدد تبدیل میکند. که این مقادیر به صورت مستقیم به لایه softmax برای طبقهبندی وارد میشوند. به عبارت دیگر، با محاسبه میانگین، اطلاعات فضایی (sptial information) به یک مقدار برای هر نقشه ویژگی کاهش مییابد.کد دوم : استفاده در لایه های شبکه عصبی
avg_pool_model = Sequential()
avg_pool_model.add(Conv2D(32, (3, 3), input_shape=INPUT_SHAPE))
avg_pool_model.add(Activation('relu'))
avg_pool_model.add(MaxPooling2D(pool_size=(2, 2)))
avg_pool_model.add(Conv2D(32, (3, 3), kernel_initializer = 'he_uniform'))
avg_pool_model.add(Activation('relu'))
avg_pool_model.add(MaxPooling2D(pool_size=(2, 2)))
avg_pool_model.add(Conv2D(64, (3, 3), kernel_initializer = 'he_uniform'))
avg_pool_model.add(GlobalAveragePooling2D())
#avg_pool_model.add(Flatten()) #No need for flattening anymore.
avg_pool_model.add(Dense(1))
avg_pool_model.add(Activation('sigmoid'))
مزایای Global Average Pooling
-
کاهش ابعاد
-
پیشگیری از Overfitting
-
حفظ اطلاعات مهم
-
سهولت در پیادهسازی
سوالات چهار گزینهای:
- کدوم لایه در مدل avg_pool_model برای جایگزینی لایههای flatten و dense استفاده میشود؟
- در مدل avg_pool_model، چه لایهای برای حفظ اطلاعات مهم در هر نقطه از تصویر استفاده شده است؟
- مقدار Global Average Pooling (GAP) چگونه به دست میآید؟
- کدام مورد از مزیت های Global Average Pooling (GAP) در شبکههای عصبی نیست؟